
NoSQL Data Model Through the DDD Prism
The Yet Another Bug Tracker (YABT) we’re building in this series is a simplified version of a bug-tracking tool that implements some basic functionality. In spite of its simplicity, we leverage the Domain-driven Design (DDD) to describe independent problem areas as Bounded Context, emphasize a common language (Ubiquitous Language) to talk about these problems, and also adopt technical concepts and patterns, like rich models, aggregates, value objects, etc.
But this article is not about the DDD, so for more information refer to the gurus:
- Vaughn Vernon, “Domain-Driven Design Distilled” and “Implementing Domain-Driven Design“
- Eric Evans, “Domain-driven design“
- Martin Fowler, his blog at martinfowler.com
Luckily for the YABT, the bug-tracking domain is well-known to any dev and well-covered by Vaughn Vernon in his books that is a good source for deeper understanding of our design decisions.
1. Bounded context and Domain entities
The core model of a bug-tracking system would consist of a Project, Backlog Item, its Comments and of course Sprint. Each project has a Team linked to Users of the system that may bring other entities like subscriptions, payments, permissions, etc.
While the core entities are related to the Scrum processes, Users normally would stay outside of the bounded context as they are tightly coupled with permissions and tenants that have little to do with Scrum. So it leads us to two bounded contexts:
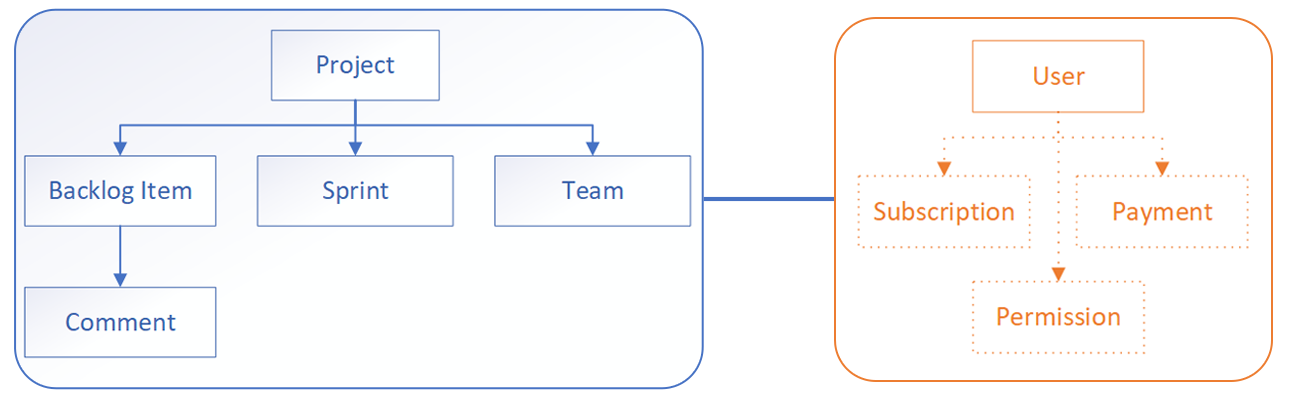
There is a good practice:
Implement one database per Bounded Context to avoid a monolith architecture.
So, to make the YABT simpler, we cut off auxiliary functionality (like user registration, subscriptions, etc.) and implement only the main bounded context. This way we have settled on the following entities:
- Backlog Item – basic properties of user stories, bugs, features, etc.
- Custom Field – to spice things up we’re adding Backlog Items custom properties managed by the user.
- Comment – discussions on individual Backlog Items.
- Sprint.
- Project – for grouping Backlog Items, Sprints and Users, and providing a context for the user’s session.
- User – represents team members for Projects, registered users with rudimentary user management.
2. Relational DB model
Before jumping to the database design, let’s step back and talk about how the database could look like if we were using a conventional SQL database. This step is not required for designing a DB, and here it’s shown purely for academic purposes.
Wiring up the entities listed above we get a normalised relational model:
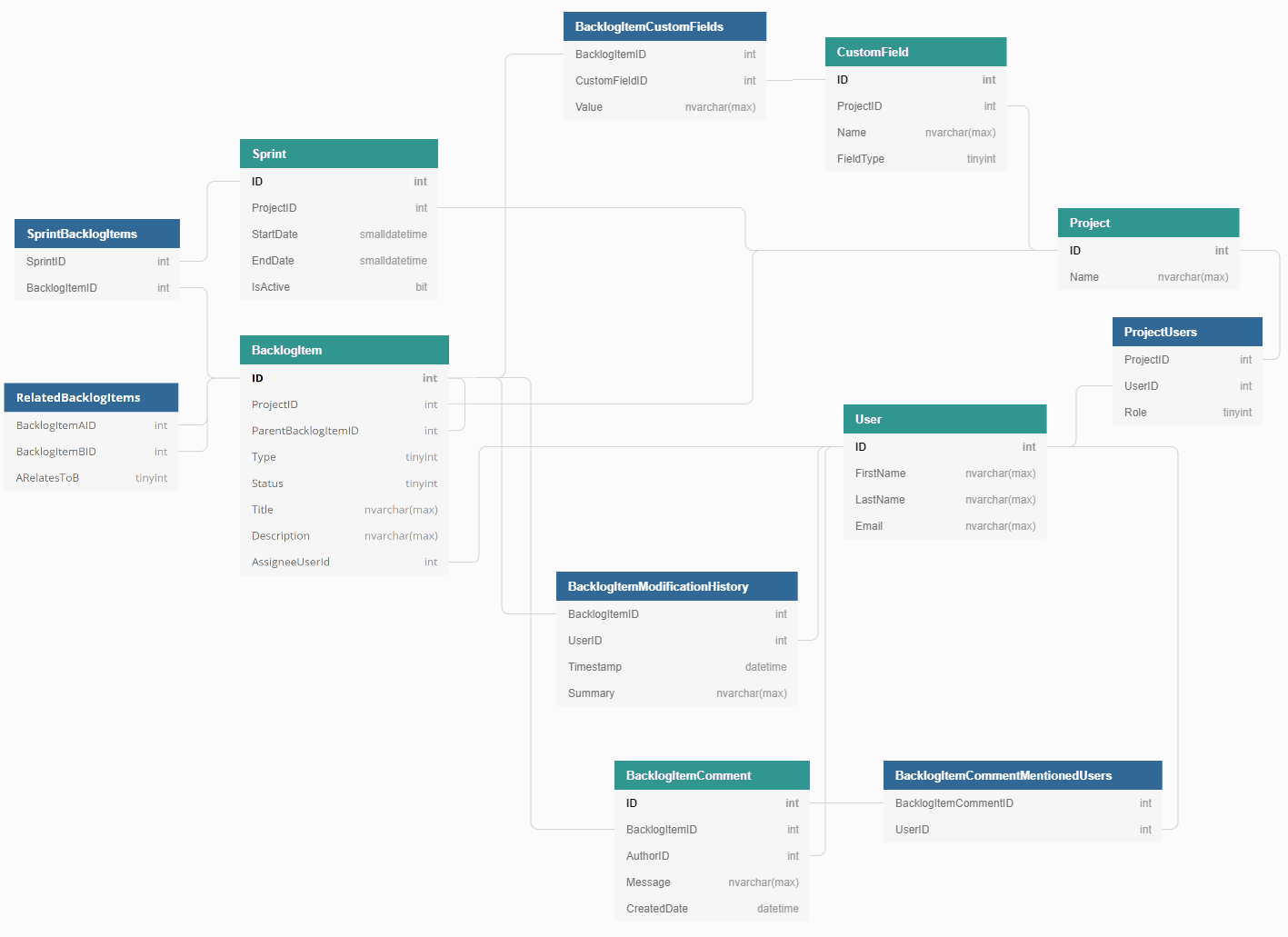
See an interactive version at dbdiagram.io.
The main entities are highlighted in green and their fields are self-explanatory. However, some of the relationships between the tables need to be explained.
[ProjectUsers]reflects roles of the users in projects.[RelatedBacklogItems]stores relationships between Backlog Items when some are “blocked” by others or “related” to others. Meanwhile a parent-child relation between items is maintained in[ParentBacklogItemID]field of[BacklogItem].[BacklogItemModificationHistory]answers who? when? did what? on a specific backlog item. Backlog Item attributes likedate of creationandlast modification datewill be resolved from this table.[BacklogItemCommentMentionedUsers]stores references to the users in the comments (like “@HomerSimpson please test the functionality“), so we could query Backlog Items requiring attention of the current user (Homer Simpson in this case).
Note that the ER diagram shown above is simplified and a few things were taken out:
- Secondary fields in the tables. Even a basic set of fields for
[BacklogItem]would be much richer to support different item types: features, user stories and bugs. - No reference tables for the supported types of Backlog Items (already mentioned features, user stories and bugs), user roles in the projects (e.g. admin, ordinary member), types of relationship between Backlog Items (e.g. blocker, related), etc.
Clearly that the final ER diagram for a such simple database would be much more cluttered, but you get the picture.
3. NoSQL model
3.1. Need in DB structure
Do we need a DB structure/model when it comes to NoSQL? Well it depends. You may get away without a model if you are a data scientist and dumping terabytes of data for future analysis. However, an enterprise developer needs to know how to present the data (on the API or UI) and how to query the data. And it’s the case for the YABT.
Of course, in NoSQL a structure can’t be implemented just at the database level. JSON records are flexible and there are no data integrity checks. Therefore, NoSQL relies on rules and constrains implemented in the domain logic. It leads to enforcing a good practice:
Prevent direct access to the DB by the consumers. Always shield the DB with a domain layer as a way of enforcing the domain rules and constrains.
Overexposing the database is a common felony in the SQL realm.
3.2. Constructing aggregates
Above, we have prepared a foundation with a strategic design called Bounded context. Now it’s time for tactical design to define details of the domain model. We need DDD aggregates that will reflect our denormalised database.
The key properties of aggregates:
- Aggregates are the basic element of transfer of data storage – you request to load or save whole aggregates.
- Any references from outside the aggregate should only go to the aggregate root.
Properly structured Aggregates reduce JOINs in queries that deteriorate the performance and add fragility for eventually consistent references.
Jumping to the final diagram, we get this:
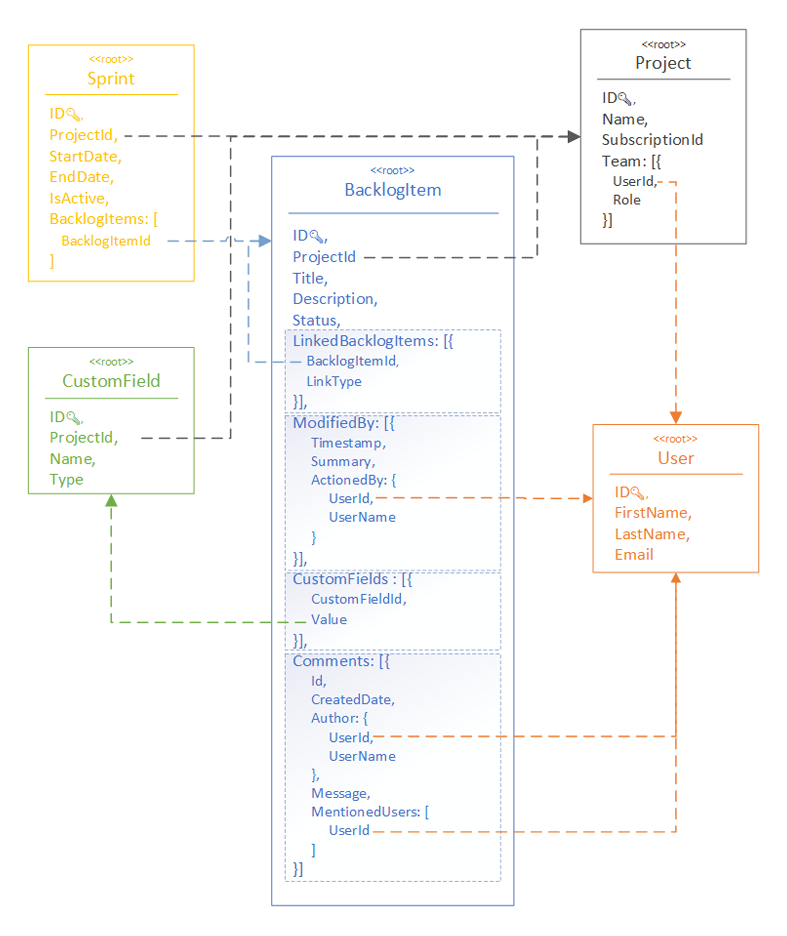
Note: For simplicity, this diagram doesn’t show all the fields of the final aggregates.
As you see, the BacklogItem aggregate is quite rich with many nested collections:
LinkedBacklogItemsrepresents dependencies to other Backlog Items (parent/child, related, blocked, etc.).ModifiedByhas a history of all modifications of the Backlog Item. Whenever a user changes a value of field, links to another item, writes a comment, etc. a record will appear in this collection.CustomFieldshas values of custom fields specified by the user.Comments–- as a part of the Backlog Item, they will never be queried or edited independently, or referenced outside of the Backlog Item.Commenthas a collection of mentioned users that will play its role on querying Backlog Items requiring attention of the current user.
All the 5 aggregates have references, and you may have noticed that in some cases it’s just an ID, in others it’s a bundle of 2+ fields (e.g. ID and Name). There will be a separate article on managing references between aggregates, but as a rule of thumb:
- If a reference is used for filtering only, then an
IDis sufficient. - If a reference is going to be exposed to the consumer along with some fields of the referred entity, then those fields need to be included into the reference. This way we avoid excessive
JOINs in queries (e.g. the comment’s author hasIDandNamethat duplicates the name of the referredUserrecord).
3.3. Convenience of using RavenDB
Many NoSQL databases have a very modest limit on the document/record size that could affect the decision of bringing the Comments inside of the BacklogItem aggregate. While usually we should expect less than a dozen of comments with the total size in KB rather than in MB, a production system shouldn’t shy away of a couple of megabytes of comments. And it’s not a concern for RavenDB. Though, technically the document/record can be up to 2GB, the optimal size should stay in megabytes that still is more than enough for a BacklogItem with hundreds of comments (that admittedly would be a rare case). Another limitation of some NoSQL vendors is inability of querying a subset of fields forcing the developer to fetch whole records. It can pose a performance concern if unnecessary fields are heavy, like for our common request of listing 3-4 main fields of Backlog Items and omitting potentially bulky comments. RavenDB gives a way of grabbing only necessary fields.
Another common concern that may affect the database model is immature indexes preventing certain filtering, grouping and data aggregation. Well, RavenDB has got your back here and we will consider various scenarios involving indexes in the YABT series.
That’s it.
Check out the full source code at our repository on GitHub – github.com/ravendb/samples-yabt and let us know what you think. Click the link below to read the next article in the series!
Read more articles in this series
Woah, already finished? 🤯
If you found the article interesting, don’t miss a chance to try our database solution – totally for free!


