 Skip to Navigation
Skip to Navigation
Full-Text Search Fundamentals in RavenDB

When it comes to full-text search, years of googling have conditioned us to expect instant, accurate results for any query we can come up with. Unfortunately, creating a powerful and effective search engine is really hard. While most databases offer some kind of search functionality it’s usually bare bones, and the issues of speed and relevancy are often treated as an afterthought – if addressed at all.
Rather than trying to reinvent the wheel, RavenDB makes use of the Java library Lucene to facilitate its full-text search. With Lucene you can search your database with all the power and functionality of a top-tier search engine – results are virtually instantaneous and highly relevant, querying is deeply customizable, and there’s extensive support for extra features like wildcards and suggestions.
While this full-text search functionality is available out of the box, you still need to know how to use it. I’ll cover that in this article, as well as going through how RavenDB conducts full-text searches, how to adjust the process to suit your needs, and some of the extra features that are available.
Table of contents
The First Step – Indexing
Full-text search should be lightning-fast, even on large text fields. This can be achieved using indexing; the process of creating data structures called indexes designed to facilitate full-text queries.
Indexes in databases are similar to the ones you find in the back of books. They make the books a bit longer, but they tell you exactly where topics are mentioned and save you from having to search through the entire text. Likewise, a database index requires some extra storage space, but makes queries much, much faster. The more text there is to search, the greater the relative speed and efficiency of using the index
In RavenDB indexing is performed in the background whenever data is added or changed. This allows the server to respond to queries quickly, even after large-scale changes.
Read more about deploying indexes in RavenDB
The Inverted Index
There are various types of indexes; the kind RavenDB uses is called an inverted index. To create an inverted index a text field is split into smaller sections called tokens or terms. Each unique token, with references to its occurrences, is stored in the index.
An inverted index stores all the terms in alphabetical order grouped by the field they appear in. This dictionary or vocabulary of words shows how many times and where each term appears in the original text.
Creating Indexes with Analyzers
The process of splitting the field into tokens is called tokenization, and how tokenization should be performed is determined by the analyzer used.
An analyzer is an object that determines where to split the text to create tokens.
Given the text “Email me, sample@example.com” one analyzer might split the text at whitespace and produce tokens like so:
[Email] [me,] [sample@example.com]
While another might split it on all non-alpha characters and produce these tokens:
[Email] [me] [sample] [example] [com]
Analyzers can also perform a process called filtering in which various filters remove or alter the tokens in different ways. Alterations may include normalizing characters to all lower case, or to versions without diacritics. Punctuation, and stopwords like “the” and “is” are often removed, as are other unhelpful tokens that might impact the quality of the search.
Harnessing the Power of Lucene
RavenDB uses Lucene to power its indexing and full-text search.
Lucene is described on its website as a “Java library providing powerful indexing and search features, as well as spell checking, hit highlighting and advanced analysis/tokenization capabilities.”
Lucene powers search for many large companies such as LinkedIn and Twitter. It’s very fast, efficient, and packed with features. It’s also constantly being updated/improved.
Lucene’s StandardAnalyzer is perfect for a general search, but many other analyzers are available. You can even create your own if you need something unique.
An important feature of Lucene is that it automatically scores documents on their relevancy to the user’s query and ranks them accordingly in the search results. It’s extremely fast and requires no input or complex understanding from the user, though modifications are possible.
Enabling Full-Text Search in RavenDB
RavenDB by default indexes using LowerCaseKeywordAnalyzer, which is a custom analyzer that sets the entire field as a single token, then converts all upper case characters to lower case.
Obviously, this isn’t useful for full-text search, so for that, we need to tell RavenDB to use a different analyzer.
Selecting an Analyzer
Selecting an analyzer in the management studio is as simple as editing the index definition and entering the fully qualified name of the analyzer class in the Analyzer field.
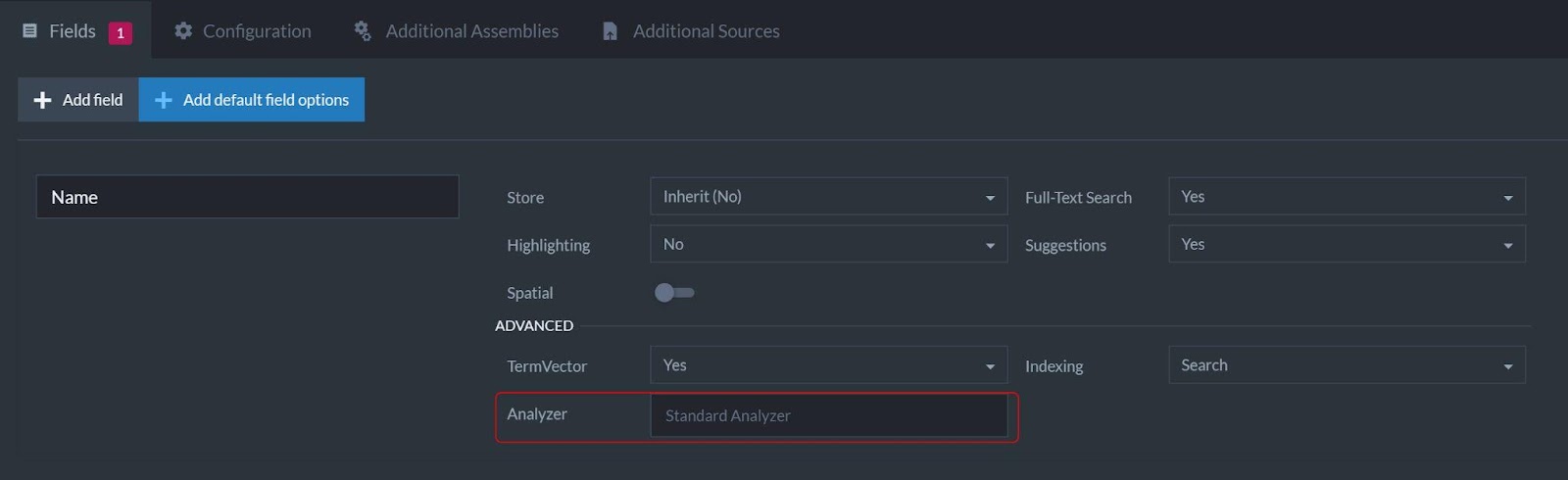
To add an analyzer using code is also straightforward. For a field called Content we would use:
Indexes.Add(x => x.Content, FieldIndexing.Search);
which makes the Content field searchable by applying Lucene’s StandardAnalyzer.
If we wanted to add a specific analyzer such as SimpleAnalyzer we would use the line:
Analyzers.Add(x => x.Content, "SimpleAnalyzer");
Bonus Full-Text Search Features
Anyone who’s used a search engine should be familiar with the useful additional functions that can complement full-text search.
The ability to detect and correct typos or suggest similar terms. The use of prefixes or wildcards. The ability to preview snippets of text with keywords highlighted. These powers and many more are available in RavenDB, and you can read about how to apply them here.
In all, with the help of Lucene, RavenDB offers powerful and fast full-text search capabilities, a simple setup, and extensive customization options. Google eat your heart out.
For more detailed information on functionality or implementation, you can check the RavenDB documentation or read up on Lucene.
Happy searching.
Woah, already finished? 🤯
If you found the article interesting, don’t miss a chance to try our database solution – totally for free!



