 Skip to Navigation
Skip to Navigation
RavenDB’s OLAP ETL Opens the Door to Business Intelligence

Unfortunately, a single database can’t be all things at all times. A system optimized for transactions is fundamentally different from one optimized for queries – from the way the data is stored to the manner in which it’s processed. This necessitates the existence of two different types of data processing tools. OLTP (OnLine Transactional Processing) and OLAP (OnLine Analytical Processing).
Table of contents
- What is the Difference Between OLTP and OLAP?
- RavenDB for OLTP
- How Can You Export Data From an OLTP Database?
- You Can ETL to SQL for Analysis, But…
- Advantages of OLAP on the Cloud
- How Can You Synchronize Data From OLTP to OLAP on the Cloud?
- Column-Based vs Row-Based File Formats
- Apache Parquet Files
- Creating OLAP ETL Tasks in RavenDB
- Additional Details
What is the Difference Between OLTP and OLAP?
OLTP is a type of data processing focused on handling real-time transactions. It’s used for business applications like order entry, invoicing, banking transactions, etc. Older data is rarely touched. (How often do you check your bank transactions from 5 years ago?)
OLAP is designed for complex, heavy querying of data; trawling through large volumes to gain facts and insights. It’s used for business intelligence purposes like analytics and reporting, often working on data aggregated from OLTP systems. Historical data is much more relevant in this context as you look for trends and patterns over time.
RavenDB for OLTP
RavenDB is an OLTP database, so the focus is on processing transactions. Its queries are highly optimized (for an OLTP database), and it does have features for analysis and reporting, for example, MapReduce and facets for specific scenarios such as orders by customers.
But RavenDB isn’t designed for real queries like complex analysis of large data sets. For that, you want a specialized tool.
(Before getting to that, it’s worth mentioning another advantage of splitting the data processing roles: it allows you to perform queries on a separate database, one that isn’t serving your customers and doesn’t interfere with your local database performance.)
How Can You Export Data From an OLTP Database?
To get data from an OLTP database like RavenDB into another service, you use a process called ETL (Extract Transform Load):
- Extract the data you want to send from your database.
- Transform it into the format you want by aggregating, normalizing, censoring, etc.
- Load it to the other service.
You Can ETL to SQL for Analysis, But…
RavenDB is a document database. Optimized though it may be, queries can be more efficient on an equally optimized SQL database. Therefore for heavy queries, you might consider using RavenDB’s SQL ETL feature to push your data to a SQL reporting database.
Doing so was standard procedure in the past, but it’s no longer the ideal solution.
We’re now in the era of the cloud, with access to virtually unlimited power and scalability, and the ability to store large amounts of data relatively cheaply. On the cloud, OLAP services offer many advantages.
Advantages of OLAP on the Cloud
- SQL databases on the cloud are expensive to operate, especially with a lot of data. OLAP services utilize data formats that can be more highly compressed and queried more efficiently.
- Storage is very cheap on the cloud. If you know which data you’ll be querying most and take advantage of intelligent tiering, you can make it even cheaper.
- You can push data from multiple locations to a single point for processing.
- Data can come from multiple sources, for example, different OLTP databases.
- Multiple locations and sources can upload data at the same time.
- You can leave the complexities of pushing/uploading data from multiple sources to the cloud provider rather than handling them yourself.
- It’s easy to control who can access what data, for example, by giving upload only permissions to locations being pushed from.
- Your data is stored on the cloud where it will only be read from, not modified. This means you can safely expire old data from your OLTP database.
Examples of cloud OLAP services are Athena on AWS, Data Lake on Azure, Big Query GCP, or Presto for other platforms.
How Can You Synchronize Data From OLTP to OLAP on the Cloud?
This starts with an ETL process; the data must be extracted from the OLTP database, transformed into a format appropriate to the OLAP service, then uploaded onto cloud storage e.g. AWS. Once on the cloud, it can be ingested into OLAP services like Athena.
Column-Based vs Row-Based File Formats
As mentioned, OLAP services use a different data format to that of SQL databases. OLAP services use a column-oriented format while SQL databases are row-oriented.
Row-oriented file formats organize data by records, so the values of each record are stored together. In contrast, columnar file formats organize data by field, so the values of each field are stored together.

When querying a row-based data store, you have to load the records in their entirety to get the information you need, whereas with column-based stores you can load only the relevant column and its values.
Since you’re retrieving less information, queries are much faster and more efficient.
Column-based data is also more easily compressed, as the data within a column is generally of the same type and falls within the same range of values.
The downside of the columnar format is that writes are relatively slow, but for the purposes of OLAP that doesn’t really come into play.
Apache Parquet Files
The industry-standard columnar file format is Apache Parquet, which is what RavenDB’s OLAP ETL process generates. It is “designed for efficient data storage and retrieval. It provides efficient data compression and encoding schemes with enhanced performance to handle complex data in bulk.”
Parquet files also allow you to perform something called partitioning. This is where the data is separated (partitioned) into interconnected files according to some predefined conditions, e.g. the time the data was recorded, or the location.
The likely nature of your queries can be used to inform the rules by which you partition the data, and in RavenDB, these can be specified in the OLAP ETL setup process. (More on that later.)
Queries that only target a specific subset of the data only need to touch the associated partitions. For example, if you’re only interested in a particular year’s data, you can query the corresponding partition rather than sort through your entire 30-year data history.
In the end, your data can be orders of magnitude faster to query than if it were in row or document form.
Creating OLAP ETL Tasks in RavenDB
To summarize: the OLAP ETL feature in RavenDB allows you to Extract your data, Transform it into Apache Parquet format, and Load it into a storage service on the cloud.
The process takes only a couple of minutes to set up in the studio, and there’s an easy guide for it in RavenDB’s documentation on OLAP ETL tasks.
Once the data is in the cloud storage of your choice, it can be ingested by an OLAP service for processing.
Additional Details
A few important notes about how RavenDB handles OLAP ETL:
- The OLAP ETL process runs in batches and on the schedule you select, in contrast to the SQL ETL process which runs instantly. The reasoning behind using batch processing is that compression of the parquet format is more effective on larger batches of data, and it’s more efficient when loading data in bulk.
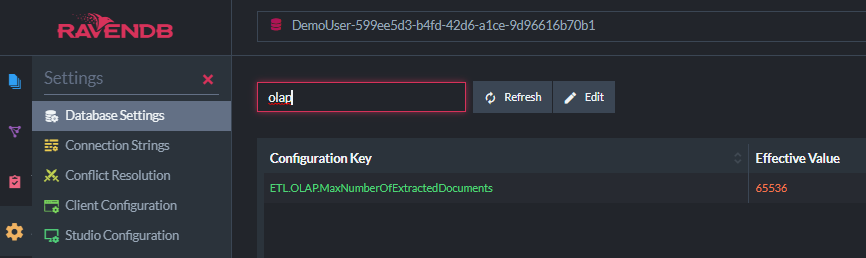
- By default, the maximum size of batches is 65k docs. You can customize this if you want larger files, but you’re unlikely to have more than 65k documents modified between ETL script runs.
- RavenDB’s OLAP ETL process works just as well on documents generated by things like MapReduce, or internal ETL processes. This is useful when you don’t want to push out raw data, for example, if there are security or privacy conditions, or if you only need a summary of the data to perform analysis on.
- To keep things simple, only a single node on a cluster is responsible for handling the OLAP ETL process.
- The system is optimized for liveliness, meaning RavenDB will automatically handle a bad connection – you don’t need to hold its hand.
And that’s about all you need to know!
By using RavenDB as your distributed OLTP database and connecting it to an OLAP service on the cloud via OLAP ETL, you set yourself up to aggregate and analyze vast amounts of data incredibly quickly. And with virtually no developer work beyond a few minutes of configuration in the studio, all that’s left is for the data analysts to work their magic.
To see how else RavenDB can benefit projects, book a free, tailored, 1-on1 demo with a RavenDB developer here.
Woah, already finished? 🤯
If you found the article interesting, don’t miss a chance to try our database solution – totally for free!



