 Skip to Navigation
Skip to Navigation
Data Loss Prevention and Data Recovery

How to prevent accidental loss of data and how to bring your application back online with RavenDB.
In this series we’ve previously covered preparing for disasters with availability strategies, optimizing hardware performance, and how different read/write strategies affect application availability. In this article we’ll present some strategies for how to prevent accidental loss of data and how to bring your application back online in the rare case that it happens.
Table of contents
What Does it Mean to “Lose” Data?
RavenDB was designed to ensure data consistency which means it can provide guarantees that data was stored where some other products cannot make those guarantees. Due to its transactional architecture, RavenDB will never give the false notion of data being written when it hasn’t. It would be extremely rare to “lose” data on disk, especially if you are running in the cloud where storage is durable. Even so, human error and on-premise hardware failure could both lead to potential loss of data.
Loss by Accident
Whether it’s a patch, script, or migration gone awry, it’s possible that an unintentional error could cause the loss of data if you are unprepared or don’t take steps to help prevent issues. In this case, there is no hardware failure, RavenDB is dutifully carrying out your commands but those commands might not have been what we really wanted. We’ll cover several strategies to help avoid this situation.
Loss by Catastrophic Disaster
If you read the fine print of any cloud host Service Level Agreement (SLA), you will find that the agreement does not cover events outside their control such as natural disasters, power outages, or war. Although it can happen, the likelihood these events would affect your database are rare. However, by ensuring your solution is designed to be highly available and implementing the strategies in this article, you can still make it through these events without incurring data loss.
Loss by Disk Corruption
RavenDB guarantees writes to disk so the only way data on disk can be lost is when the underlying hardware has an issue that corrupts the data files (e.g. a bad sector). When running on cloud-based infrastructure, it’s safe to say this scenario should never occur. Storage disks that are attached to virtual machines are extremely durable, backed by many layers of redundancy. However, for local machines or hard disks on-premise, this rare event can happen and there are ways to recover from this we’ll touch on.
How Does RavenDB Help Prevent Data Loss?
Write Ahead Journal
RavenDB uses a custom-built storage engine called “Voron” that helps guarantee data is written to disk. It uses a Write-Ahead Journal (WAJ) that guarantees data is committed before successfully finalizing a transaction. This means data is never “lost” in-transit; instead the transaction will fail and will be rolled back, always leaving the database in a consistent state. The application can always be assured the data was written and committed to disk if a transaction succeeds.
Asynchronous Replication
In a cluster, replication helps prevent data loss by ensuring data is replicated asynchronously through the cluster. Replication latency is very fast amongst cluster nodes, on the order of milliseconds. Each database can define a “replication factor” which specifies how many nodes the database should be spread across. Using write assurance, you can even wait until replication reaches a desired number of nodes before finalizing a transaction.
When a node suffers a transient failure and becomes unreachable, RavenDB automatically manages the replication of a database to ensure availability across nodes and can restore the state of the database when the node comes back online. If a node is unreachable for a longer period of time RavenDB will stop trying to rebalance automatically while surfacing an alert to take action.
Strategies to Plan Ahead
Even though RavenDB attempts to do its best to prevent data loss, manual errors or catastrophic failures can still occur and it’s best to be prepared. There are several strategies you can use to make sure you’re ready to react to a disaster scenario.
Set Up Full and Incremental Backups
RavenDB has built-in backup tasks that can perform full, incremental, or snapshot backups to the file system or an off-site location like Amazon S3 or Azure Blob Storage. Snapshots are faster to use to recover data but they are only available for Enterprise licenses.
These backup tasks can be scheduled at different intervals. It is recommended for a production deployment to perform regular full backups and incremental backups at smaller intervals. You can choose to only retain full or incremental backups for a limited time to aid in data recovery or auditing.
Don’t Forget to Backup Your Encryption Key
If you are using encryption at rest with RavenDB, your key will not be backed up since it is supposed to be a secure secret that should be heavily guarded.
Securing your key may vary depending on your organization but our customers typically use Hashicorp Vault, Azure KeyVault, Keywhiz or some other secrets-management product. These products can also implement key rotation to ensure that keys are rotated every so often which prevents old keys from being used to decrypt critical data. Lastly you could resort to printing it out on paper and storing it somewhere safe but this obviously cannot be automated and has the lowest accessibility of all.
You’ll need ready access to your key in case of emergency to restore from backup.
Lock the Database to Prevent Database Deletion
If a database is deleted (whether on purpose or by accident), RavenDB will dutifully remove it from all nodes and all your data will be lost.
The best approach is to prevent deletion in the first place by locking the database. You can use the Studio databases list view to prevent deletion of the database to protect against human errors:
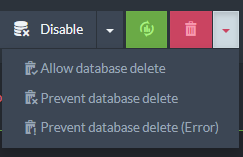
You can also modify these settings programmatically using the /admin/databases/set-lock REST endpoint. This setting can only be changed by someone with operator-level permissions and all users are prevented from deleting the database when it has been locked.
The two prevention options tell RavenDB to either ignore database delete operations (log-only) or to throw an error which the application or client will need to handle.
Consider an Offsite Replica
Restoring from backup works well in catastrophic disasters but that takes time and can be out-of-date from a live database. RavenDB also supports using external replication to enable you to create an offsite replica. Database deletion operations are not sent through external replication. This way, you can quickly recover a live database if it is lost within an actionable timeframe.
If you enable delayed replication, this would enable you to restore data within a short timeframe if it was accidentally modified in your primary cluster.
If you are using the multi-cluster topology mentioned previously, both clusters act as offsite replicas for each other. If all you need is a backup replica, a single node will suffice.
Consider High Consistency Writes for Critical Data
In a previous article we covered different write strategies that favor consistency over availability. For example, using a cluster-wide transaction for high-value writes would rollback changes if the transaction failed to achieve majority consensus from nodes. When not using a cluster-wide transaction, you can use write assurance to wait for replication after calling SaveChanges(). This ensures that if a node had to be restored from backup, the high-value data would be guaranteed to be replicated elsewhere on another node and it would be restored once the failed node came back online.
Recovering From Data Loss
In the event you suffer data loss, the previous strategies will enable you to have more options to reliably recover from loss.
Wait for Replication to Resume
The fastest and easiest way to recover data in the event a single node suffers data loss, is by waiting for replication to resume. This process will happen automatically as long as the node can be brought back online. Once the node becomes reachable by cluster members, replication will resume and restore the database to the latest state.
Restore From Backup, Snapshot, or Offsite Replica
As long as you are keeping backups or snapshots, you should be able to restore the database to a known good state. You can do this through the Studio UI or through the RavenDB CLI.
You can choose the last backup created before the event to restore. In the time between the last backup and the disaster, it’s possible data was written to the database that will not be backed up. If this is a single node, the other cluster members will be able to replicate any changes since that point.
In catastrophic scenarios where most nodes are missing data (such as a region-wide or data center outage), taking a full backup of the off-site replica can help restore the database to the last point where external replication succeeded.
Recover Data from Corrupted Databases
In rare circumstances it’s possible that the underlying data structure of the database can become corrupted. For local on-premise hard drives, enough bad sectors may cause this. In this scenario, RavenDB will try its best to keep the database online. First it will block writes to prevent the spread of the corruption but read traffic will still be allowed. Then, the database will be reloaded automatically up to three times. If it cannot be fully recovered after the third attempt, the database is marked in an error state and an alert is raised. This allows you to monitor and acknowledge the alert to replace the failed disk without bringing down the entire database.
If the data you need to recover cannot be replicated from another node, you can try to use the specialized Voron Recovery tool which will examine each byte of the database state and create a dump file you can then use to recreate the database. It will also include all the errors the tool ran into.
It is unlikely you would use this partially-recovered database in production but it may be the only option if you cannot recover data using one of the previous methods.
Recover from Corrupted or Lost Certificates
RavenDB uses certificate authentication instead of username/password authentication. Since certificates are files on your machine (or a remote node), they can also be subject to accidental deletion or corruption. It would be wise to maintain backups of administrator certificates and keep in mind they should be treated securely as “password equivalents.”
If an administrator certificate is lost or corrupted, you will not be able to manage RavenDB through the Studio interface to issue new certificates.
Instead, you can connect to the server with your root user and re-generate new cluster administrator certificates (or trust an existing server certificate) using the RavenDB Admin CLI.
Conclusion
RavenDB’s transactional nature ensures data is consistently written to disk but it’s always a possibility that data can be corrupted due to underlying storage failures, whether through a disaster or accidental error. By planning ahead and being prepared, you will have a higher likelihood to recover from a disaster with all or most of your data intact.
For a deeper dive into how to troubleshoot production systems, you can refer to Disaster Recovery Strategies from the Inside RavenDB book.
Woah, already finished? 🤯
If you found the article interesting, don’t miss a chance to try our database solution – totally for free!



