 Skip to Navigation
Skip to Navigation
Indexing in RavenDB Compared to MongoDB and PostgreSQL

Introduction
In this article we’ll discuss how RavenDB indexes documents and how it differentiates itself from MongoDB, another NoSQL document database, as well as the relational database, PostgreSQL.
When it comes to indexing, RavenDB favors “eventual consistency” which means that it optimizes for high throughput read and write scenarios and attempts to return results to queries as fast as it can. These results may be “stale” until the index incrementally rebuilds to catch up to any new document changes. In RavenDB, you may also explicitly wait for non-stale results. On the other hand both MongoDB and PostgreSQL favor consistency (unless read on a secondary replica) but this means indexes impact read/write performance.
The Role of Indexes
In RavenDB, one key differentiator is that all queries are backed by indexes. They are the only way to query data. It’s worth clarifying that when we say “query” we are specifically talking about finding and filtering documents by properties other than their key. Document lookup and writes using keys are ACID-compliant transactions in RavenDB even across a cluster.
This design stands in contrast to most databases where indexes are a way to optimize queries. This means that by default you are getting sub-optimal performance out-of-the-box in most databases since creating indexes is always a manual design choice.
RavenDB offers both “auto indexes” and “static indexes”. Auto Indexes are generated indexes whenever you issue a query that doesn’t specify a static index. This means that you are always getting performant queries by default.
If we had a fresh RavenDB database without any indexes, we could safely issue the following query to get all Employees by a specific department key:

This query will generate an auto index named “Auto/Employees/ByDepartment” if it doesn’t yet exist and will start building it. For a new auto index, initially RavenDB will perform a quick indexing operation to try and return results immediately after which it will fully rebuild the index. This is what it means to be “stale” or “eventually consistent” from the perspective of an application.
Normally, auto indexes are optimized well enough that you will not need to customize them but for full control, you can promote them to static indexes to customize the way it is built. Static indexes can be specified for queries like so:
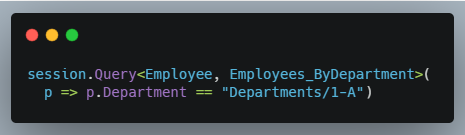
By specifying a second generic argument, we’ve told RavenDB to specifically use the EMPLOYEES_BYDEPARTMENT static index which we now have defined in our codebase.
In MongoDB and PostgreSQL, indexes are only used when the query engine determines an index can serve the results of a query. This means you must use the query explanation or analyzer functions to profile each query and determine whether or not it needs to use an index. It also makes debugging difficult as a seemingly small change to a query, such as adding a new condition, will change the way it is executed leading to possibly unexpected performance degradation.
Defining Indexes
In RavenDB, index definitions can be written in C# or JavaScript. It is expected you will define indexes in your codebase so they are versioned and deployed along with your application. You may also create them through the Studio interface.
In MongoDB, indexes are defined as JSON objects and can be deployed through code or through MONGOD. Indexes are created through the ENSUREINDEX command where you specify the column(s) to index and any other options.
In PostgreSQL, indexes are written in SQL through the CREATE INDEX statement.
Deploying and Rebuilding Indexes
RavenDB strives to be easy to manage and one way it accomplishes this is through side-by-side index deployments. When an index definition is changed, such as adding a new column, a new temporary index definition is created to replace the old one. RavenDB waits until the new index is fully rebuilt before replacing the old index. All queries using the old index are still served and a seamless transition occurs where they will be served by the new index once it’s replaced. This side-by-side feature ensures a “zero downtime” experience for your application.
In MongoDB, you must drop and recreate the index to change it. While an index is building Mongo will allow read/write operations to the collection but there is an interleaving locking process. PostgreSQL deploys changes to indexes the same way. RavenDB does not lock collections ever so it is always safe to save and load documents. When an index is rebuilding, queries will return either stale results (in the case of an incremental rebuild) or no results (on a full rebuild) with an ISSTALE flag set to TRUE so your code can make a decision on how to behave.
Indexing Document Properties
The simplest index in RavenDB is a Map index which selects fields from a collection. For example, using C# LINQ a Map function for an “Employees by Department” index may look like this:
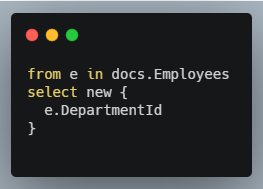
This selects DEPARTMENTID as an indexed field which allows querying the Employee collection by department. Unlike SQL “views” the results of a query on this index will be the full Employee document not the projected fields.
Both RavenDB and MongoDB support the idea of a “covering index” using stored fields. While this uses more disk space, you can bypass loading documents if the query can be fully satisfied from stored index fields.
It is simple to add filter conditions using the LINQ WHERE clause. Only employees who are considered “active” (non-terminated) would be indexed:
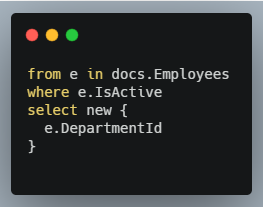
Since indexes are written in C# or JavaScript, any valid expression or native function is supported. You can also import other libraries for usage within C# and JavaSCript indexes as additional sources. Computed expressions affect the build time of your index so it’s best to use the Studio to examine how your indexes are performing.
The Map step has access to the full document and power of C#/JavaScript so you can include complex expressions such as computing order totals from line items and even loading related documents during indexing time:
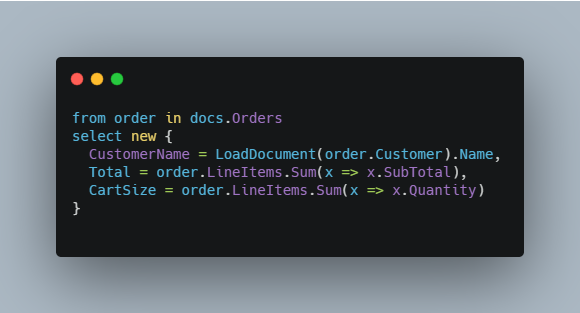
MongoDB and PostgreSQL indexes are similar to how most databases work where you specify the column(s) to index. Multicolumn indexes are more limited than Map indexes in RavenDB because the order of columns matters. One major feature of PostgreSQL is that it can index JSON using the jsonb data type and supports special JSON operators in queries. This allows you to mimic the design of document storage by storing JSON into columns that can be queried alongside traditional data type columns.
PostgreSQL supports indexing on expressions and “partial indexes” that can index a subset of data but these add overhead and will affect write performance. In MongoDB, you cannot perform filtering or include computed expressions in the index definition. Instead, MongoDB offers the Aggregation Framework and Map/Reduce for these more involved use cases.
Performing Aggregations in Indexes
Perhaps the biggest difference between MongoDB and RavenDB is that MongoDB does not run aggregations as part of the indexing process. Both MongoDB and PostgreSQL treat aggregations as ad-hoc operations. By building aggregations into the indexing process, RavenDB is able to keep them up-to-date as documents change. In effect, RavenDB combines “traditional” indexing of columns with aggregation using Map/Reduce indexes.
For example, we can transform our “Employees by Department” Map index into a “Count of Employees by Department” Map/Reduce index by adding a COUNT property to the Map definition and a Reduce step to sum up the COUNT grouped by DEPARTMENTID:

Since RavenDB evaluates these expressions at indexing time on the database server, query performance remains fast, allowing you to offload aggregate computations to the database instead of your client application.
In MongoDB, the AGGREGATE command uses JSON objects assembled into a pipeline that refer to built-in commands (prefixed with $). The aggregation framework commands use compiled native code which performs better than the more flexible MAPREDUCE operation. For example, to count of the total number of employees in each department you would use the $GROUP and $SUM aggregate functions:
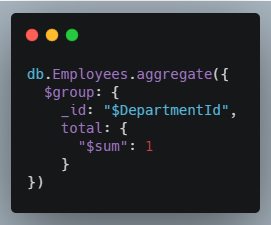
This would need to be re-run each time you wanted new results. You can use the $OUT or $MERGE commands to output to sharded or non-sharded collections. For maximum flexibility, MongoDB offers the MAPREDUCE command which can run arbitrary JavaScript functions and can also output to collections.
PostgreSQL does not support aggregation expressions within indexes directly and you would have to either design complex queries with aggregate functions, use Materialized Views (which, again, are manually refreshed), or set up TRIGGER actions to store computed data on write. While it is possible to support aggregate queries in PostgreSQL, it involves heavy optimization and database design considerations.
Full-Text Search
RavenDB offers full-text search indexing through the Apache Lucene engine which offers a robust and fully-featured full-text search capability including the ability to perform faceted searches and query for suggestions, which aren’t available with MongoDB or PostgreSQL. MongoDB TEXT indexes can be used to perform searches but options are limited to customize the way text is analyzed and more robust search solutions would need to be built on top, such as MongoDB Atlas Search.
Geo-Spatial Indexing
In RavenDB, Spatial Indexing can be used for querying spatial data. MongoDB offers geo-spatial capability through its 2dsphere and geoHaystack indexes. PostgreSQL offers some built-in Geometric data types but geo-spatial querying is offered using a database extender like PostGIS.
Enforcing Uniqueness in Indexes
MongoDB and PostgreSQL offer the ability to include unique constraints on an index, ensuring that duplicate data is prevented from being stored. While RavenDB does not offer the same uniqueness constraints through indexing, it instead offers the Compare Exchange API which works for ensuring uniqueness across a distributed cluster. This API is not as simple as passing a flag to an index as you would in MongoDB or PostgreSQL but it is more robust for coordinating cluster-wide transactions including uniqueness enforcement.
Summary
Even though RavenDB and MongoDB are both NoSQL document databases, the role indexing plays is very different. RavenDB queries must use an index whereas both MongoDB and PostgreSQL treat indexing and aggregations as separate distinct features. It is important to understand the trade-offs with both designs and your solution use cases.
Woah, already finished? 🤯
If you found the article interesting, don’t miss a chance to try our database solution – totally for free!



