 Skip to Navigation
Skip to Navigation
Scaling Distributed Work in RavenDB
In the previous chapter, we covered a lot. We went over how RavenDB clusters and database groups work. We looked at the nitty-gritty details, such as conflicts and change vectors. And we saw how a cluster can handle failover and recovery. But we haven't talked about how to actually make use of a cluster. This is primarily what we'll cover in this chapter: how to properly utilize your RavenDB cluster to best effect.
We'll cover how to grow your cluster to include a large number of nodes, how to host a lot of databases in the cluster, how we can automatically have the cluster adjust the nodes a database resides on, which will ensure a minimum number of replicas, and how we can deploy RavenDB in a geo-distributed environment.
But first, we need to go back a bit and discuss the distributed mechanisms in RavenDB — the cluster and the database group. The separation RavenDB makes between a cluster and a database group can be artificial. If you're running a single database on all your nodes, you usually won't make any distinction between the cluster as a whole and the database group. This distinction starts to become much more important if you're working in a system that utilizes many databases.
The simplest example for such a system is a microservice architecture. Each microservice in your system has its own database group that's running on the cluster, and you can define the number of nodes each database group will run on. This tends to be easier to manage, deploy and work with than having a separate cluster per microservice.
Another example of a situation where you'll have multiple databases is multitenancy, where each tenant gets its own separate database. This makes it simple to deal with tenant separation, and you can adjust the number of nodes per tenant easily. This approach will also allow you to scale your system in a way that's convenient. As you have more tenants, you can just add more machines to the cluster and spread the load among them.
That said, note there's a certain cost for running each database instance. It's usually easier for RavenDB to have a single large database than many small ones. The general rule of thumb is that you shouldn't host more than a hundred or so active databases per machine.
Growing your cluster
RavenDB is using Raft as the underlying consensus protocol for managing the cluster. The Raft Paper is a truly impressive read, mostly because the paper manages to make one of the hardest tasks in distributed programming understandable. I highly recommend reading it, even if you never intend to dig into the details of how RavenDB or other distributed systems do their magic.
The simplest way to explain how Raft works is that the cluster makes decisions based on majority confirmation. This quick explanation does a great injustice to both the algorithm and
the Raft Paper, but it simplifies things enough for us to reason about them without deviating too much from what's really going on. Majority confirmation is defined
as having a particular value on N/2+1 of the nodes, using integer math and assuming that N is the number of nodes. In other words, if your cluster size is
three, then a majority would be two. Any value that was confirmed by any two nodes is considered committed.
Table 7.1 shows the majority calculation for several common cluster sizes. Note that even numbers have the same majority as the odd number following them. Because of that, you'll typically have an odd number of nodes in your cluster.
| Cluster size | Majority |
|---|---|
| 2 | 2 |
| 3 | 2 |
| 4 | 3 |
| 5 | 3 |
| 7 | 4 |
| 9 | 5 |
| 15 | 8 |
| 21 | 11 |
| 51 | 26 |
Table 7.1: Majorities for different-sized clusters
This majority behavior has a few very interesting implications you should consider. First, you'll note that if we had a failure condition that took out more than half of our cluster, the cluster as a whole will not be able to make any decisions (even while individual database instances will operate normally). In a cluster of five nodes, if there aren't any three nodes that can communicate with each other, there's no way to reach any decision.
On the other hand, the more nodes there are in your cluster, the more network traffic will be required to reach a consensus. In pathological cases, such as a cluster size of 51, you'll need to contact at least 26 servers to reach any decision. That's going to impose a high latency requirement on anything the cluster is doing.
In practice, you rarely grow the cluster beyond seven members or so. The cost of doing that is usually too high. At that point, you'll either set up multiple independent clusters or use a different method. The cluster size we considered is for voting members in the cluster, but the cluster doesn't have to contain only voting members. We can just add nodes to the cluster as watchers.
Watchers don't take part in the majority calculation and are only there to watch what's going on in the cluster. As far as RavenDB is concerned, they're full-blown members in the cluster. They can be assigned databases and work to be done, but we aren't going to include them in the hot path of making decisions in the cluster.
Using this approach, you can decide that three or five nodes in your cluster are the voting members and all the rest are just watchers. This gives us the ability to make decisions with a majority of only three nodes while the actual size of the cluster can be much higher. Of course, if a majority of the cluster's voting members are unable to talk to one another (because they're down or because the network failed), then the cluster as a whole will not be available.
What are cluster operations?
We've talked extensively about clusters being down. Actually, we've spent more time discussing it than the time most clusters spend being down. A cluster being down means database operations continue normally but we can't perform any cluster operations. And what are all those cluster operations?
Basically, they're anything that requires us to coordinate between multiple nodes. A non-exhaustive list of these1 includes creating and deleting databases, creating and deleting indexes, handling subscriptions and ETL processes and completing a backup.2
In all these cases, the operations need a majority in the cluster to process. The underlying logic behind all these operations is that they aren't generally user-facing. So even in the event of a cluster going down, you'll be able to continue serving requests and operate normally, as far as the external world is concerned, while your operations teams are bringing up the failed nodes.
Figure 7.1 shows a cluster using three member nodes and two watchers. Node E is the leader, and it's managing all of the nodes. Database instances can be allocated on both member nodes and watcher nodes, but only the member nodes A, B or E can become cluster leaders. If two of them are down, the cluster as a whole will also be down, and you'll not be able to perform cluster operations (but your databases will function normally otherwise.)
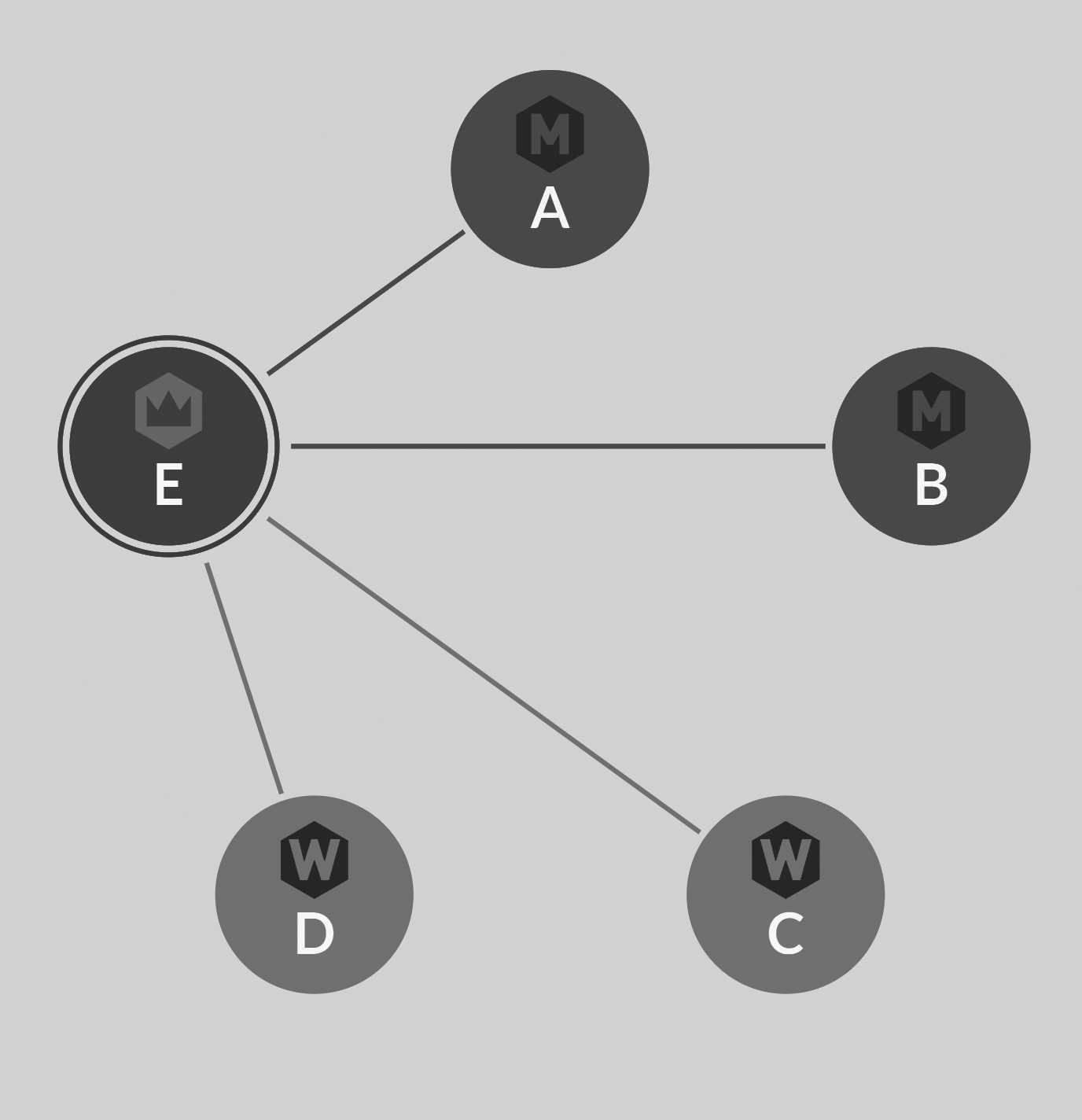
A cluster being unavailable doesn't usually impact ongoing database operations. The actual topology at scale is something the operations team needs to consider. A single large cluster is usually easier to manage, and the cluster can add as many watchers as you need to handle the load you're going to put on it. The databases themselves don't care what node they run on, whether they're voting members or just watchers. And the cluster can manage database instance assignments across all machines with ease.
Multiple data centers and geo-distribution
It's easy to reason about RavenDB's distributed behavior when you're running on the local network or in the same data center, but what about when you have multiple data centers? And what about when you have geo-distributed data centers? Those are important considerations for the architecture of the system. Because there are so many possible deployment options, I'm going to use AWS as the canonical example, simply because there's so much information about it. You should be able to adapt the advice here to your needs easily enough, even if you aren't using AWS.
Inside the same availability zone (same data center) in Amazon, you can expect ping times of less than a millisecond. Between two availability zones in the same region (separate data centers3 that are very close by), you'll typically see ping times that are in the single-digit millisecond range.
Each node in the RavenDB cluster expects to get a heartbeat from the leader every 300 milliseconds (that is the default configuration). When running in the same data center, that's typically not a problem unless there's a failure of the leader (or the network), in which case the cluster as a whole will select a new leader. However, what happens when we start talking about geo-distributed data centers? Let's use Table 7.2 as a discussion point.
| Data center | Tag |
|---|---|
| N. Virginia | us-east-1 |
| Ohio | us-east-2 |
| N. California | us-west-1 |
| London | eu-west-2 |
| Singapore | ap-southeast-1 |
Table: A few AWS data centers and their locations
Ping times4 between these data centers are quite different. For example, N. Virginia to Ohio is 30 milliseconds, and N. Virginia to N. California is already at around 70 milliseconds. N. California to London is twice that at 140 milliseconds, and Singapore to N. Virginia clocks in at 260 milliseconds.
Given that the default configuration calls for an election if we didn't hear from the leader in 300 milliseconds, it's clear that you can't just throw a cluster with one node each in N. Virginia, Singapore and London. The network latency alone would mean we'd be unable to proceed in most cases. However, that's just the default configuration and is easily changed. The reason I'm dedicating so much time to talking about latency here is that it has a huge effect on your systems that you should consider.
If you have the need to run in multiple data centers — or even in geo-distributed data centers — you need to think about the latency between them and what it means for your application. There are two options you should consider. The first is having a data-center-spanning cluster. The second is to have a cluster per data center. Let's review both of these options.
Single cluster, multiple data centers
When you have a single cluster spanning multiple data centers, take note of the expected latency and behavior. The actual configuration of the cluster
timeout is easy to set (the configuration option is Cluster.ElectionTimeoutInMs, defaulting to 300 milliseconds), but that's the least interesting thing about this
scenario.
When running in a geo-distributed cluster, you need to consider the various operations you use. The cluster timeout is merely the maximum amount of time the nodes will wait for a notification from the leader before deciding that there isn't one and an election needs to be held. If there's work the cluster needs to do, it won't wait for the timeout to happen. Instead, it will always execute it as fast as it can.
On the other hand, an excessively high timeout value means the cluster will take longer to detect that there's a failed leader and recover from that. In general, the cluster will typically recover from a failed node in up to three times the timeout value, so that needs to be taken into account. On the WAN, I'd suggest you raise the timeout to three or five seconds and see how stable that is for your environment. A lot of it will depend on the quality of the communication between the various nodes in your cluster.
We've talked a lot so far about the cluster and the effect of latency on the cluster, but most of the time we're going to operate directly with the database, not the cluster. So how does running in a geo-distributed environment affect the database replication?
The answer is that it generally doesn't. The database-level replication was designed for WAN, and there aren't any hard timeouts like there are at the cluster level. The cluster needs to know there's an active leader because, if there isn't, the node needs to step up and suggest itself as the next leader. But at the database level, all nodes are equal. Any disruption in communication between the nodes is handled by merging the data from all the nodes at a later point in time, resolving any conflicts that may have occurred. This means that a database group is much easier to deploy in a geo-distributed environment with high latency; the nodes are fine with delays.
Database instance distribution in the multi-data-center cluster
RavenDB assumes that all nodes in a cluster are roughly equal to one another, and when you create a new database, it will assign instances of this database to nodes in the cluster, regardless of where they're located. If you're running in a multi-data-center cluster, you probably want to explicitly state which nodes this database will reside on so you can ensure they're properly divided between the different data centers.
Another consideration to take into account is that there's also the clients. A client running on the London data center that connects to the Singapore node for all queries is going to suffer. By default, RavenDB assumes that all nodes are equal, and the cluster will arbitrarily choose a node from the database topology for the client to typically work with.
In the previous chapter, we talked about load balancing and how we can ask RavenDB to handle that for us automatically. One of the available load-balancing options is
FastestNode. This option will make each client determine which node (or nodes) are the fastest, as far as it's concerned, and access them according to speed. This
mode, in a geo-distributed configuration, will result in each client talking to the node closest to it.
That's usually the best deployment option for such an environment because you're both geo-distributed and able to access a local instance at LAN speeds.
There is a potential issue of consistency to think about when your system is composed of parts far enough apart that it can take hundreds of milliseconds to merely send a packet back and forth. If you're writing a document in one area, it's not guaranteed that you'll see the write in another area. In fact, you'll always have to wait until that write has been replicated.
We talked about write assurances and WaitForReplicationAfterSaveChanges in the previous chapter, but it's very relevant here as well. After you make a write with the
FastestNode option, the next session you open might access a different node. In order to ensure that the next request from the user will be able to read what the user just wrote, you need to call WaitForReplicationAfterSaveChanges. Alternatively, if this is a write for which a short delay in replicating to all other
nodes is acceptable, you can skip it and avoid the need for confirmation across the entire geo-distributed cluster.
Multiple clusters, multiple data centers
A single cluster spread over multiple data centers can be convenient for the operations team since there's just one cluster to manage everything. But it can also create headaches. Using the data from Table 7.2 as an example, if we have two nodes in London and one node in N. Virginia, our leader will tend to always be based in London. Any outage between the two data centers will leave the cluster fully functioning in London and unable to complete anything in N. Virginia (since it can't reach the other side).
Another problem is that failover between data centers is not something you'll want to do. You might want to fail to another data center, but having a web app from the N. Virginia data center go all the way to the database instance in London imposes a very high latency. If a page is making just eight database requests, it's going to take over a second to answer and render a single page. And that's just calculating the network round-trip costs. In such cases, it's often preferable to send the web traffic directly to the London data center until N. Virginia's is fully up again.
In such a scenario, having a single cluster will actually work against us. The problem is that the client API will automatically failover to any available node, but in this case, we don't want that. We can't tell the client not to failover to nodes in our cluster. That doesn't make sense. The appropriate way to handle this is to create separate clusters, one in each data center. In this manner, each data center's cluster is independent and manages only its own nodes. The client API in each data center is configured to point to the nodes in that data center only.
In this case, because failover stops at the cluster boundary, there will be no failover between data centers. But we still need to deal with a tough problem. How are we going to handle sharing the data between the separate clusters?
Sharing data between clusters
A RavenDB cluster is a standalone unit. It manages itself and doesn't concern itself much with the outside world. There are situations, however, where you want to have data shared among multiple clusters. This can happen if you want an offsite replica of all your data or if you've decided to have different clusters in each data center rather than a single cross-data-center cluster.
Setting up replication between clusters can be done easily because RavenDB makes a strong distinction between a cluster and database group interactions.
In this case, this allows us to define a replication target that's not part of the cluster itself. We can do that in the database by going to Settings, Manage Ongoing Tasks and then adding an External Replication task. You'll need to provide the URL and database name for the destination. Then, save the
new replication.
If you don't have an additional cluster to test this on, you can specify one of your own nodes and create a separate database to replicate to.
Replicating to the same cluster
On the face of it, it seems strange that we can set up an external replication from the cluster back to itself. Why make it an external replication, then? Well, this can be useful if you want a copy of the data that wouldn't be a failover target for the clients. It may be an offsite copy or just a dedicated database that's set up to do some kind of a job (such as run an ETL processes).
Ongoing tasks in general are quite interesting, and we'll discuss them at length in the next section. For now, we'll focus on what the external replication feature means for us. Once we've finished configuring it, the cluster will assign one of the database group nodes to keep that replica up to date at all times.
It's important to remember that, at the database level, we treat the replica as just another destination. The cluster is not managing it. That means that cluster-level behaviors — such as conflict resolver definition, failing over for the client and index replication — are not replicated. An external replica is just that: external. You can configure both the source cluster and the destination replica in the same manner, of course, but there's nothing that forces you to do so. In fact, the other common reason to set up an external replica is to have a different configuration.
A good example of this is when you want to have expensive indexes and only run them on a particular machine. Maybe you need to run pricey analytics or do certain work on a specific location. Using external replication gives you the ability to control the flow of the data without also dictating how it's going to be processed.
What would it take to have an offsite replica for our cluster? It's quite easy. In the Studio, go to Settings, Manage Ongoing Tasks, and click
Add. Choose External Replication and fill out the URL and database name, and that's pretty much it. The cluster will assign that replication task
to one of the database instances in the database group, and it will immediately start replicating the data to the target.
It's important to understand that, for all intents and purposes, this is just the same replication that happens between database group nodes in the same cluster. The nodes don't know (or care) that this particular replication target isn't in their cluster. That's important to know because it means you can use all the replication features, including waiting for offsite replication to occur or ensure distributed transaction boundaries, across disparate geo-distributed clusters.
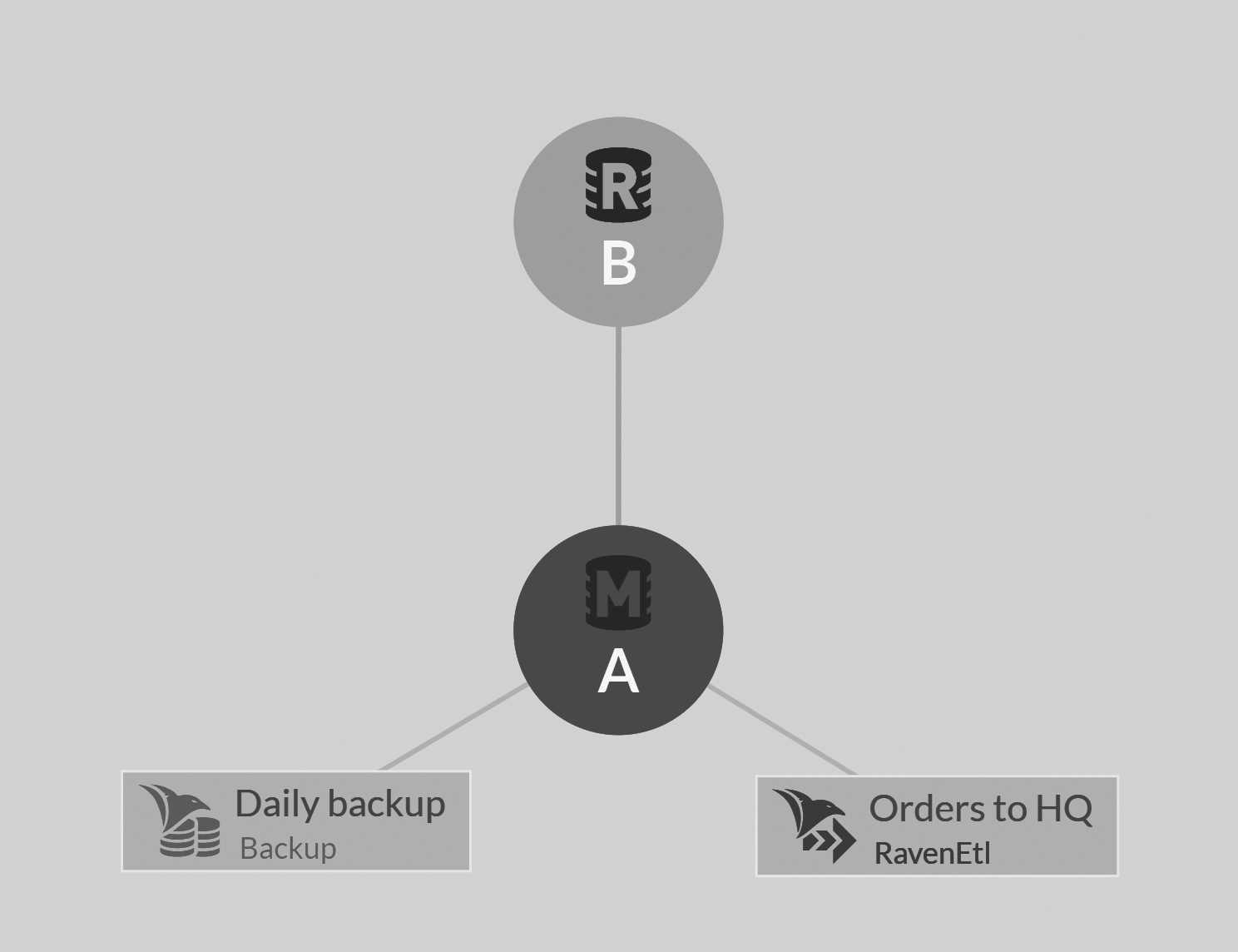
External replication between two clusters will detect conflicts in editing the same documents in separate clusters and will resolve those conflicts according to each cluster conflict resolution policy.5 Figure 7.2 shows the result of a cluster that has defined several external replications from the cluster, for various purposes.

The responsible node portion has been emphasized in Figure 7.2; you can see the node tag that is responsible for keeping each replication target up to date. You can also see that the cluster has assigned each external replication task to a separate node.6.
We haven't discussed it yet, but that's one of the more important roles of the cluster: deciding what work goes where. Read more about that in section 7.3.
External replication - delayed
One of the use cases for External Replication is to have an off site replica of the data. This works quite nicely in most cases, but it does suffer from an issue. If the problem isn't that your main cluster died but rather that someone deleted an important document or updated a whole bunch of documents in a funny way, the off site replica will reflect these changes. In some cases, that is not desirable, since you want to have some gap between the time the data is modified in the main cluster and when the data is modified in the off site replica.
This can be done by adding a delay to the External Replication Task configuration. The replication task will not send the data immediately, rather, it will replicate the data only after some time has passed. For example, you can configure the External Replication task to delay the data replication by six hours, in which case the off site will be six hours behind the main cluster at all times.
If something happened to the data in the main cluster, you can go to the offsite cluster and get the data from before the change. This can be very useful at times, but it doesn't replace having a backup strategy. This is the kind of thing that you setup in addition to proper backup procedures, not instead of.
A replica isn't a backup
It's tempting to think that an offsite replica is also going to serve as a backup and neglect to pay careful attention to the backup/restore portion of your database strategy. That would be a mistake. RavenDB's external replication provides you with an offsite replica, but it doesn't present good solutions to many backup scenarios. It doesn't, for example, protect you from an accidental collection delete or tell you the state of the system at, say, 9:03 AM last Friday.
An offsite replica gives you an offsite live copy of the data, which is quite useful if you need to shift operations to a secondary data center. But it isn't going to allow you to skimp on backups. We cover backups (and restoring databases) in Chapter 17.
Ongoing tasks and work distribution
The cluster as we know it so far doesn't really seem smart. It gives us the ability to distribute configuration, such as which databases go where, what indexes are defined, etc. But it doesn't seem to actually do very much. Well, that's only because we've focused specifically on the flow of data inside a database group rather than on the flow of work.
What does that mean, to have work assigned to a database group? The simplest example is the one we just talked about: external replication. If we have three nodes in this database group, which node will update the external replica? We don't want to have all three nodes do that. There's no real point in doing so, and it can cause unnecessary network traffic. Instead, the cluster will assign this work to one of the database instances, which will be responsible for keeping the external replica up to date.
Another example of what it means to have work assigned to a database group is an hourly incremental backup of your data, as well as a full backup on a weekly basis. You don't want to have this backup run on all three nodes at the same time. Beside the fact that this will increase the load on the system across the board, we don't really have any use for triplicate backups of the same data. This is where the work assignment portion of the cluster comes into play.
Whenever there's a task for a database group to do, the cluster will decide which node will actually be responsible for it. That seems pretty simple, but there's a bit more to the story. Assigning work is easy, but the cluster is also watching the nodes and checking how healthy they are. If a node is down, the cluster will reassign the work to another node for the duration.
Take the case of a backup, for instance. If the responsible node is down during the scheduled time, another node will shoulder the load and make sure you don't have any gaps in your backups. In the case of external replication, another node will transparently take over keeping the external replica up to date with all the changes that happened in the database group.
Another type of work in the cluster — one we've already talked about in this book — is subscriptions. The cluster will divide all the subscriptions between the various nodes in the database group and reassign them upon failure without your code needing to change anything (or typically even being aware of the failure). Other types of work that we can define for the database group include ETL processes, which are covered in the next chapter.
A fun way to experiment with this is to create some work in your cluster (a few external replications or subscriptions would do just fine) and then close one
of the nodes.
You'll see that the cluster recognizes the failed node and moves the work around to the surviving nodes. A test you can run, which will give you a taste of RavenDB's failover
capabilities, is to have a client writing to the database and a subscription open when you close the node. (Make sure to close the node that the subscription
is assigned to.) You shouldn't notice anything happening from the outside. Both subscription and client will silently move to another node, and
everything will just work. You can monitor all of the work in the database group from the Ongoing Tasks page as you run this experiment.
But you aren't the only one watching the state of the cluster. There's another entity in play here. That entity is the supervisor, and it's responsible for making all those separate pieces cooperate seamlessly in the face of error conditions.
The ever-watching supervisor
The cluster is continuously measuring the health of each of its nodes, using a component known as the supervisor.7 The supervisor will detect any errors in the cluster, react to a failed node by reassigning work and, in general, keep everything running.
This is important enough to mention here and not in the operations portion of the book because the supervisor also gives you a wealth of information about the state of the different nodes, as well as the database instances that are running on them. In addition to reassigning work to surviving nodes, it's also responsible for a very important role: the promotion and demotion of database instances.
Given that RavenDB is a distributed database and not a military organization, what does that mean, "promotions and demotions"? Consider the case of a database
group that has two database instances. We want to increase the number of replicas, so we add a new node to the database group. The process is fairly easy. All we
need to do is to click Manage group in the Studio and add the new node.
On large databases, the process of adding a new replica can take a while. During that process, the newly added node isn't really part of the group. It can't take over work in the group (we certainly don't want its backup until it's completely caught up, for example), and we don't want to fail clients over to it (since it doesn't have the full data yet). Because of this, when you add a new node to a database group, it isn't added as a full-fledged member. Instead, it's added as a promotable instance.
But what does "promotable" mean? It means it can't be assigned work for the database group, and that it can't be failed over to. In fact, adding a new node is work for the database group since one of the full members will have to start pushing data into this new node until it's fully up to date. This goes on until the supervisor can confirm that the new node is caught up with the state of the database group and that it's finished indexing all the data we sent to it. At this point, the supervisor will promote the node into a full member within the database group, work will be assigned to it and clients will consider it a failover target.
That works when we're talking about new nodes, but what happens when we have an existing node fail? If a member node fails, we don't want to go back into the usual rotation as soon as it recovers. We want it to pull all the changes that happened in the meantime from the other members in the database group. Because of that, the supervisor can send a node to "rehab."
A node in rehab isn't a full member of the cluster. It behaves exactly like a promotable node, for the most part. Like a promotable node, one of the other members in the database group will connect to it and update the recovered node until it's fully up to date, at which point the supervisor will promote it to full member again.
The only important distinction between a rehab node and a promotable node is what happens when all the members in a database group are down. This is only
relevant in pathological cascading failure scenarios.
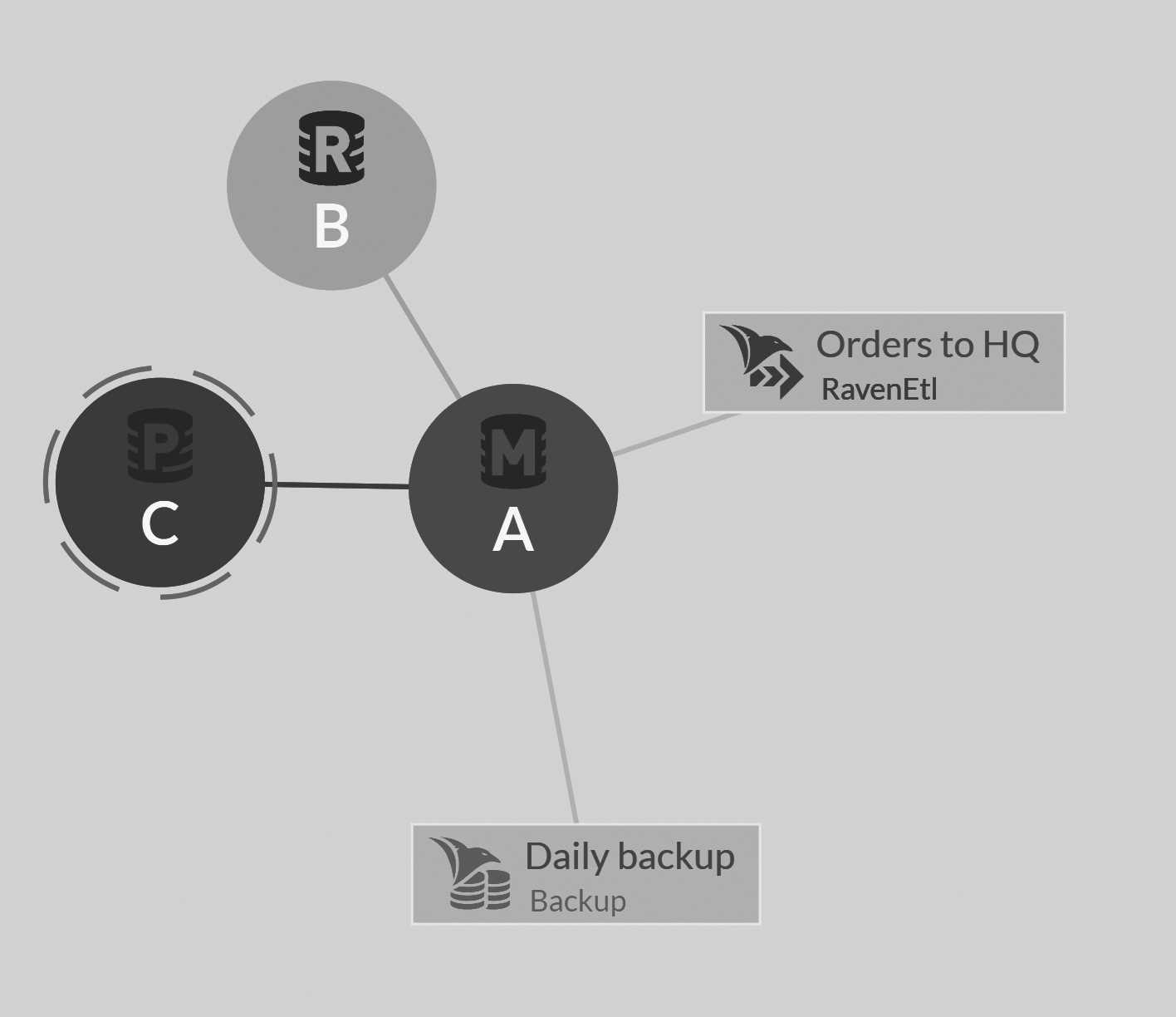
Consider a cluster of three nodes with a database residing on nodes A and B. First, we have node B failing for some reason. (Perhaps the operations team took it
down to apply patches.) The supervisor will detect that and move node B to the rehab group. Node A will assume all duties that were previously assigned to
node B. You can see this in Figure 7.3; the red R icon for node B indicates that it is in rehab mode.
When node B comes back up, node A will send it all the updates it missed. However, we're in somewhat of a pickle if node A is also failing at this point (the operations team is now rebooting that node, without giving it time to get node B fully up to date). On the one hand, we don't have any working members to failover to. On the other hand, node B is functioning, even though it's currently in rehab.
At this point, when there are no more active members in the database group, the supervisor will rehabilitate an active node from the rehab group and mark it as a full member in the database group, restoring functionality to that database. This isn't ideal, of course, because it might be missing writes that happened to node A and haven't been replicated yet, but it's better than losing access to the database completely.
Keep calm and serve requests
You might have noticed that the scenario requiring us to rehabilitate a node in rehab is most easily explained via an operator error. Though rare, such things happen on a fairly regular basis. About a quarter of production failures8 are the result of human error.
One of the primary goals of RavenDB is that the database should always be up and responding. That means we do automatic failover on the client and will always accept writes as long as there's a single node functioning. The idea is that we want to free the operations team from routine tasks that can be handled automatically. For the same reason, RavenDB utilizes the supervisor to automatically and transparently handle failures for you. Having taken that role upon ourselves, we strive to make the job as complete as possible.
Features such as sending nodes to rehab and rehabilitating nodes are part of that. They're there to handle rare edge cases in production and to avoid getting into situations where a temporary failure becomes a permanent one.
That said, the operations team has a critical role in keeping RavenDB running. The supervisor can only do what it was told to do, and there are too many variables in real production systems to account for them all. The design of RavenDB takes that into account and allows you to override the supervisor decisions to fit your needs.
The clients are also aware of the nodes in rehab, and if they're unable to talk to any of the members, they'll try to talk to the nodes in rehab as a last-ditch effort before returning an error to the caller. A major reason we run this logic on both the clients and the supervisor is that this allows us to respond to errors in a distributed fashion in realtime. And this is without having to wait for the supervisor to find the failure and propagate the information about it throughout the cluster and the clients.
Using demotions and promotions as needed, the supervisor is able to communicate to the clients (and the rest of the cluster) what the preferred nodes for a particular database group are. Note that a failure doesn't have to be just a down node. Something as simple as running out of disk space can also cause a database on a node to fail and be sent to rehab until that situation is fixed.
The supervisor is always running on the leader node, and it operates at the cluster level. In other words, it requires consensus to operate. This protects us from a rogue supervisor deciding that all nodes are unresponsive and taking them down. But as long as it has the majority of the clusters' votes, the supervisor is the authority on who's up or down in the cluster. Clients will avoid talking to nodes the supervisor can't talk to, even if they can reach them.
Ensuring a minimum number of replicas
When you create a database, you also specify the number of replicas for that database. This is used by the cluster to decide how many database instances it should create for this database group. One of the roles of the supervisor is to make sure that this value is maintained over time. What do I mean by this?
Well, consider a three-node cluster and a database that was created with a replication factor of two. The cluster assigned this database to nodes A and B. After a while, the supervisor notices that node B is down. It moves the node to the rehab program and hopes that it will recover. However, if it is down for too long (the default value is 15 minutes), the supervisor will decide that it can't assume that node B will come up any time soon and it will need to take action to ensure we have enough replicas for the data in the database.
At this point, the supervisor will create another database instance on another node (C, in this case) and add it to the database group as promotable. At that point, the database group will look like Figure 7.4.
One of the nodes in the database group is a member in full health. This is node A, shown in green in Figure 7.4. We have node B in red in rehab, and we have the new node C, shown as yellow P, that was added as promotable. At this point, we have a race between node B and node C. Node C is getting all the data from the other members in the database group and becoming a full member. Meanwhile, node B is recovering and getting up to date with all the changes it missed.
Either way, one of them will cross the finish line first, and we'll have three full replicas of the data in the database. At that point, the supervisor will delete the extra copy that's now no longer needed. Figure 7.5 shows how the database topology will look if node C has managed to catch up completely while node B wasn't responsive.
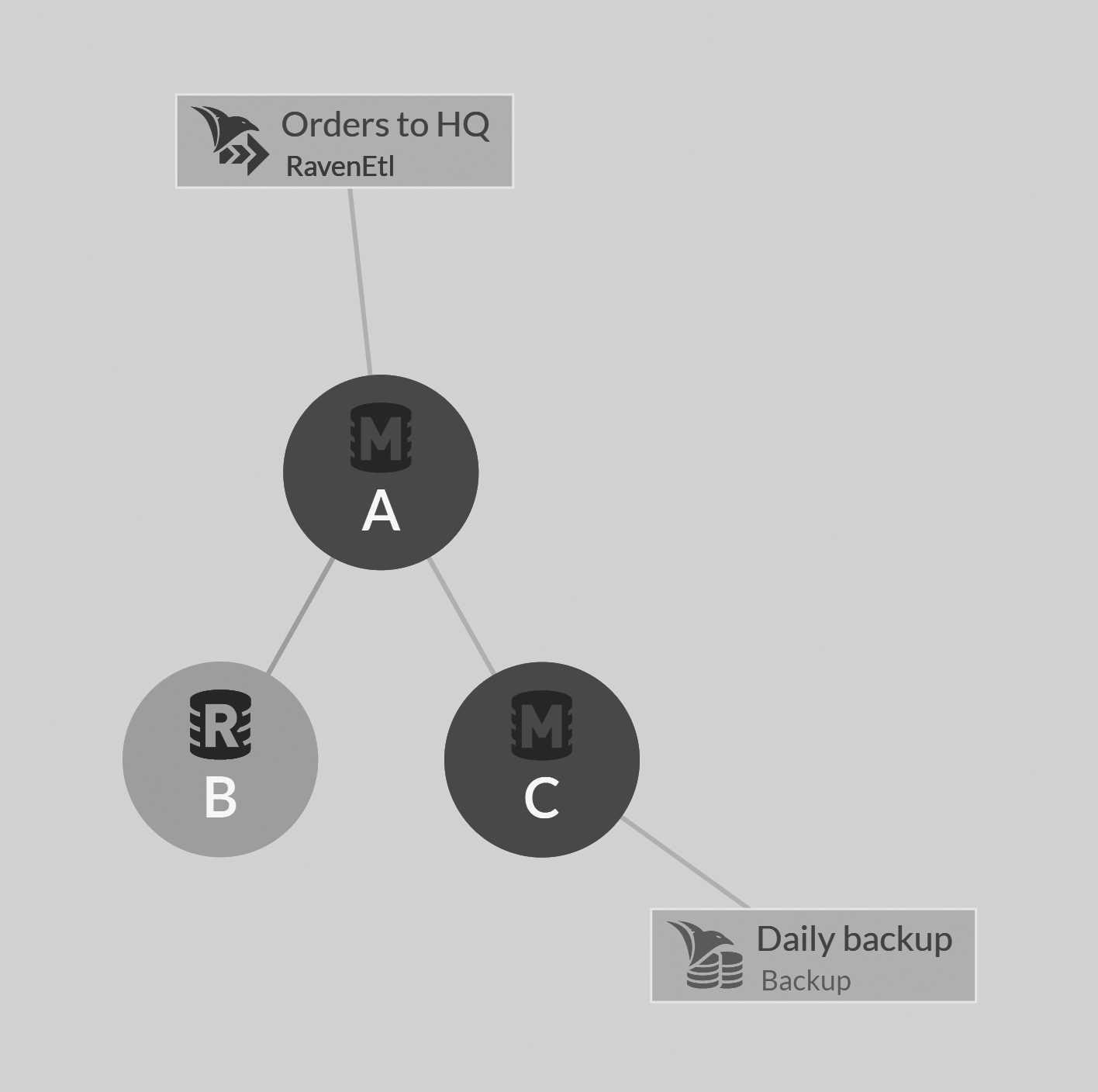
If node B is down for long enough, it will no longer be a part of the database group topology when it's back up, and the cluster will tell it to delete the database copy it currently holds. This is the situation that is shown in Figure 7.5. You can also see in both Figure 7.4 and Figure 7.5 that the cluster has ensured that work assigned to the database (the ETL task and the backup) is distributed to working nodes.
On the other hand, if node B recovers in time and catches up to the rest of the members before node C is ready, the supervisor will promote node B to being a database group member again. The supervisor will then let node C know it needs to delete the now-extraneous copy.
Rebalancing of data after recovery is in the hands of the admin
In the scenario outlined above, if node B was down long enough that we removed the database from it and moved it to node C, what would happen when node B recovers? At that point, all of its databases have been redistributed in the cluster, and it's effectively an empty node. RavenDB will not start moving databases back to node B on its own and will instead require the operations team to instruct it to do so. Why is that?
The supervisor has acted to ensure that the number of replicas for a database is maintained, which is why we allow it to just create a new replica on the fly and move the database instance between nodes. However, we don't know what the state of node B is at this point. It may fail again. Even if it's here to stay, the act of moving a database between nodes can be pretty expensive.
It requires a lot of disk and network I/O, and that isn't something that we want to just do on the fly. We only do that automatically to ensure we keep the minimum number of copies required. Once the incident is over, restoring the state is in the hands of the operations team, which can move the database between the nodes according to their own schedule.
The logic behind the supervisor behavior is that a node is allowed to fail for a short amount of time (network partition, reboot for patching, etc.). But if it's gone for a long time, we need to assume it won't be coming back up, and we need to take action. It's important to take this behavior into account during maintenance, and let the supervisor know that it shouldn't take action and get in the way of the actual operator, who is handling things.
The supervisor's decisions can have a serious impact. For that reason, big decisions, such as moving a database
between nodes, will generate an alert for the operations team to review. Those alerts can be reviewed in the Notifications Center.
Summary
We started this chapter by talking about how we can grow our RavenDB cluster. We learned that, after a certain size, it doesn't make sense to add more members to a cluster. We should add watchers instead. Those are non-voting nodes in the cluster that are still fully managed by it. The advantage is that we have a single cluster and only a single thing to manage, but we don't suffer from large majorities and the latencies they can incur.
We looked at the implications of working with RavenDB in a geo-distributed environment and considered the pros and cons of having a single cluster span multiple geo-distributed data centers versus having a separate cluster per data center. If we have separate clusters, we need to share data between them, and external replication is the answer to that. External replication allows you to tie separate clusters together by replicating all changes to another database, not necessarily on the same cluster.
This is a good option for offsite replicas and to tie separate clusters together, but it also demarcates a clear line between the database instances that are in the same group and an external replication target. Database instances in the same group share work assignments between them, clients can failover from one instance to another in the same group transparently, etc. With external replication, the only thing that happens is that data flowing to the replication target isn't considered to be a part of the database group at all.
We looked into the kind of work you can assign to databases, such as backups and subscriptions, or filling up promotables or nodes in a rehab mode, to allow them to catch up to the rest of the nodes in the cluster. The supervisor is responsible for assigning the work, and it can reassign work if a node failed.
The supervisor has a critical role in ensuring the proper functioning of a RavenDB cluster. In addition to monitoring the health of the cluster, it's also capable of taking action if there are problems. A failed node will be moved to rehab until it's feeling better, and a node that's down for too long will be automatically replaced by the supervisor.
This was anything but a trivial chapter. I tried to focus on the high-level concepts more than the nitty-gritty details. The purpose of this chapter is to get you to understand how RavenDB operates in a distributed environment. It isn't about how to actually run it in such an environment. That's handled in the "Production Deployments" chapter.
Beyond just setting up a cluster, you also need to know how to monitor and manage your systems. That's covered in Chapter 16, which is dedicated to that topic. We'll also talk a bit more about the implementation details that I intentionally skipped here. Your operations team needs to understand what's going on, exactly. This chapter was about the overall concept.
In the next chapter, we'll talk about how we can integrate with other systems in your organization, and we'll introduce the ETL concept9, which allows RavenDB to write data to external sources automatically.
-
The full list can be found in the online documentation.↩
-
Backups will happen on their regular schedule when the cluster is down, but they'll fail to be reported to the cluster and may run again after the cluster has recovered.↩
-
Note: this assumes the connection between those data centers doesn't go over the public internet but rather dedicated lines. If the connection between the data centers is over the public internet, expect higher latency and more variance in the timings.↩
-
The ping times between these data centers were taken from cloudping.co.↩
-
The conflict resolution will then flow to the other cluster as well, so it's highly recommended that you have the same policy configuration on both clusters — that is, unless you have a specific reason not to, such as one-way replication or a meaningful difference in the tasks that the different clusters perform in your system.↩
-
The cluster will make that determination on its own, and it may not always perfectly distribute the work among the nodes in this fashion. Overall, however, the work will be distributed among all the nodes to create a rough equality of work.↩
-
I always imagine it in bright neon green tights and a cape, flying around and spouting cliches as it keeps everything in order.↩
-
https://journal.uptimeinstitute.com/data-center-outages-incidents-industry-transparency/ .↩
-
Extract, transform, load.↩
