 Skip to Navigation
Skip to Navigation
Migrating data to RavenDB
An empty database is a sad sight to behold. It is worse than a car without a drop of gas. At least you can sell the car for it’s scrap metal value. An empty database is of no worth whatsoever. The first thing that you’ll encounter when you start RavenDB for the very first time is just that, an empty database. RavenDB has many features and bells and whistles galore, but it’s the data, your data, that make any database valuable.
There are two ways to get data into RavenDB. You can create brand new data inside RavenDB or bring your existing data from existing data stores. Projects that start from a clean slate do happen, but they tend to be rare. For the majority of the cases, you already have data that you want to migrate to RavenDB. Luckily, RavenDB makes it easy to pull data into it. There are four major ways to do so:
- Import data from another RavenDB instance. This can be a one time or an ongoing effort.
- Import data from a relational database (MS SQL Server, Oracle, PostgreSQL, MySQL, MariaDB, etc).
- Import data from a non-relational database, such as MongoDB or CosmosDB.
- Import data from a CSV file.
Table of contents
Getting data from another RavenDB instance
If you already have your data inside another RavenDB instance, there are several ways you can get the data into your new RavenDB database:
- External replication – Full sync of the source database state to its destination. This is an ongoing effort and will keep the destination always in sync with the source database. You can read more about external replication in the documentation.
- ETL Process – Sync some of the data in the source to the destination, potentially transforming it along the way. This is an ongoing effort and the destination will reflect any changes from the source. You can read more about RavenDB ETL in the documentation.
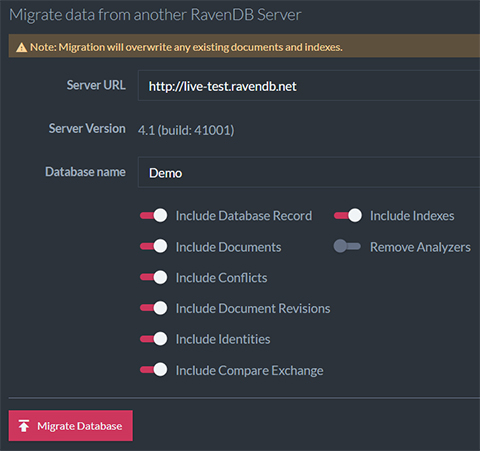
- Migration from RavenDB – a one-time operation getting all the data from a source database to your new instance. You can see how this looks like on this image. You can read more about importing from RavenDB in the documentation.
External replication is a good idea if you want to do more than just import the data. You want to have a full sync between the source and destination.
Full sync is useful if you need an offsite clone of your data, you want a separate instance to run large scale computation, or you just need a copy of production so your UAT environment will feel real.
The RavenDB ETL process, on the other hand, is more involved. Instead of simply syncing a full copy of the data, you get to choose what will be sent from the source to the destination. This choice includes what collections (and what documents in these collections) to send as well as the ability to transform the data through the process. A common use case for this feature is to have a copy of your data with all the personally identifying details stripped.
Finally, if you just want to get the data from another RavenDB database, you can simply point your new RavenDB instance to the database and it will take care of fetching everything. This is by far the simplest option.
Of course, RavenDB to RavenDB migrations are the easiest. But what happens when we don’t have the same type of database on both ends?
Migrating data from a SQL database to RavenDB
If this is your first time using RavenDB, your data will most likely be stored inside a relational database of some kind (MS SQL Server, MySQL, etc). RavenDB has native support for pulling the data from such databases and inserting it into RavenDB in a document format.
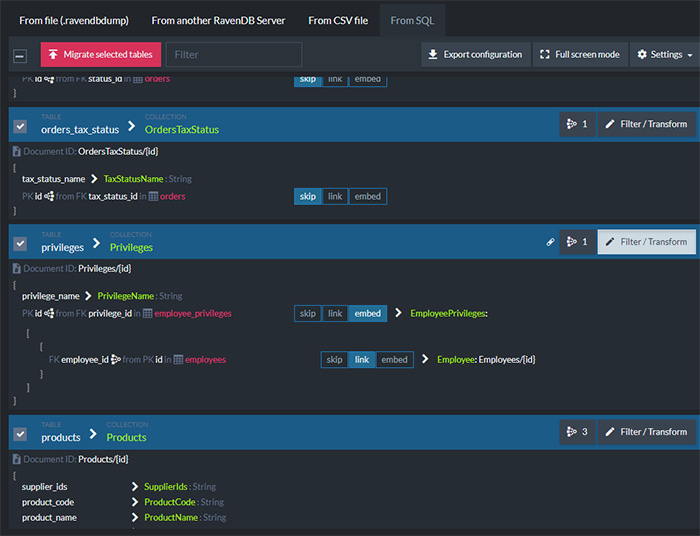
All you need is to provide the connection string and specify how you want the data to be transformed during the migration process. You can select which tables to migrate, whether references should be stored as linked documents or embedded values, etc.
You can even supply your own logic to control the conversion of the data from the relational store into RavenDB.
This approach is very common when you are just starting out with RavenDB. The SQL Migration allows you to very quickly get your own data into RavenDB and start operating with full capacity. You can start developing with real data and work within your own domain. Typically, you’ll use this process several times, each time refining the transformations you use in the migration until you hit the right document model for your needs.
Going in the other direction, RavenDB has SQL ETL capabilities, allowing you to sync any data from RavenDB back to a relational database. RavenDB takes on itself the responsibility to issue all the appropriate commands to ensure that the relational database has all the updates that were made directly on RavenDB. You can customize the behavior and control the content that is sent to the relational database and how the document model is translated to the relational model.
Importing data from non-relational source
RavenDB has the ability to pull data from other non-relational databases such as CosmosDB and MongoDB. All you need to do is to point your RavenDB instance to the relevant server and it will be able to fetch all the data from that server.
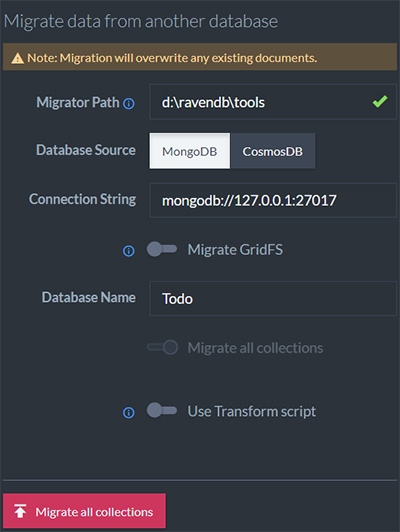
The following image shows a migration from MongoDB. The same concept applies for pulling data from CosmosDB as well.
As you have probably have guessed, RavenDB also has full support for transforming the data as it’s being ingested. You can use the process of migrating the data from your existing database as the chance to also update the format of your documents.
In some cases, because RavenDB, MongoDB and CosmosDB all have roughly the same model, you can just import the data and immediately start working with it. Run the process once and you are done.
We have also seen many cases where teams migrating to RavenDB take advantage of the fact that they are now much more familiar with document modeling and change the way they structure their model accordingly.
RavenDB contains several features you might want to take advantage of to positively impact your modeling. For example, following document references is easy with RavenDB and there are several features dedicated to this (includes, load, etc). You can even query for documents using data that is present in a linked document.
When performing such a migration, we recommend that you’ll look at your model with an eye toward how you can best take advantage of the rich feature set that RavenDB has to offer. There are several scenarios in which operations that are awkward in another database are quite natural in RavenDB. One such example is full text search. While other databases need to plug in another product (Elastic or Azure Search), full text search is a built-in core capability in RavenDB.
Loading CSV data into RavenDB
The final way in which you can get data into RavenDB is by loading a CSV file. Even in today’s world, a lot of data is being schlepped around as flat files and CSV is the most common file format. RavenDB allows you to point to a CSV file and specify what collection it should go to. RavenDB will read the CSV file, create a document from each row, and store the documents in the specified collection. It’s that simple!
CSV files are common because there is very little that is actually required of them. It’s just a bunch of rows with comma separated values. They are also well known for their troublesome nature precisely because they have so little structure. Regardless, they are ubiquitous in many organizations.
One of the primary reasons why CSV files are used is the ease of integration with one of the best business intelligence tools, Excel. For this reason, beyond just being able to import and ingest CSV files, RavenDB also has an easy way to export data to Excel.
This completes the cycle and allows you to get some data from RavenDB and into the hands of a business analyst who may work with the data as they wish and then send it back to be loaded into the database.
RavenDB is simple, easy and It Just Works. Just the way we like it.
RavenDB is the leading operational and transactional Enterprise NoSQL database provider. Quick to install and simple to secure, RavenDB gives you rapid scalability with a distributed data cluster. You can use RavenDB in tandem with a relational database using our ETL Replication feature.
Enjoy a Fun Intro Video or Download RavenDB 4.0 for free and get 3 cores, our state of the art GUI, and a 6 gigabyte RAM database with up to a 3-server cluster up and running quickly for your next project.
RavenDB has a built-in storage engine, Voron, that operates at speeds up to 1,000,000 reads and 150,000 writes per second on a single node using simple commodity hardware. With RavenDB, you can build high-performance, low-latency applications quickly and efficiently.
Go schemaless and take advantage of our dynamic indexing to stay agile and keep your release cycle efficient. Expand to IoT by fitting RavenDB onto a Raspberry Pi or an ARM Chip. We perform faster on these smaller servers than anyone else.
RavenDB is ACID across your entire database cluster. It can be used on-premise or in cloud solutions like Amazon Web Services (AWS) and Microsoft Azure.
Woah, already finished? 🤯
If you found the article interesting, don’t miss a chance to try our database solution – totally for free!



