
Building an enterprise application with the .NET Core and RavenDB NoSQL database
NoSQL is not hard, it’s different. And to show that, RavenDB and I kick off a new series of articles dedicated to building enterprise applications leveraging the .NET Core + RavenDB bundle.
We want to give as much of practical knowledge as possible, so let’s build a real-ish enterprise solution and explain various interesting aspects in the articles along the way. Of course, making everything open source and under the MIT license. The solution will show not only the database part but also domain services, tests, API and the front-end. The goal is to show how various DB features play out all the way through the API to the UI.
And we will follow the best practices applying the Domain Driven Design (DDD), the Onion Architecture, Command Query Responsibility Segregation (CQRS), etc. and more importantly Common sense 😉 to keep the project simple and pragmatic.
Case Study
We may come from different experiences and backgrounds but all developers are familiar with bug tracking systems, a necessary evil of the contemporary software development. We know the domain, the ubiquitous language (“backlog”, “sprint”, “project”, etc.), how such systems get consumed by the end-user. Eventually we did not have much of a choice on what our intended application would do 🙂 and here we go – our project is one more solution for a well-known problem and it’s called “Yet Another Bug Tracker”.
The source code is available at github.com/ravendb/samples-yabt.
Once again, the solution is not meant to be commercially viable, but rather be a convenient example helping the developers in building other enterprise solutions.
Domain Model
The bug tracker domain is quite popular among the DDD gurus and well-covered by Vaughn Vernon in his books. I will conveniently refer to his book “Domain-Driven Design Distilled” for explanation of the domain model (structuring entities and aggregates).
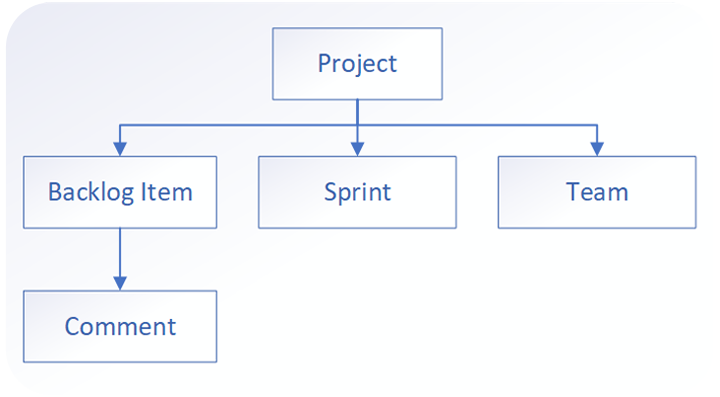
We start off with a simple model (like on the diagram below) and will add more entities and aggregates later. It will be all about the Backlog Item aggregate with various related entities like Project, User/Team, Sprint etc.
Architecture/Software design
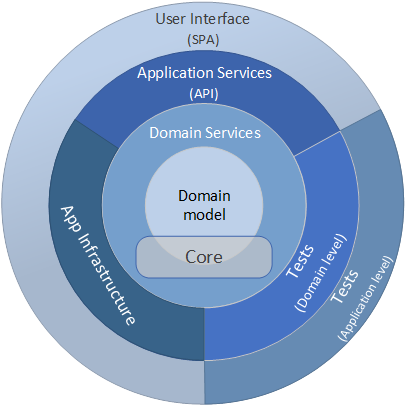
The architecture of the YABT project is based on the Onion Architecture to avoid known structural pitfalls, such as undesired dependencies between layers and contamination of the externally facing layer (e.g. API or UI) with business logic.
While the YABT has some deviations from the classic Onion Architecture, it definitely follows the key tenets:
- The application is built around an independent object model.
- Inner layers define interfaces. Outer layers implement interfaces.
- Direction of coupling is toward the center.
- All application core code can be compiled and run separate from infrastructure.
Our diagram has some resemblance with the classic Onion diagram:
Sure thing, the YABT follows the SOLID principles. It’s by default.
Check out the source code of the YABT. Let us know what you think. Click the link below to read the next article in the series!
Read more articles in this series
Woah, already finished? 🤯
If you found the article interesting, don’t miss a chance to try our database solution – totally for free!


