 Skip to Navigation
Skip to Navigation
What’s New in RavenDB 5.0?

Introduction
RavenDB 5.0 is a major milestone for RavenDB, adding the ability to query and index time series data, schedule periodic document refreshes, customize database compression, and a host of quality of life improvements and bug fixes.
Time Series Support
RavenDB 5 brings support for time series data and querying capabilities. Time series data is heavily used in monitoring and operations, where you may be recording measurements many times a minute (or second!). While there are dedicated time series database technologies for these uses, RavenDB now supports querying and indexing time series data attached to documents.
Tracking Stock Prices Over Time
Another context where time series is used heavily is in the financial sector. Imagine that you would like to track a company’s stock price and a company was stored as a document like this:
using var session = store.OpenSession();
var company = new Company()
{
ExternalId = "OLDWO",
Name = "Old World Delicatessen",
Address = new Address()
{
Line1 = "2743 Bering St.",
City = "Anchorage",
Region = "AK",
PostalCode = "99508",
Country = "USA"
}
};
// Store the company to generate the ID
session.Store(company);
// Access the time series for the document, which
// is empty right now
var timeSeries = session.TimeSeriesFor(company.Id);
// Record end of day stats
timeSeries.Append("StockPrices", DateTime.UtcNow.Date, null,
new double[]
{
25.36, // Open
25.39, // Close
25.39, // High
25.36, // Low
38400, // Volume
});
// Save and commit the changes to the server
session.SaveChanges();
In RavenDB, similar to Counters, time series data is stored separately with an internal link to the associated document. You may have a process that watches stock prices and then updates the company document with pricing information at the end of the business day.
RavenDB supports passing multiple values for a specific timestamp which is why we can pass all the stock price data in one fell swoop. When loading a document that has time series associations we can choose to eagerly fetch it, just like including related documents, counters, and other extensions.
In the Studio, you can view and edit time series data for each document:
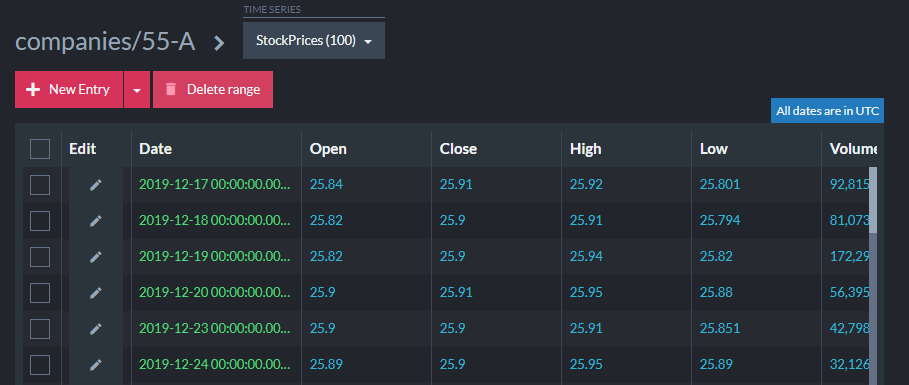
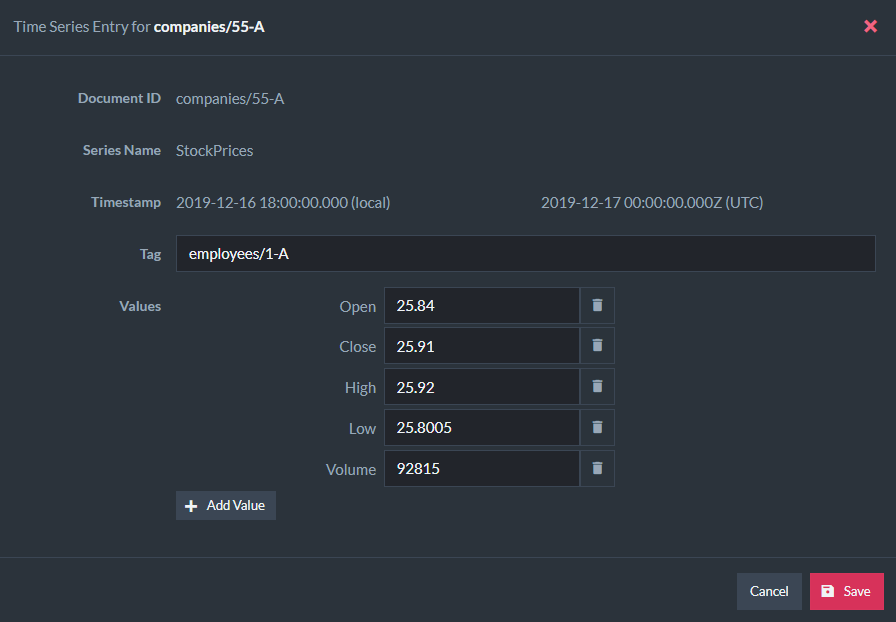
Time series measurements support named values to help understand what measurements are being recorded and these are shown in the Studio interface.
Querying Over a Date Range
Once the data is recorded, we can query it. We can leverage RavenDB 5.0’s new date range querying syntax for making it easier to retrieve time series data. In the following query, we can query the past 6 months worth of stock price data, selecting the minimum and maximum values we’ve recorded:
from Companies
where id() = 'companies/55-A'
select timeseries(
from StockPrices
between '2020-01-01' and '2020-06-30'
group by '1 month'
select min(), max()
) as StockPrices
This query is using the Raven Query Language and there is a new function called timeseries that RavenDB 5 introduces. This takes another RQL query but instead of being executed against a collection, it’s executed against the time series available for the document, StockPrices in our case.
We are querying for the past 5 months of historical pricing data with the between expression. Using the min() and max() functions, we can select the min and max measurements for each time series entry in our bucket (1 month), which will contain the measurements we recorded including the “Closing Price” value.
In the Studio, you can view the query results as a table like in previous versions but time series results also can be shown as an interactive visualization:
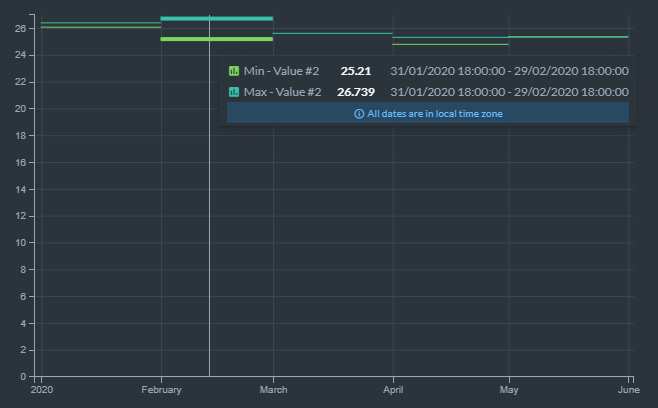
Using this chart can help us visualize the data and see the differences between min and max closing prices for each month.
This is a compelling feature but it becomes even more powerful when add indexing into the mix to allow aggregated querying.
Indexing Time Series Data
Let’s define a map/reduce index that can tell us the trading volume per month broken down by country across all the companies in our dataset:
// Map
from segment in timeseries.Companies.StockPrices
let company = LoadDocument(segment.DocumentId, "Companies")
from entry in segment.Entries
select new
{
Date = new DateTime(entry.Timestamp.Year, entry.Timestamp.Month, 1),
Country = company.Address.Country,
Volume = entry.Values[4]
}
// Reduce
from result in results
group result by new { result.Date, result.Country } into g
select new {
Date = g.Key.Date,
Country = g.Key.Country,
Volume = g.Sum(x => x.Volume)
}
In this index definition, we map over all the companies, taking their StockPrice time series entries and select a projection of the month, country, and trading volume. The reduced portion of the index groups companies by month and country so that we can total up the volume for all companies in the group.
The first line of the map statement is not querying a document collection, instead it is querying a special collection called timeseries, which is new in RavenDB 5.0. Time series are returned as “segments” which contain N number of entries, which could span multiple days. Each entry is selected through the from entry in segment.Entries statement. The entry contains the data we inserted initially, containing the StockPrice values of which the last value represents trading volume.
In order to group time series entries by country, we have to load the company document to retrieve the Address.Country nested property. To get the total month’s values, we remove the “day” portion of the timestamp. Once we’ve mapped over the results, we reduce them using a typical RavenDB aggregation expression, grouping by the month/country and summing the month’s entries to find the total volume.
We can then query for the trading volume for the United States during Q1 of 2020:
from index 'Companies/StockPrices/TradeVolumeByMonth' as e
where
e.Country = 'USA'
and
e.Date between '2020-01' and '2020-04'
select {
Month: new Date(Date.parse(e.Date)).getMonth() + 1,
Year: new Date(Date.parse(e.Date)).getFullYear(),
Country: e.Country,
Volume: e.Volume
}
This will return a resultset like this:
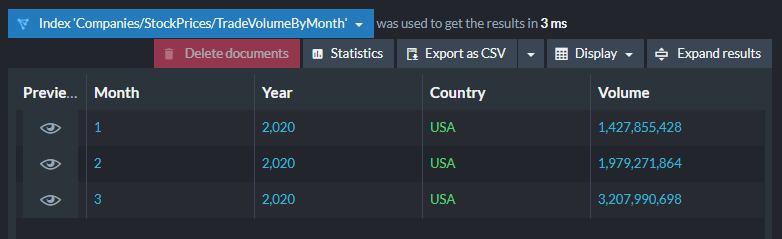
Since the data is already indexed, RavenDB can return results in milliseconds even with JavaScript date manipulation in the projection.
Time series support is an exciting feature that takes full advantage of RavenDB’s powerful indexing capabilities to provide a fast, scalable solution that can support many new use cases.
Scheduled Document Refreshing
RavenDB 5.0 introduces the ability to schedule a periodic “refresh” for documents that use a special @refresh metadata property.
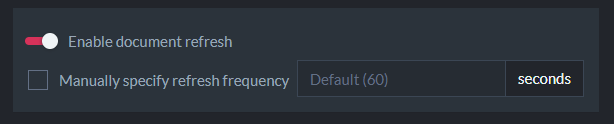
RavenDB will check on an interval for any documents containing the @refresh metadata tag and if the refresh date has passed, it will remove the tag which will trigger document reindexing as well as any ongoing tasks like ETL, subscriptions, or replication.
For example, when you buy an item on Amazon, your order moves between different states. One of the first states might be a ProcessPayment state. If the payment processor fails, perhaps due to an issue at the bank, you could add a @refresh tag indicating when to automatically retry and track how many times it’s been retried. If it passes a certain amount, you could notify the user their order is unable to be fulfilled or stop the order until they update their payment method.
To achieve this with RavenDB alone, you would set up a data subscription on your order documents and filter by the ProcessPayment order status. You could then set the @refresh metadata property when an order failed to process a payment:
var orderProcessingSubscription = await store.Subscriptions.CreateAsync(new SubscriptionCreationOptions
{
// Find orders that need to be processed. If they have a @refresh metadata tag,
// they will be retried in the future so skip over them.
Query = @"
from Orders as o
where o.Status = 'ProcessPayment'
and not exists(o.'@metadata'.'@refresh')"
});
var orderProcessingWorker = store.Subscriptions.GetSubscriptionWorker(orderProcessingSubscription);
_ = orderProcessingWorker.Run(async batch => {
using var session = batch.OpenAsyncSession();
foreach(var order in batch.Items.Select(x => x.Result))
{
// Cancel order if we've tried too many times to
// process the order with a failed payment method
if (PaymentProcessor.HasExceededRetries(order))
{
await NotifyUserOfExpiredGracePeriodOfOrderPayment(order);
await WorkflowProcessor.TransitionToCanceled(order);
continue;
}
try
{
await PaymentProcessor.ProcessPayment(order);
await WorkflowProcessor.TransitionToFulfillment(order);
}
catch (PaymentProcessorException ppex)
{
// Increment failure count
order.FailureCount = order.FailureCount + 1;
// Try to process again in 24h
session.Advanced.GetMetadataFor(order)["@refresh"] = DateTime.UtcNow.AddDays(1);
// Send user a notification
await NotifyUserOfFailureToProcessPayment(order);
}
}
await session.SaveChangesAsync();
});
In this example, we have set up a data subscription listening to a query that filters orders by the ProcessPayment status and that have a @refresh tag on them for retrying. A subscription can receive a batch of documents at once, so this snippet iterates through each one and attempts to make a payment. If it fails we set the @refresh metadata tag to 24 hours in the future.
When RavenDB checks again for any order documents that need to be refreshed after that 24 hours passes, RavenDB will remove the @refresh tag on the document and this subscription will be triggered once again. Once a maximum number of failures is reached, we can choose to notify the user and cancel the user or take any other sort of action we need to.
It’s worth noting that even though we save the document, this subscription is not triggered immediately again (creating an infinite loop) because RavenDB is tracking the fact that we modified an incoming document during the batch process.
Effectively we’ve scheduled future work using only the document refresh feature rather than a custom scheduled job. Since subscriptions are long-lived and can be paused/resumed, we also have some resiliency baked in by default.
Document Compression
In RavenDB 3.5, there was the ability to compress documents by using the Compression bundle. In RavenDB 4.0, many bundles were moved into the core of the product but compression was not included. As of RavenDB 5.0, Compression has found its way back in and is even more configurable than before. Compression is a way to save on disk space and storage costs by allowing you to choose to compress document collections in a database:
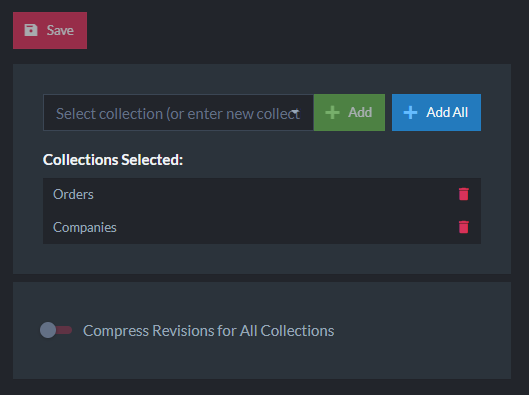
Unlike the 3.5 Compression bundle which was restricted to new databases only and could not be turned off once enabled, the new 5.0 feature allows full control over which collections to compress and the ability to remove compression anytime. You may even choose to compress all the revisions for the database as well.
The compression process learns over time and adapts to your data. Even with small documents, storage reductions of over 50% have been observed. This will save space used on disk but requires extra CPU power when loading or saving documents. This can improve performance but may use more CPU in return for the boost. In a cloud-hosted environment with limited CPU cores, this may result in extra burstable CPU load that could add extra costs which is why this feature is not enabled by default. It’s worth noting that indexes are not compressed so there is no additional overhead to querying stored index fields.
Additional New Features
New Load Balancing Behavior
RavenDB 4.0 introduced powerful cluster capabilities with the ability to perform load balanced reads from nodes in the cluster. However, there was no option to tell RavenDB which node to choose when doing writes. It would always choose the preferred node for all writes.
In RavenDB 5.0, a new LoadBalanceBehavior convention is available that allows you to customize load balancing behavior for reads and writes:
- None – This is the same behavior as 4.x, the write will be against the preferred node and reads will use the value set by
ReadBalanceBehavior - UseSessionContext – Reads and writes will be done in a round-robin fashion, using the next available node in the cluster topology each time a session is opened
Learn more about Load Balancing and Failover conventions.
Add Custom Sorters Within Studio
When querying data in indexes, there are built-in ways to sort fields such as by date, number, alpha-numeric, or spatial ordering. In order to support custom Lucene sorters, you needed to invoke a maintenance operation from code and you could not specify custom sorters when querying in the Studio.
In RavenDB 5.0, you can now add custom sorters via the Studio UI by pasting in the code or loading from a file:
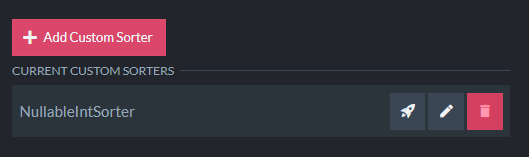
This uses a slightly modified version of the NullableIntComparator found on StackOverflow, as an example.
You can then test the custom sorter within a query using RQL’s custom function:
from index 'Orders/ByCompany'
order by custom(Count, "NullableIntSorter") desc
ES2016 Support for JavaScript Indexes
RavenDB 5.0 ships with an upgraded JavaScript language engine which means JavaScript indexes can take advantage of more expressive ES2016 (aka ES6) language features such as spread, destructuring, and arrow functions:
map("Orders", ({ Lines, Employee, Company }) => {
const Total = Lines.reduce(
(acc, l) => acc + (l.Quantity * l.PricePerUnit) * (1 - l.Discount), 0);
return {
Employee,
Company,
Total
}
})
You can read more about which ES6 features are supported in the underlying engine RavenDB 5.0 uses.
Summary
In addition to the features laid out above, there are a host of other fixes and enhancements such as a new JavaScript serialization layer that further improves performance and stability across the board.
For the full breakdown of all the changes and fixes included in RavenDB 5.0, see the What’s New documentation.
Woah, already finished? 🤯
If you found the article interesting, don’t miss a chance to try our database solution – totally for free!

