 Skip to Navigation
Skip to Navigation
Discovering a new database: RavenDB

Next month I will start working for a new company. That means a new Starbucks, a new office chair, and of course, working with new software. One of my first new applications will be working with RavenDB, a NoSQL Document Database.
RavenDB is developed in C#. It was created by Oren Eini, also known as Ayende Rahien. Oren has a major history of collaborations in open-source projects for the .NET world.
RavenDB is widely known among .NET developers, and also has a following among clients for Python, Go, Java and Node.js. Moreover, you can use Rest to access the database from any language.
You can find additional information on the features of this database here: ravendb.net/why-ravendb/designed-with-care and ravendb.net/features.
Some features have particularly drawn my attention: support to time series, spatial data, easy cluster management (and the possibility of any node to receive writes even if others are down), and replication mechanism.
Their data replication mechanism seems to be fantastic. A restaurant network uses RavenDB to synchronize information between the hub and thousands of restaurants worldwide, which represent around 1.5 million selling points with embedded RavenDB. The whole synchronization is made only by using the database mechanisms, with no initial development. It seems to be the perfect database for Edge Computing solutions.
Based on this scenario, I will build the example.
First of all, I would like to highlight that this is my first experience with RavenDB. It is also a trip back to the .NET world, which I left behind 11 years ago. Therefore I apologize in advance for any possible mistake or any code that doesn’t seem to have been done in the best way.
Before starting the example, I will answer the question that may be in your minds right now: if this is a NoSQL database, why not MongoDB, or why not a relational database?
There are no major comparisons available between MongoDB and RavenDB, yet what I have seen so far is the possibility of solving a few issues by working with RavenDB that I don’t see anywhere else.
MongoDB is an excellent database to store information, but searching for anything there is not that good. If you do not model your database thinking of how you may need your data in the future, you may have serious trouble. When you need to join collections, the performance cost and the difficulty of writing the query can be massive. Add “group by” or “distinct” and you can spend hours creating the query.
Another issue I found in MongoDB is the need for constant follow-up by a “DBA” or a Mongo specialist in order to check if a developer has not made any query without an index. Any slightly more complex query without an index may break the performance of a whole cluster.
Finally, an issue mentioned by many people is the recent support to multi-documents ACID transactions that still need improvements in terms of performance.
RavenDB addresses the following issues:
- From its’ first versions, there is support for multi-documents ACID transactions. This is already consolidated in the database.
- All queries use an index on RavenDB, whether the developer wants it or not; in case the index does not exist, it is created automatically; you will never have tablescan issues as in Mongo.
- Queries are written in RQL, a much clearer query language, mainly for those coming from relational world.

An example of using RavenDB
In order to illustrate the use of RavenDB, I will demonstrate a simplified use case:
Story: Moletronics manufactures high value-added equipment, as smartphones, tablets, smartwatches, etc., for famous brands. Moletronics has several industrial plants and each one has several gatehouses for trucks. The gatehouse must be open only for vehicles/people authorized in the waybills created by ERP. Since some of the gatehouses are far from each other, network interruptions may occur, but the system must be resilient and must not prevent access to trucks because of such issues. As soon as the truck crosses the gatehouse, either getting in or getting out, a note must be made in the waybill.
The waybill is similar to the document below:

Converting the document above into a class diagram, we have:

A waybill in .json format would be similar to the one below:
As previously defined, in this V0 the goals are the installation of a RavenDB and the creation of an API for insert/query/update. Initially, the application will be made in Python. Hands-on then!
1. Installing RavenDB
It can be installed in several ways:
- There is a cloud version managed by RavenDB: cloud.ravendb.net
- Directly on the servers: ravendb.net/download
- As a container: hub.docker.com/r/ravendb/ravendb
We will run as a Docker container.
Machine 1 – Linux
Note: you can also use Windows. Just remember to adjust the directory mentioned below.
1. Downloading the image:
docker pull ravendb/ravendb2. Running the image: by default, like any image-based server, data is embedded in the container. We will first create a directory to save data in the home folder and indicate it as the volume for the container. Note that my home /home/cassio must be changed to your directory.
$ cd $HOME
$ mkdir ravendb_data
$ docker run -p 8080:8080 -v /home/cassio/ravendb_data -e RAVEN_ARGS='--Setup.Mode=None' -e RAVEN_Security_UnsecuredAccessAllowed='PrivateNetwork' --name raven_node ravendb/ravendbExplaining some of the arguments:
- Setup.Mode=None – disables setup wizard
- RAVEN_Security_UnsecuredAccessAllowed=’PrivateNetwork’ – enables the use of insecure http. In case of tests it is valid to speed up the deploy, but never use this argument in production.
By running the command above, we have the following screen:
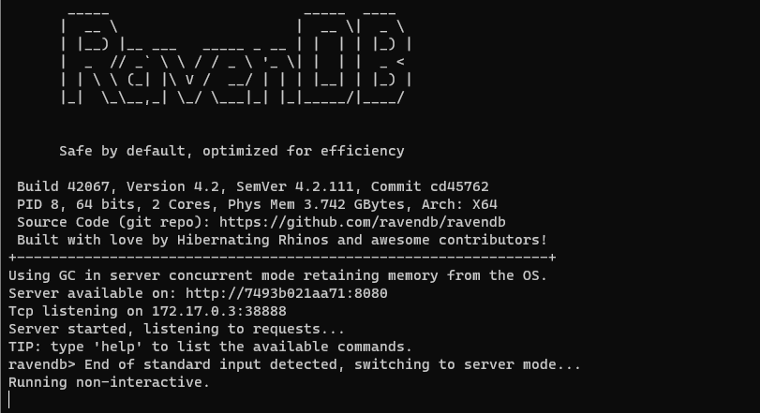
You can access RavenDB Studio through 8080 port of your server. In my case, http://192.168.0.156:8080.
After accepting EULA, you will reach the home page of the Management Studio GUI. Very well done, by the way. 😉
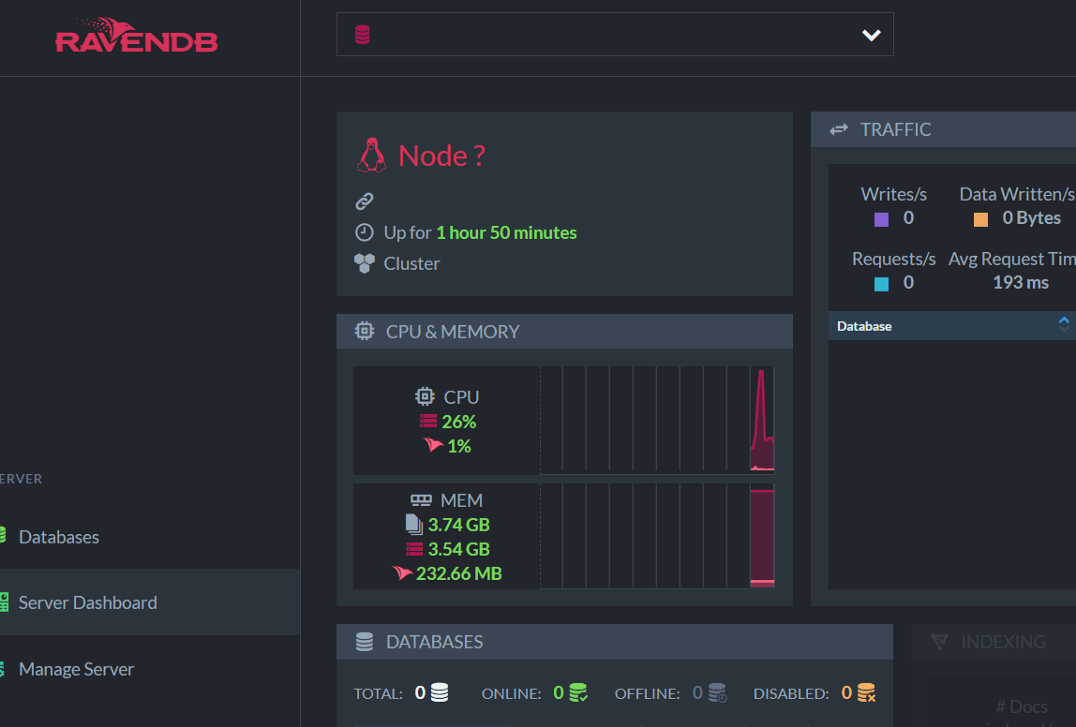
Before developing the code in Python, we will get more familiar with the Management Studio. We will initially create the database. It is done in the Databases option in the left side menu above. Then we select the option New database, which shows the following screen:
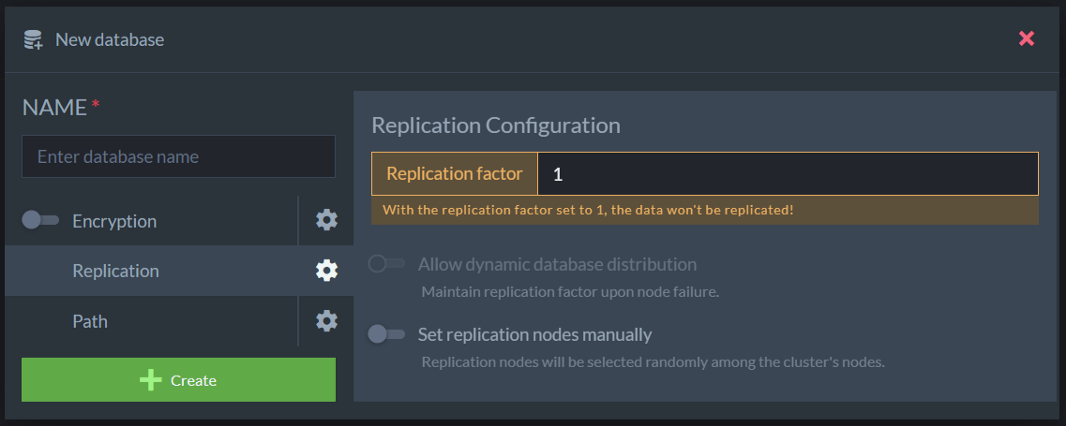
Provide the name romaneios (waybills), and click on create. It will take a few seconds, and then the database will be available for selection:
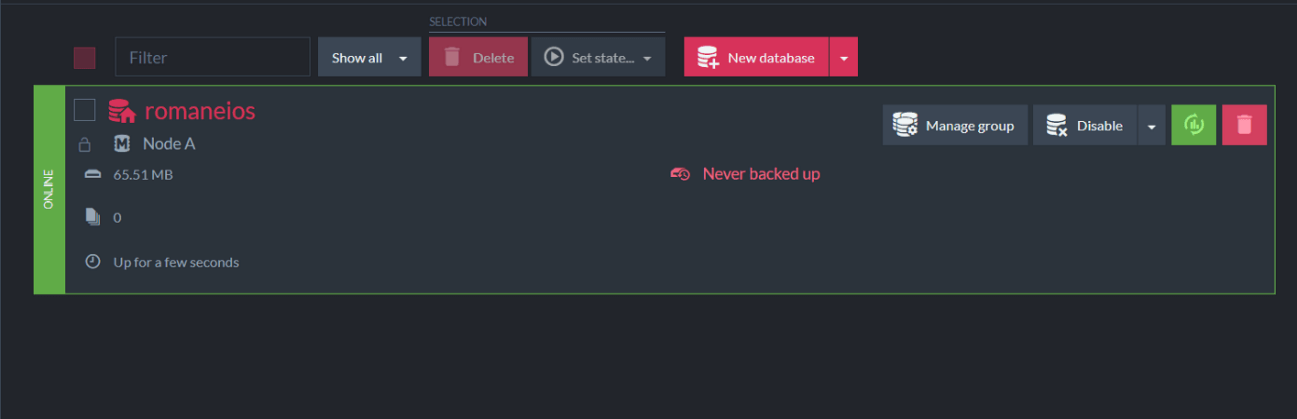
Select the romaneios (waybills) database. You can start inserting files on the next page:

RavenDB saves all documents in the same space. There is no physical separation by tables or something similar. You can search a document in RavenDB without specifying the collection it is inserted in.
However, for organization purposes, it is important to specify the collection to which the document belongs. You do not create collections explicitly. You add a “metadata” key with a “collection” key as follows:
It will create a “test” collection and add a document to it. For testing, click on New document, copy the content below, and click on Save. You will see the collection on the left:
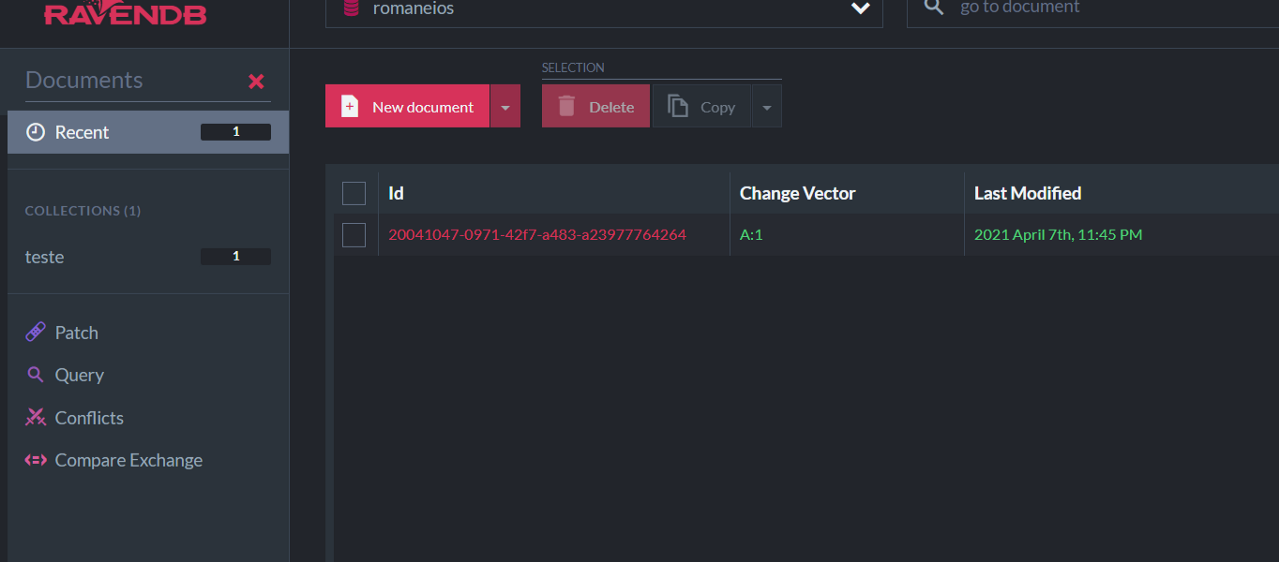
If the collection is not specified, the content or JSON file will be saved in a special collection named “empty”. When you work with a client (C#, Python, etc.), the lib will do it automatically for you: the collection will be named after the class of the object.
Now let’s insert 3 documents in order to make a few tests. Click on New Document and copy/paste/save each one of the docs below:
Now we have 3 documents saved in the database. Notice they are in the “romaneios” (waybills) collection because this value was stated in the metadata/collection tag in the .jsons above:

As a curiosity (and knowledge of RQL), make some queries in the above documents. Click on the Query option on the left side and make the following queries:
from romaneiosIt will return all 3 waybills. Note that, unlike a SQL query, it is not necessary to provide the “select” in case the objective is returning all fields.
from romaneios
where numero > 1Now we are filtering by field. You will notice that the first time you run filtering on a field, the query will take longer. A RavenDB’s premise is never making a “table scan”, so in case it detects that there is no index for that criterion, it will be created for you.
By using RavenDB you surely will never be woken up by Mongo DBA complaining that you make a query without index that is “grinding” the server with table scan.
Finally, in order to return only one or more specific fields, we do as follows:
from romaneios
where numero > 1
select data_hora_cargaThose coming from relational databases feel at home!
2. Accessing RavenDB with Python
As previously mentioned, in this first article we will make a simple API that allows you to register waybills, add items in waybills, and retrieve waybills. The full project is available at github.com/cassioeskelsen/discovering–ravendb.
We will use FastAPI to build the API, thus we already have the built-in swagger, which will save development time. We will use the official lib to access the database github.com/ravendb/ravendb-python-client.
By downloading GitHub application, you can prepare the environment to install all dependencies through:
$ python3 -m venv ./venv
$ source ./venv/bin/activate
$ pi3 install -r requeriments.txtThe code consists of two files.
1. The file containing the classes of the domain, which are partially generated from json in the excellent app.quicktype.io:
2. The file with the application:
A few comments are necessary here.
Line 9: change the IP address of your RavenDB server.
Lines 16 and 17: the initialization with the database is created here. This is recommended to be made only once, that’s why I put it in the FastAPI startup event. In a real application, I suggest the creation of a singleton responsible for this connection.
Lines 20-27: an endpoint that returns 1 or many waybills.
Lines 30-38: an endpoint that allows registering a new waybill. Note that the register operation in the database is in a “session”.
Lines 41-48: an endpoint that allows registering an item to the waybill. Note that we first load the object in the database, then we add the item. We do it in the same session so that the client can track the object and knows we are making an update, otherwise a new object will be created in the database.
You can run the application with the commands (from the roots of the application):
python run.py
ou
uvicorn src.app:app --reload --host 0.0.0.0 --port 8080The second option is interesting for tests because the application is always reloaded in case of code change. Now you can open the swagger address in your browser.
http://<seu_host>:8080/docs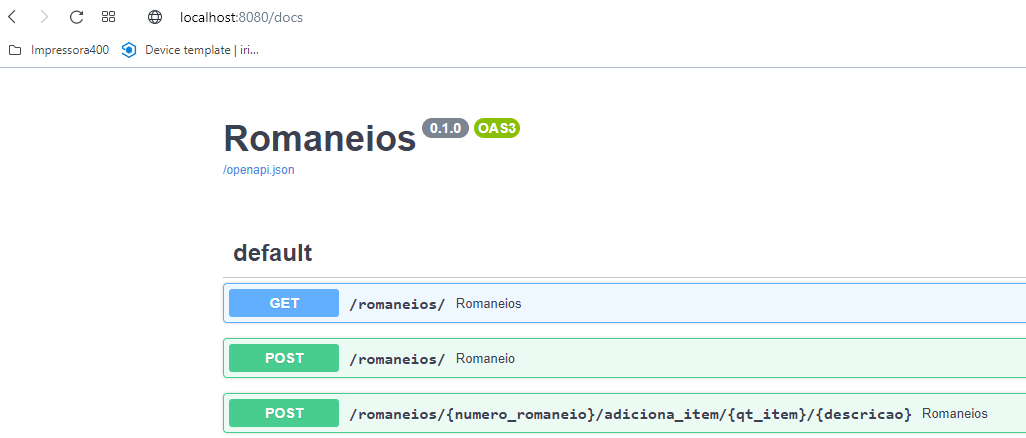
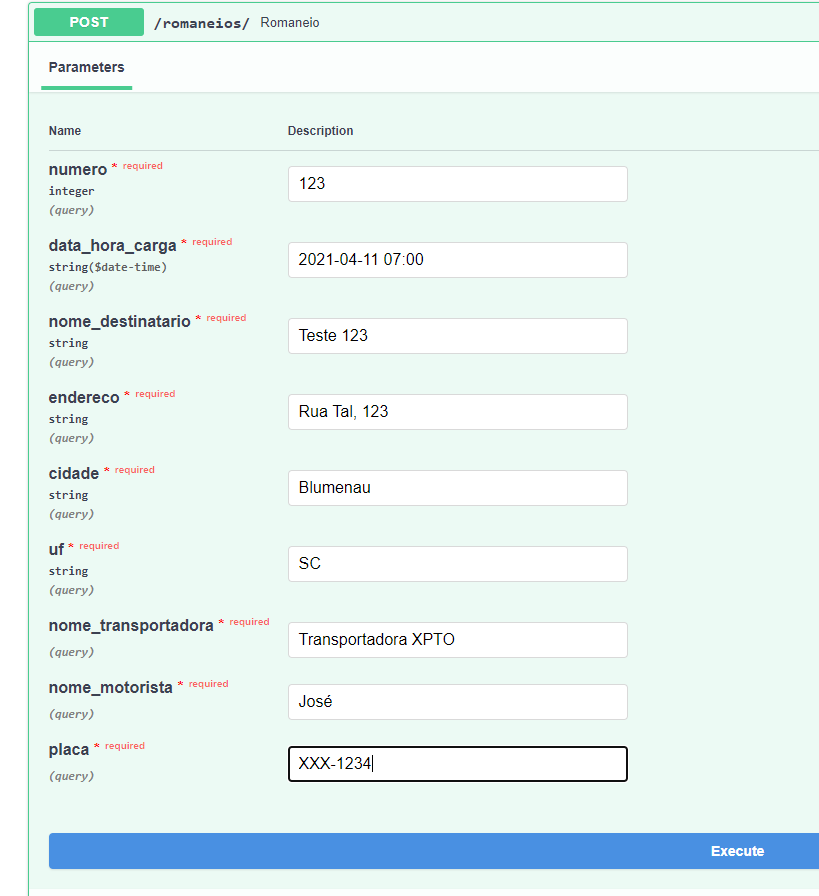
We will first create a new waybill in the path /romaneios:
If we open RavenDB management studio, database waybills, collection waybills, we will see the new register there:
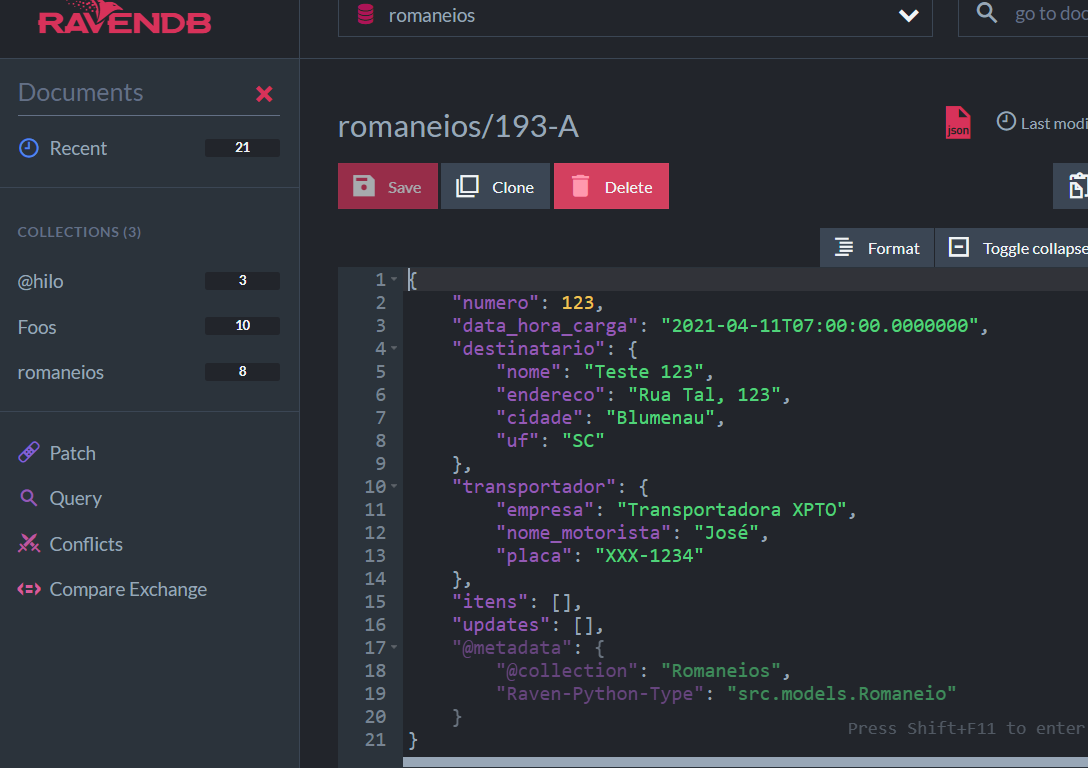
Note the generated ID romaneios/193-A. RavenDB clients, by default, always create the ID based on the name of the collection. It is an interesting strategy that makes the identification/query easy in the document.
Now we will use the second path to add an item to the waybill:
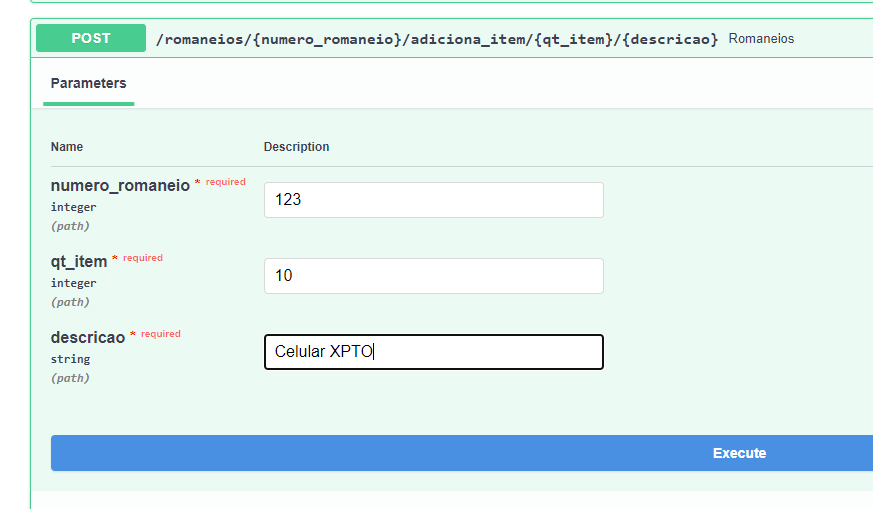
Finally, we will use GET method to verify if everything is stored correctly:
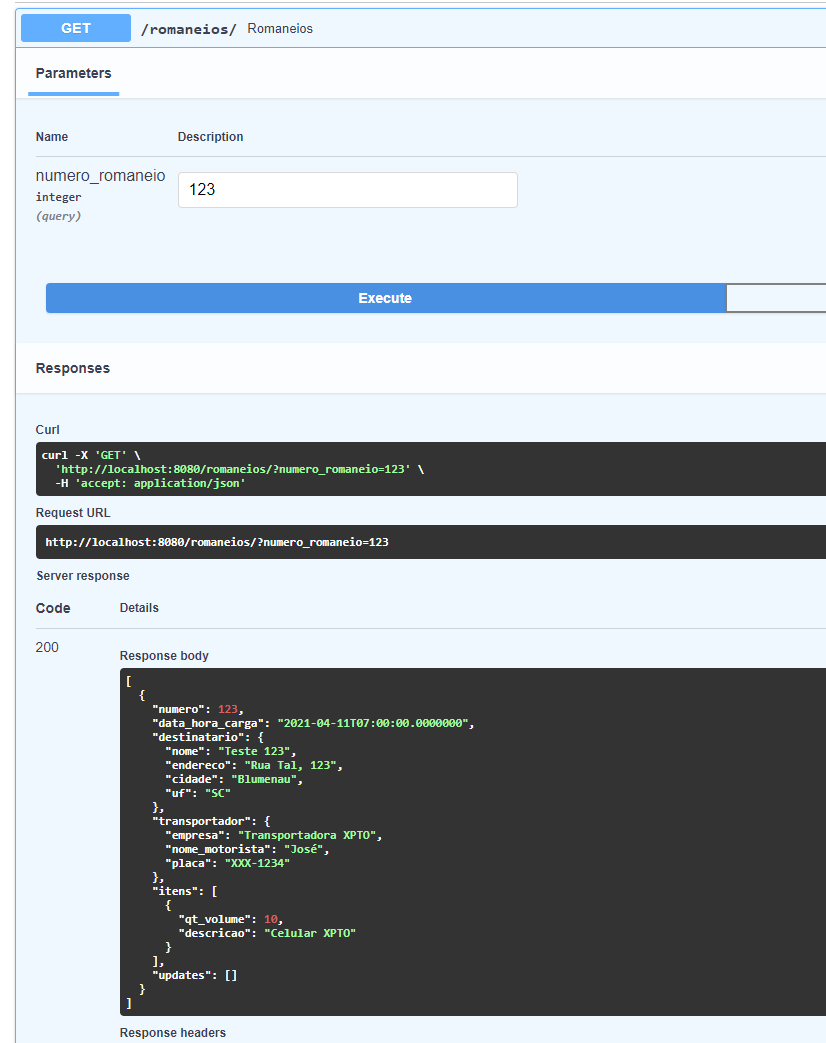
Conclusion
The purpose of this article was to offer an overview of what’s possible with RavenDB. RavenDB is a very fast database that is easy to install and maintain. Some features show it was built by people who really use databases on a daily basis and always deal with the same issues we do.
The cases available online demonstrate that it is a database to be used from small applications up to an enterprise-level, with several clients having high data volume.
In an upcoming article, I expand the solution using the replication mechanism to simulate the remote application operation in Moletronics gatehouses.
Woah, already finished? 🤯
If you found the article interesting, don’t miss a chance to try our database solution – totally for free!



