 Skip to Navigation
Skip to Navigation
High Availability Database Clustering Strategies

How RavenDB can help mitigate networking issues using different availability strategies and their trade-offs, with each one successively mitigating against larger and more catastrophic network disasters.
As a baseline, RavenDB installations should follow the OS configuration and network/firewall settings guides for more detailed configuration related to networking.
Table of contents
Low Availability Strategies
Low availability means that RavenDB may be able to maintain read and write access to the database during a disaster scenario but will not maintain availability for all features like cluster-wide operations.
This can be a viable strategy for non-production environments when business continuity is not a critical factor. The two main topologies in this group are single and dual server clusters.
Single Node Cluster
Most applications start with a single node topology. RavenDB runs a single node as a “cluster” and it can work well for sandbox or development environments.
While developing, you do not have to run RavenDB on a dedicated server, you can run in Embedded mode within your application. This is not only useful for integration tests but can speed up development iteration. When working on a team, you may be redesigning indexes or making other changes that would affect the database. By embedding RavenDB within your development workflow, failures are localized to each developer’s environment instead of affecting the overall team or integration environment.
A single node cluster can be used for production deployments but this would not be “highly available” because it is a single point of failure. If something happens to the server, you will not be able to communicate with it until it’s back up.

Primary/Secondary Cluster
To add another layer of redundancy, you can opt for a “primary/secondary” or “active/active” topology. In this configuration, the primary database will handle the majority of traffic and the secondary will replicate the changes. If a single node fails, the other will be able to serve requests since it’s still an active member of the cluster.
In a cloud-hosted solution, a primary/secondary cluster would likely be set up within a single “availability zone.” Availability Zones are physically separate locations that may have one or more data centers. These zones are tolerant for failures that would bring down a single AZ. In the case of a data center failure, the AZ has a higher chance of staying available.

It’s important to understand that an issue affecting an availability zone will cause downtime for all the zone’s data centers. To reduce the chances of downtime in a dual node cluster, each node should be in a different availability zone, not just a different data center. RavenDB clusters use distributed consensus for majority voting and if one of the nodes fails, you will not be able to perform some consensus-based operations like creating and deleting databases or indexes.
Since it’s more common to read and write, as long as there’s a single node available, RavenDB will still serve your end-user requests maintaining availability.
These “low availability” strategies will work fine in many circumstances but when you’re planning for a catastrophic disaster you’ll want to consider a more complex high availability strategy.
High Availability Strategies
Multi-Availability Zone Deployments
The recommended cluster topology is the 3- or 5-node topology which achieves a high-level of redundancy. Distributed consensus among nodes requires an odd-number for proper decision making in the case of failures which you can read about in-depth.
The most common deployment strategy for RavenDB is a single-region “multi-availability zone” configuration. This means that within a single region such as the East US, the cluster is split across availability zones.
For the majority of deployments, this configuration will work well. It will be resilient to many types of network failures and AZs within a single region have low network latency between them.
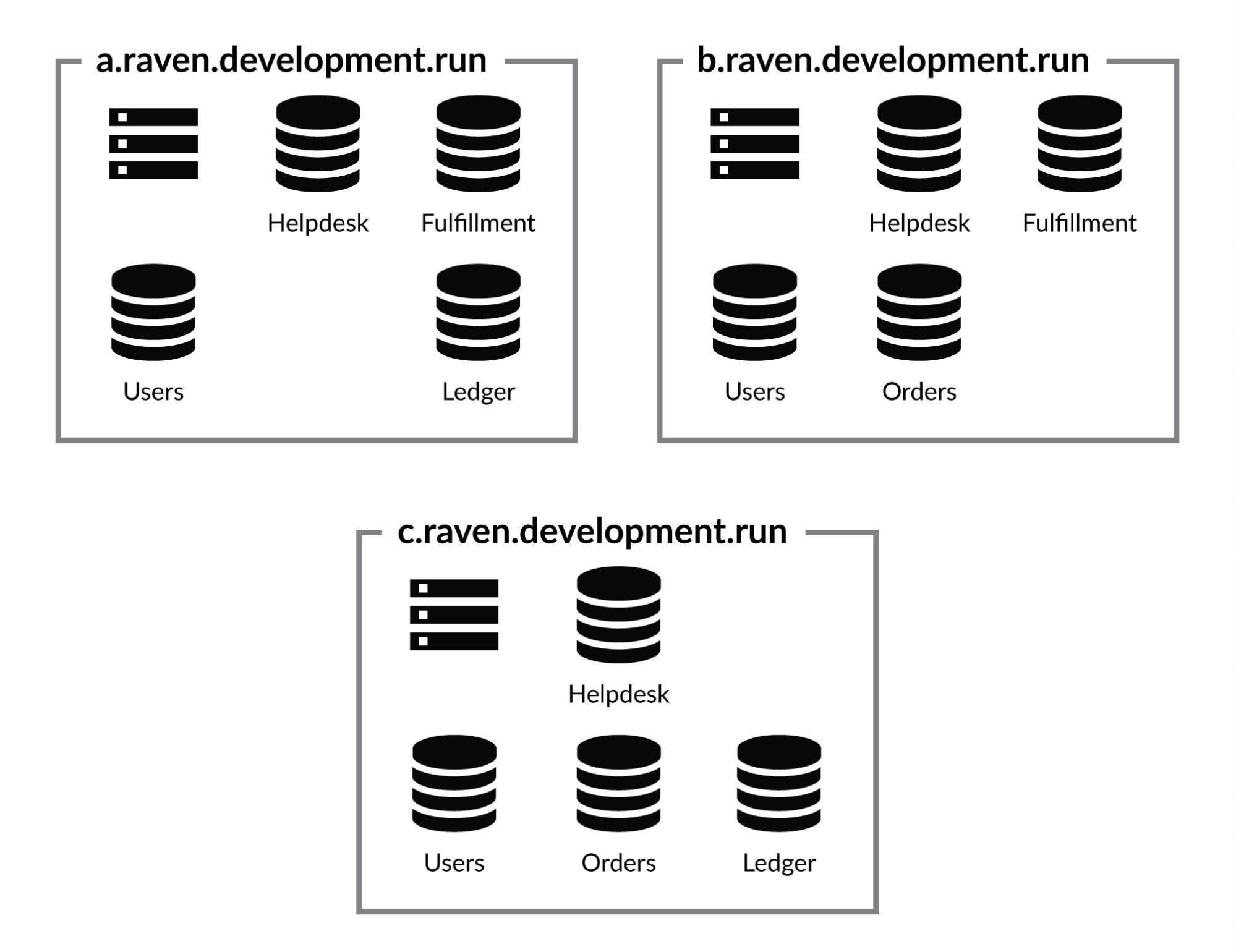
Databases can be replicated to a desired number of nodes for redundancy. Clients will failover automatically to an available node in the cluster. If a single node goes down, it will not affect availability at all. The Cluster Observer will intelligently mark the database as unreachable and the topology will dynamically update to redirect traffic to healthy nodes. Once the node comes back online, RavenDB will wait until replication has caught up before allowing traffic back to the node.
This is why a multi-node cluster performs very well during disasters. Even in a full-blown catastrophe where only a single node remains online, reads and writes will continue to flow allowing users to have uninterrupted service.
Multi-Region Deployments
For enterprise-scale applications, one strategy is to deploy the application across multiple geographic “regions,” like New York and London. A region in a cloud provider encompasses many different data centers and availability zones. This deployment strategy mitigates widespread issues within a region, keeping the database available and your application running uninterrupted.
RavenDB supports multiple isolated clusters through external replication. While a common scenario is to replicate data from RavenDB to an external database like SQL Server, you may also replicate one-way to another RavenDB server outside the cluster.
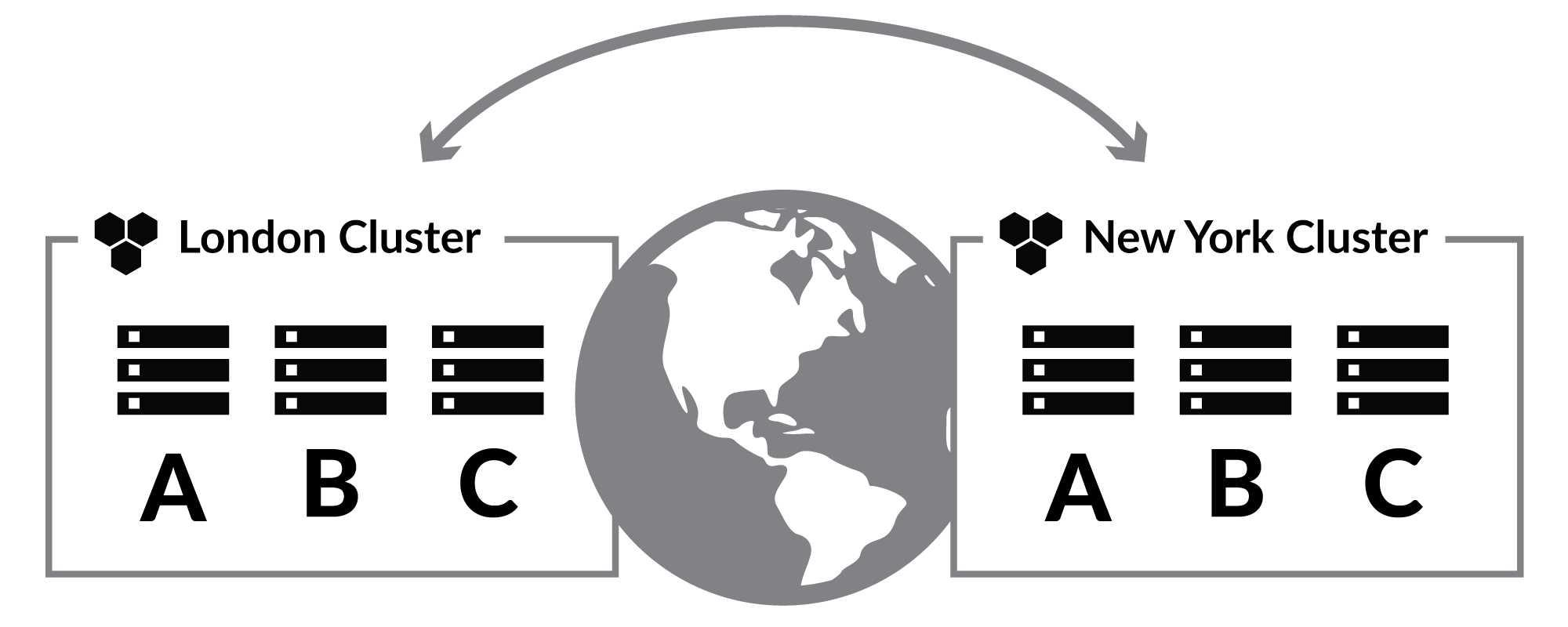
This type of configuration can be useful when distinct geographic regions need more control and to minimize latency between your RavenDB servers and application servers within those regions. For example, if you need to handle having a US and EU distributed application.
It’s important to note with this configuration that external replication has to be configured one-way from each side to enable bi-directional sync, application servers will not failover to the other cluster automatically, and some aspects of the database are not replicated (such as indexes and settings).
Since uniqueness can only be ensured within a cluster using interlocked compare-exchange operations, you must pick one cluster to act as the source of truth for this information. For example, data privacy laws like GDPR may dictate that a business must store EU customer records in the EU. If something happens in the London region where those cluster operations fail, EU users will not be able to sign up while the US-based application will remain available. This has to be planned for and designed around.
Multi-Cloud Deployments
It’s not unheard of for a cloud provider to have widespread outages across regions. For massive-scale applications, you can consider a “multi-cloud” deployment to add provider redundancies.
This requires complex automation that can span across multiple cloud providers. For example, if AWS goes down, database and application servers in Azure could take over as backup. To achieve this, you would likely rely on infrastructure-as-code and use automation tools like Ansible, Docker, or Terraform that are cloud-agnostic. You could not rely on any manual operations that required access to the AWS console because that may be unavailable.
Since cloud providers are not free, to save on resources you may choose not to activate the servers in another provider until an emergency event (a “hot standby”). You should set up the RavenDB servers as cluster members initially. It would be recommended to set up a single-node cluster as an external replication target. In case of emergency, you can then add other servers to the cluster as needed.
At the same time, applications would need to be able to communicate with the emergency cluster using different certificates and connection strings than the primary cluster, which could be accomplished by externalizing config and restarting the application cluster.
To achieve this level of extreme redundancy requires a highly sophisticated set of automation infrastructure at every level of the stack. But if you’re Netflix, this complexity may be worth it when you have plenty of reasons for achieving zero downtime.
Conclusion
Since transient network failures are a common occurrence, it’s important to have redundancies in place at each layer in your stack. For your database layer, RavenDB supports different availability strategies that can grow and scale with your business. Anyone can get started with a free Community license that allows you to deploy a full production cluster with up to 3 nodes.
For more in-depth coverage of commonly used cluster topologies, deployment recommendations and strategies based on the case studies we’ve seen with our customers, be sure to read the Production Deployments section of the Inside RavenDB book.
Woah, already finished? 🤯
If you found the article interesting, don’t miss a chance to try our database solution – totally for free!



