 Skip to Navigation
Skip to Navigation
Document Modeling
Modeling your data is crucially important as different modeling decisions will have a different impact on your data and the amount of work that needs to be done by the database. It requires your understanding of how RavenDB, or any other database, is actually storing information and what features it has available for you to utilize.
If you get it wrong, you may be forcing the database to do an exponential amount of additional work. On the other hand, if you play to the database's strengths, you can get a robust and easy-to-build system. So, overall, no pressure whatsoever.
Relational-based modeling is so frequently encountered that, in most cases, you don't even see people talk about the relational part. They refer to relational data modeling as just "data modeling." But when you try to apply a relational modeling solution to a non-relational system, the end result is usually...suboptimal.
Documents aren't flat
Documents, unlike a row in a relational database, aren't flat. You aren't limited to just storing keys and values. Instead, you can store complex object graphs as a single document. That includes arrays, dictionaries and trees. Unlike a relational database, where a row can only contain simple values and more complex data structures need to be stored as relations, you don’t need to work hard to map your data into a document database.
That gives you a major advantage. It simplifies a lot of common tasks, as you'll see in this chapter.
The problem is that this is extremely well-entrenched behavior, to the point where most people don't even realize they're making decisions based on what would work best for a relational database. So the first section of this chapter is going to deal with how to get away from the relational mindset, and the second part will focus on how to model data for RavenDB.
Beyond relational data modeling
You've likely used a relational database in the past. That means you've learned about normalization and how important it is. Words like "data integrity" are thrown around quite often. But the original purpose of normalization had everything to do with reducing duplication to the maximum extent.
A common example of normalization is addresses. Instead of storing a customer's address on every order that he has, we can simply store the address ID in the order, and we've saved ourselves the need to update the address in multiple locations. You can see a sample of such a schema in Figure 3.1.

You've seen (and probably written) such schemas before. And at a glance, you'll probably agree that this is a reasonable way to structure a database for order management. Now, let's explore what happens when the customer wishes to change his address. The way the database is set up, we can just update a single row in the addresses table. Great, we're done.
Well, it would be great...except we've just introduced a subtle but deadly data corruption to our database. If that customer had existing orders, both those orders and the customer information now point at the same address. Updating the address for the customer therefore will also update the address for all of its orders. When we look at one of those orders, we won't see the address it was shipped to but rather the current customer address.
When a data modeling error means calling the police
In the real world, I've seen such things happen with payroll systems and paystubs (or "payslips," across the pond). An employee had married and changed her bank account information to a new shared bank account with her husband. The couple also wanted to purchase a home, so they applied for a mortgage. As part of that, they had to submit paystubs from the past several months. The employee asked her HR department to send over her most recent stubs. When the bank saw paystubs made to an account that didn't exist, they suspected fraud. The mortgage was denied and the police were called. An unpleasant situation all around.1
It's common for this issue to be blamed on bad modeling decisions (and I agree). The problem is that a more appropriate model is complex to build and work with, expensive to query and hard to reason about in general.
A lot of the wisdom about data modeling is limited by only seeing the world through relational eyes. The relation model offers us tables, rows and columns to store our data, and it's up to us to hammer the data into the right shape so the relational database can accept it. Along the way, we have to deal with an impedance mismatch between how software (and our minds) model the data and how we're forced to store it to the relational database.
A document database like RavenDB doesn't solve this problem completely. It's entirely possible to construct models that would be a poor fit for the way RavenDB stores data. However, the way most business applications (and in general OLTP systems) think about their data is an excellent fit for RavenDB.
You can read more about this by looking at Domain Driven Design2 and, in particular, about the concept of an Aggregate Root.
What are aggregates?
One of the best definitions I've read is Martin Fowler's:
A DDD aggregate is a cluster of domain objects that can be treated as a single unit. An example may be an order and its line items. These will be separate objects, but it's useful to treat the order (together with its line items) as a single aggregate.
An aggregate will have one of its component objects be the aggregate root. Any references from outside the aggregate should only go to the aggregate root. The root can thus ensure the integrity of the aggregate as a whole.
In the context of RavenDB, this is highly relevant since every RavenDB document is an aggregate and every aggregate is a document. Modeling techniques for aggregates work well for document-oriented design, and that gives you a great resource for modeling in the real world.
But before we can start running, we need to learn to walk. So let's start by learning how to use RavenDB with the most basic of modeling techniques: none.
Using RavenDB as a key/value store
RavenDB is a document database, but it's also quite good at being just a key/value store. That's mostly accidental, but as part of making sure we have a fast database, we also significantly reduced the cost of storing and loading documents without any of the other benefits of RavenDB.
With the restriction that the data must be JSON, using RavenDB as a key/value store makes a lot of sense. It also makes sense to use RavenDB to cache information, to store the shopping cart during the purchase process or just to hold on to the user session data — all classic models for key/value stores.
RavenDB doesn't impose any additional costs on storing/loading documents by default, so you get to use a fast database with the simplest of all access models. Typically, complexity in key/value modeling resides in generating the appropriate key and in what sort of operations you can do on it.
For the purpose of using RavenDB as a key/value store, it's likely the following features will be most relevant:
- You can generate the document identifier independently of the collection used.
- Loading saved document(s) can be done in a single call by providing the ID(s) to load.
- RavenDB provides automatic expiration for documents, which you can use with caching/session data.
- You can perform searches using document identifiers as a prefix (and even using glob-like searches).
- Includes can be used to fetch related data without having to make multiple remote calls.
The nice thing about using RavenDB as a key/value store for such information is that you aren't limited to just those key/value operations. If you're storing shopping cart data inside RavenDB, you can also start pulling data from there. You can see the most popular item being purchased or do projections on inventory or any of a whole host of things that will provide you with useful knowledge.
In a typical key/value store (Redis, for example), you'll have to manually track such things. However, RavenDB allows you to
query and aggregate the data very easily.
But using RavenDB just for key/value data is somewhat of a waste, given what it's capable of doing with your data. So, without further ado, let's dive into document modeling in RavenDB.
Modeling considerations in RavenDB
The reason we cover modeling in this chapter is that I want you to get a feel for some of RavenDB's capabilities before we start discussing modeling techniques. The kind of features that RavenDB has to offer are directly relevant to the models you'll write.
RavenDB as the application database
A common bad practice is to integrate between different applications using a shared database. This has been looked down upon for quite a while. RavenDB makes no attempt to cater to those who use it as shared database. Instead, it shines in its role as an application database.
Typically, shared database solutions suffer because they attempt to force disparate applications to treat the data in the same manner. This is a pretty bad idea, since different applications tend to treat even very similar concepts in a variety of ways. The most common example is a billing application and a fulfillment application. Both have the concept of a customer, and both actually refer to the same thing when they talk about a customer. But the fulfillment application needs to keep track of very different data from the billing application. What will the fulfillment app do with the
CreditScorefield, and what can the billing app gain from looking at theShippingManifestdetails?Each application should model its data independently and evolve it as it needs to. Keeping everything in a shared database leads to required coordination between the various application teams. That results in increased complexity in evolving the data model as the various applications are being worked on.
However, even though the different applications are separate, they still need to share data between them. How do you do that with RavenDB? We'll talk about that a lot more in Chapter 8, but the answer is that each application has its own database, and we can set up information flow between the servers by using RavenDB's built-in ETL capabilities.
In this way, each application is independent and can evolve and grow on its own, with well-defined boundaries and integration points to its siblings.
We typically encourage you to use DDD techniques for modeling in RavenDB since they fit so well. A core design principle for modeling documents is that they should be independent, isolated and coherent, or more specifically,
- Independent, meaning a document should have its own separate existence from any other documents.
- Isolated, meaning a document can change independently from other documents.
- Coherent, meaning a document should be legible on its own, without referencing other documents.
These properties are easier to explain using negation. First, a document isn't independent if it can't stand up on its own. A good
example of a dependent document is the OrderLine. An OrderLine doesn't really have a meaning outside the scope of
an Order, so it should be a Value Object inside the Order document. An Entity is defined as something with a distinct and
independent existence. And that's how you treat documents: as entities. If a document exists only as part of a larger whole, then the whole thing should be re-factored/re-modeled to a single document.
Second, a document isn't isolated if changing one document requires you to also update additional documents. For example, if updating the
CustomerBilling document necessitates updating the Customer document, they aren't isolated. A document should be able to
change independently from other documents. Otherwise, there's an unclear transaction boundary involved. With each document isolated,
the transaction boundary (meaning what can change together) is much clearer. It's drawn at the document level.
Lastly, a document isn't coherent if it's not possible to make sense of it with just the information it contains. If you need
to go and look up additional state or information from other documents, the document isn't coherent. A good example is the
Order document and the ShippingMethod. If, to ship an order, we need to go and look at the Customer document, then the
Order document is not coherent.
Looking at physical documents
A great trick for document modeling is to consider the data as, well...documents. What I mean by that is physical documents — the kind you can actually hold in your hand and get a paper cut from. A lot of the same considerations that apply in the real world apply to document modeling.
If I hand you a document and tell you that you need to fill out this form and then go and update that form, you'll rightly consider the process a normal government behavior/bureaucratic/Kafkaesque.3 If I gave you a form and told you that, in order to understand it, you had to consult another document...you get my point.
When modeling, I find that it helps to picture the document in its printed form. If it makes sense as a printed page, it's probably valid in terms of document modeling.
Denormalization and other scary beasts
Anyone taking a relational modeling course knows that "store a fact only once" is a mantra that's just short of being sacred (or maybe not even short). The basic idea is that if you store a fact only a single time, you are preventing update anomalies, such as when you updated a person's date of birth in the employee record but forgot to update it on the "send a card" listing.
I wholeheartedly agree with this statement in principle. But the problem is that sometimes this isn't the same fact at all, even if
it looks the same. Let's consider the notion of a Customer, an Order and what the Address property means in this case. The
Customer entity has an Address property that holds the address of the customer, and the Order has a ShipTo property.
Why are we duplicating this information? Well, this isn't actually the same information, even if the content is the same. On the
one hand, we have the Customer.Address, which represents the customer's current address. On the other hand, we have the
Order.ShipTo which represents a point-in-time copy of the customer address, captured at the time we created the order. Those are
important distinctions.
One of the more common objections to the kind of modeling advice found in this chapter is that the data is denormalized. And that's true. But for the most part, even if the same data appears in multiple locations, it doesn't have the same semantic meaning. And the notion of point-in-time data is important in many fields.
RavenDB has quite a few features that help in working with normalized data (LoadDocument and projections are the two main ones, and they're
covered in Part III), but you need to consider whether it make sense to traverse document references in your model or
whether you're breaking document coherency.
The most useful question you can ask yourself in this situation is whether you're looking at the current value (in which case you need normalization) or the point-in-time value (in which case you'd use a copy).
And with all of this information now in our heads, we can turn to concrete modeling scenarios and see how to deal with them.
Common modeling scenarios
Giving you advice on how to model your application is beyond the scope of this book. While I highly recommend the DDD book in general, it isn't always the best choice. Proper DDD modeling takes a lot of discipline and hard work, and it's most appropriate only in specific parts of your system (typically the most highly valued ones). RavenDB doesn't have any requirement regarding how you should model your data in your application. You can use DDD, you can use business objects or data transfer objects — it doesn't matter to RavenDB.
What matters is how you structure the data inside RavenDB, and that's what we'll be talking about for the rest of this chapter. We'll focus on concrete scenarios rather than generic modeling advice. Instead of trying to advise you on how to model your entire system, I'm going to focus on giving you the tools to build the model as you need it to be, so it will play best with RavenDB.
To make things interesting, we're going to use a kindergarten as our data model. As you can expect, we have the concepts of children, parents, registrations, etc. On the face of it, this is a pretty simple model. We can model it using the code in Listing 3.1.
Listing 3.1 Simple kindergarten model
public class Parent
{
public string Name { get; set; }
}
public class Registration
{
public DateTime EnrolledAt { get; set; }
public EnrollmentType Type { get; set; }
}
public class Child
{
public string Name { get; set; }
public DateTime Birthday { get; set; }
public Parent Father { get; set; }
public Parent Mother { get; set; }
public Registration Registration { get; set; }
}
The code in Listing 3.1 is obviously a simplified model, but it's a good place to start our discussion. A core tenet of modeling in RavenDB is that we need to identify what pieces of information belong together and what pieces are independent of one another. Recall our discussion on the basics of document modeling design. A good document model has documents that are independent, isolated and coherent.
With the basic model in Listing 3.1 and our understanding of a kindergarten, we can now proceed to explore aspects of document modeling. We'll start with the most obvious one. In this model, we don't have documents, we have a document: just a single one per child. That's because we're embedding all information about the child in the document itself. Why would we do that?
Embedded documents
A document model is very different from a relational model. It would be typical in a relational model to have a separate table for each class shown in Listing 3.1. A concrete example might work better, and Listing 3.2 shows how this model works for registering Alice to our kindergarten.
Listing 3.2 Kindergarten record of Alice in Wonderland
// children/alice-liddell
{
"Name": "Alice Liddell",
"Birthday": "2012-05-04T00:00:00.0000000Z",
"Mother": {
"Name": "Lorina Hanna Liddell",
},
"Father": {
"Name": "Henry Liddell"
},
"Registration": {
"EnrolledAt": "2014-11-24T00:00:00.0000000Z",
"Type": "FullDay"
}
}
All of the information is in one place. For the document ID you can see that we used a semantic ID, children/alice-liddell, which includes the child name. This
works well for data that's well known and predictable. The data itself is centrally located and easy to access. Looking at the data,
it's easy to see all relevant information about our Alice.4
For the most part, embedding information is our default approach because it leads us to more coherent documents, which contain all the information relevant to processing them. We aren't limited by format of schema; we can represent arbitrarily complex data without any issue, and we want to take full advantage of that.
So if the default approach is to embed data, when wouldn't we want to do that? There are a few cases. One is when the data doesn't belong to the same document because it's owned by another entity. A good document model gives each document a single reason to change, and that's the primary force for splitting the document apart.
In the case of the kindergarten record, the obvious example here are the parents. Henry and Lorina are independent entities and are not fully owned by the Alice record. We need to split them into independent documents. On the other side of things, Henry and Lorina have more children than just Alice: there's also Harry and Edith.5 So we need to consider how to model such information.
Many-to-one relationship
How do we model a kindergarten where Alice, Harry and Edith are all the children of Henry and Lorina? The technical term for this
relationship is many to one. Unlike the previous example, where we embedded the parents inside the child document, now we want to model
the data so there's a distinct difference between the different entities. You can see the document model as JSON in Listing 3.3.
Listing 3.3 Many to one modeling with children and parents
// children/alice-liddell
{
"Name": "Alice Liddell",
"MotherId": "parents/1923-A",
"FatherId": parents/1921-A",
}
// children/henry-liddell
{
"Name": "Henry Liddell",
"MotherId": "parents/1923-A",
"FatherId": parents/1921-A",
}
Listing 3.3 shows6 both Alice and Henry (you can figure out what Edith's document looks like on your own) with references to their parents. I've intentionally not included semantic IDs for the parents to avoid confusion about what information is stored on the side holding the reference. Alice and Henry (and Edith) only hold the identifier for their parents' documents, nothing else.
How is this model reflected in our code? Let's look at Listing 3.4 to see that (again, with some information redacted to make it easier to focus on the relevant parts).
Listing 3.4 Child class representing the model
public class Child
{
public string Name { get; set; }
public string FatherId { get; set; }
public string MotherId { get; set; }
}
Instead of storing the parent as an embedded document, we just hold the ID to that parent. And when we need to traverse from the child
document to the parent document, we do that by following the ID. To make things faster, we'll commonly use the Include feature to make
sure that we load all those documents in one remote call, but that doesn't impact the data model we use.
What about the other side, when we need to find all of Lorina's children? We use a query, as shown in Listing 3.5.
Listing 3.5 Loading Lorina and her children
using (var session = store.OpenSession())
{
var lorina = session.Load<Parent>("parents/1923-A");
var lorinaChildren = (
from c in session.Query<Child>()
where c.MotherId == lorina.Id
select c
).ToList();
}
You can also run this query directly in the Studio by going to Indexes and then Query and using the following query: from Children where MotherId = 'parents/1923-A'.
As you can see in Listing 3.4 and 3.5, we're being very explicit when we move between documents. RavenDB doesn't allow you to transparently move between different documents. Each document is a standalone entity. This helps ensure you don't create silent dependencies in your model since each document is clearly delineated.
Using lazy operations
In Listing 3.5, you can see we have to make two separate calls to the server to get all the information we want. When going from a child to a parent, we can use the
Includefeature to reduce the number of calls. Going the other way,Includewouldn't work, but we don't have to give up. We have the option of making a few lazy operations and only going to the server once. We'll see exactly how this is possible in the next chapter.
The many-to-one relation is probably the simplest one, and it's incredibly common. However, when using it, you need to carefully consider whether the association should cross a document boundary or remain inside the document. In the case of parents and children, it's obvious that each is a separate entity, but orders and order lines are the reverse. In the case of orders and order lines, it's just as obvious that order lines do not belong in a separate document but should be part and parcel of the order document.
There are many cases where that distinction isn't quite so obvious, and you need to give it some thought. The decision can be situational and, frequently, it's highly dependent on the way you use the data. An equally valid decision in the kindergarten case would be to embed the parents' information in the child document and duplicate that information if we have two or more siblings in kindergarten at the same time.
It depends what kind of work is done with the parents. If all or nearly all the work is done with the children, there's no point in creating a parent document. (It isn't meaningful inside the domain of the kindergarten outside the scope of the children.) However, if we wanted to keep track of parents as well (for example, maybe we want to note that Mrs. Liddell takes two sugars in her tea), then we'll likely use a separate document.
Children and parents are all well and good, but what about when we ramp the example up a bit and explore the world of grandchildren and grandparents? Now we need to talk about many-to-many relationships.
Many-to-many relationship
A many-to-many relationship is a lot more complex than a many-to-one relationship because it's usually used differently. In our kindergarten example, let's consider how we can model the grandparents. Each grandchild has multiple grandparents, and each grandparent can have multiple grandchildren.
When we were working with parents and children, it was obvious that we needed to place the association on the children. But how should we model grandparents? One way to do it would be to simply model the hierarchy. A grandparent is the parent of a parent. That seems like an elegant reflection of the relationship, but it will lead to a poor model. Grandparents and grandchildren have an association between them that's completely separate from the one going through the parent, and that deserves to be modeled on its own, not as a side effect.
The next question is where to put the relationship. We can add a Grandparents array to the child document, which will hold all the
document IDs of the grandparents. We can add a Grandchildren array to the grandparent document and store the children IDs there. Or
we can do both. What should we choose?
In the context of many-to-many associations, we always place the record of the association on the smaller side. In other words, since a child is likely to have fewer grandparents than a grandparent has children, the association should be kept on the child document.
The users and groups model
A more technical example that frequently comes up within the context of many-to-many associations is the users and groups model. A user can belong to many groups, and a group can have many users. How do we model this?
A user typically belongs to a few groups, but a group can have a lot of users. So we record the relationship on the smaller side by having a
Groupsproperty on the user document.
Traversing a many-to-many association from the grandchild (smaller) side can be done by simply including and loading the grandparents, as shown in Listing 3.6.
Listing 3.6 Alice and her grandparents
using (var session = store.OpenSession())
{
Child alice = session
.Include<Child>(c => c.Grandparents)
.Load("children/alice-liddell");
Dictionary<string, Parent> gradparents =
session.Load<Parent>(alice.Grandparents);
}
Following the association from the other side requires us to query, as shown in Listing 3.7.
Listing 3.7 Alice and her grandparents
using (var session = store.OpenSession())
{
Parent grandparent = session.Load<Parent>("parent/1923-A");
List<Child> grandchildren = (
from c in session.Query<Child>()
where c.Grandparents.Contain(grandparent.Id)
select c
).ToList();
}
You can also run this query directly in the Studio by going to Indexes and then Query and using the following query: from Children where Grandparents[] in ('parents/1923-A').
The code in Listing 3.7 will load Alice's mother and all of her grandchildren. In this case, we see a slightly more complex query, but the essence of it remains the same as the one in Listing 3.5. We have separate documents and clear separation between them. In other words, we can query for related data, but we don't just traverse the object graph from one document to another.
One-to-one relationship
A one-to-one relationship is a pretty strange sight. If there's a one-to-one relationship, shouldn't it be an embedded document instead of having a separate document? Indeed, in nearly all cases, that would be a better idea.
There are a few reasons why I'd want to store a part of a document in a separate document. Usually this would be the case if we have a document that's conceptually the same but has very different access patterns. In the order example, we might have the order header, which is frequently accessed and looked at. And then there's the full order, which might be very big (lots of line items) and which we don't need to access often.
In this case, it might make sense to create a document just for the order header (call it orders/2834/header). But using a projection
will be almost as good, and we'll discuss those in Chapter 4. This saves us the need to split our data.
The typical way you'll
build one-to-one relationships in RavenDB is to utilize document ID postfixes to create a set of related documents (orders/2834 and
orders/2834/header, for example).
This tends to result in clearer intent since it's obvious what each part is doing and what it's meant to be. But even so, it's often not advisable. Just putting it all in a single document is easier in most cases.
Another scenario that might require you to split a document is if you have a real need to have concurrent activities on a document. This is generally pretty rare. Since a document is the unit of concurrency in RavenDB, you'll model your documents so they'll have a single reason to change. But sometimes there are reasons to allow concurrent updates on a document — for example, if you have properties on the document that are useful for the application, not the business model.
Case in point, imagine in an order system that we want to add a feature for tracking an order. A customer representative may mark an order for tracking so they can see what kind of steps a particular order goes through and take action at various points in the workflow. Such an action needs to be recorded, but it doesn't actually impact the behavior of the system in any way. It is fine to add or remove tracking on an order at any point in time, including during concurrent updates to the order.
One way to do that would be to always use patching (also discussed in the next chapter) to update the document, but a better way to handle
this kind of requirement is to create a dedicated document orders/2834/tracking that would hold all the details about the users tracking
this order. This makes it an explicit action in your domain instead of just tacking it onto the existing objects.
Advanced modeling scenarios
The RavenDB modeling techniques that we've explored so far are good for modeling standard business data. You know how to build your entities, how to deal with relationships between them and how to identify whether they should be separate documents or nested in the same document. But there's also a good deal of sophistication we can apply to non-standard scenarios, which is the topic of this section.
Reference data
Reference data is common, and it can be anything from a list of states to tax rates to localized text. The common thread for reference data is that it's typically small and not really interesting in isolation. Such data only gets interesting when you start working with a lot of it.
It's typical to ignore the modeling concerns for such items — to just throw them in a pile somewhere and not give it any thought. With
the list of states example, the most natural way to do it is to define a document whose ID is states/ny and has a single Name
property with the value New York. That would work, but it's hardly the best way to go about it.
Going back to basic principles, such a document will hardly be coherent or independent. Indeed, such a document makes little sense on its own. Instead of storing each state and each configuration value as its own document, we'll raise the bar a bit and introduce configuration documents. You can see the example in Listing 3.8.
Listing 3.8 Storing the states list as a configuration document
// config/states
{
"AL": "Alabama",
"AK": "Alaska",
"AS": "American Samoa",
...
...
"WV": "West Virginia",
"WI": "Wisconsin",
"WY": "Wyoming"
}
Modeling reference data in the manner shown in Listing 3.8 has several advantages. It's much easier to work with the data. Instead of issuing a query, we can just load the document in one shot, and it's ready for our consumption. It means the database has less work to do, and it plays nicely into the way RavenDB caches data. It also means we can reduce deserialization costs and make it easier to edit and work with the reference data.
In fact, because this is a single document, we can also get RavenDB to do some tasks for us, such as the build-in revisions capability. We'll discuss this in more detail in Chapter 4. This can be very useful when you're talking about reference or configuration data since it's easy to see what the changes were (or revert them).
Hierarchical information
Working with hierarchical data is complex because there are cases where you need to traverse the hierarchy, and that traditionally has been expensive. In many cases, hierarchies are recursive and have no limits to their number of levels (although, in practice, the number is usually known to be small).
We need to make a distinction between several types of hierarchies. The first hierarchy is quite simple and can comfortably fit into a single document. An example of such a hierarchy is comments in a discussion thread. The entire thread is a single document, and all the comments in the thread always reside in that document. In such a case, storing and working with the hierarchical nature of the data is quite trivial since you'll often just traverse the data directly after loading the document from the server.
A commonly-seen example of a hierarchy that doesn't fit the "everything in a single document" model is the company hierarchy. Each employee
is an independent entity, and we can't store them all as a single document. Instead, we'll strive to model the hierarchy explicitly as an
independent concept from the employees. In this case, we'll have the notion of a department, which will record just the chains of who
reports to whom. The idea is that we separate the hierarchy out since the position of an employee in the hierarchy is orthogonal to most
aspects of the employee.
The notion of a separated hierarchy document gives us a lot of simplicity. Hierarchical operations and queries (all direct and indirect
reports, for example) are easy and natural, and the separated hierarchy document works well with caching and the use of Include.
The final example for modeling hierarchies in RavenDB is when we need to model the hierarchy directly in the model. Departments in an organization might be a good example; their location in the hierarchy is important to what they are. In this case, we'll typically model such a relationship as many to one or many to many, at each individual level. That's the simplest method for handling such a requirement.
This works as long as we only need to handle a single level, but it doesn't handle hierarchical queries. Finding all the departments under
R&D, regardless of whether they're directly or indirectly attached, requires a bit more work since we'll need to define indexes that are
able to walk through the hierarchy. We haven't talked about complex operations in indexes, so I'll just mention that RavenDB's indexes can
use Recurse to work with hierarchical data and leave that topic to Chapter 10, where
we'll cover it in depth.
Temporal data model
Temporal data is often a challenge because it can really mess with the way you think about information. Despite the fancy name, temporal data is just a way to store data that has a relation to time. The best example I've seen for temporal data is payroll. Consider the notion of a paycheck. An employer and employee have a contract stipulating that, for a given amount of work, a given amount of money will be exchanged.
The problem is that this contract can change over time. An employee can get a raise, earn additional vacation days, negotiate better overtime terms or all of the above. For extra fun, you may get some of those changes retroactively. This sort of thing makes it hard to figure out what exactly you're supposed to do. (What if these terms change mid-month? How would you handle overtime calculation on a shift between 8 PM and 4 AM that falls in that switch?)
The way to model temporal data in RavenDB is to embrace its document nature fully, especially because in most temporal domains the notion of documents and views over time is so important. Consider this situation: a paystub was issued on May 1st, and then a retroactive pay raise was given. How is that money counted? It's easy to see that when we model the data as physical documents, we don't try to model a paystub as a mutable entity but rather a point-in-time view. Any changes that were made during the time frame it covered will be reflected in the next paystub.
This approach makes it much easier on you. You don't have to keep track of valid time, effective time and bitemporal time all at once. You just store facts and the time at which they were stored, just as if you were keeping all your printed paystubs in a drawer somewhere.
The same applies to contracts and other things that mutate over time. Consider the documents seen in Figure 3.2. They represent the same contract, with modifications over time as things change.
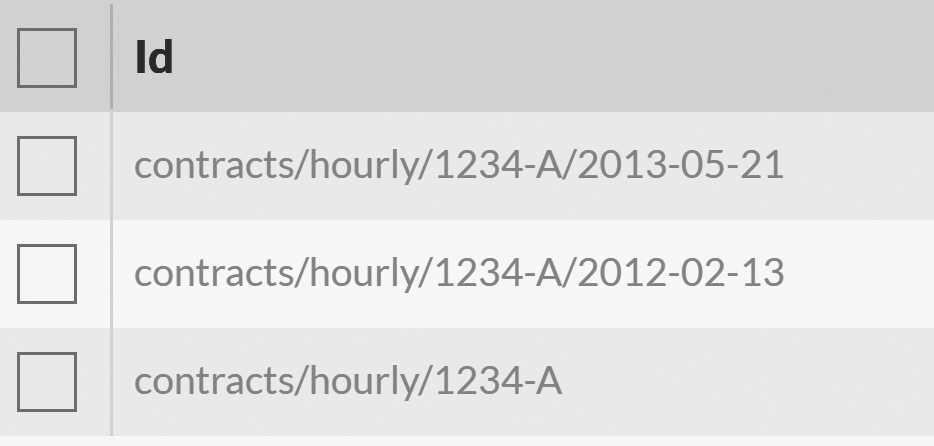
The key is that, when we consider references to this contract, we can select what kind of reference we want. When looking at the
employee's record, we'll have a reference to contracts/hourly/1234-A, which is the current version of the contract. But when issuing
a paystub, we'll always reference a fixed revision of this contract, such as contracts/hourly/1234-A/2013-05-21. This way, we set
ourselves up to choose whether we want the point-in-time information or the current (continuously updated) version.
If this sounds similar to the way we decide if we'll copy data from another document to get a point-in-time snapshot of it or reference it by ID to always get the latest data, that's probably because it is similar. And it makes dealing with temporal data significantly simpler.
Additional considerations for document modeling
A major challenge in modeling data with RavenDB is that different features and behaviors all have a very different impact on the cost of various operations, and that in turn impacts how you'll design and work with your model. In this section, we'll explore a few of the features that we haven't gotten to know yet and their impact on modeling data in RavenDB.
I recommend going over this section briefly now and returning to it when you've finished this book. By then, you'll have the complete picture and will be able to make more informed decisions.
Handling unbounded document growth
What size should a document be? It's an interesting question that frequently comes up with regard to modeling. A good range for a document is somewhere on the order of kilobytes. In other words, if your document is very small (a few dozen bytes), is it really a document? Or is it just a single value that would be better off as a reference data document, as we discussed earlier in this chapter? On the other hand, if you document is multiple megabytes, how easy it is to work with it?
Maximum document size
RavenDB has a hard limit on document sizes, and it's around the 2 GB mark. (Documents are often stored compressed, so a 2 GB JSON document will typically be smaller inside RavenDB.) But the biggest document I recall seeing in the field was about 170 MB. We had a discussion with the customer regarding modeling and about the fact that, while RavenDB is a document database, it's perfectly capable of handling multiple documents.
RavenDB itself, by the way, is just fine with large documents. The problem is everything else. Consider a page that needs to display a 12 MB document. What are the costs involved in doing this?
- Reading 12 MB over the network.
- Parsing 12 MB of JSON into our entities (this often means using a lot more memory than just the 12 MB of serialized JSON).
- Generating a web page with some or all of the information in the 12 MB document.
- Discarding all of this information and letting it be garbage-collected.
In short, there's a lot of work going on, and it can be very expensive. On the other hand, if you have anemic documents, we'll typically need to read many of them to get anything meaningful done, which means a lot of work for the database engine.
Here's the rule of thumb we use: as long as it makes sense to measure the document size in kilobytes, you're good. RavenDB will generate a warning in the Studio when it encounters documents that are too large,7 but it has no impact whatsoever on the behavior or performance of the system.
There are two common reasons why a document can be very large. Either it holds a single (or a few) very large properties, such as a lot of text, binary data, etc., or it contains a collection whose size is not bounded.
In the first case, we need to consider whether the large amount of data is actually a core part of the document or if it should be stored externally. RavenDB supports the notion of attachments, which allows you to, well, attach binary data to a document. If the data can be stored outside the document, regardless of whether it's binary or textual, that's preferable. Attachments in RavenDB don't have a size limit and aren't accessed when loading the document, so that's a net win. We'll learn more about attachments toward the end of this chapter.
The more complex case is if we have a collection or collections inside the document that have no upper bound. Consider the case of an order document. In retail, an order can contain up to a few hundred items, but in business-to-business scenarios, it's not uncommon to have orders that contain tens and hundreds of thousands of items. Putting all of that in a single document is going to lead to problems, as we've already seen.
Who modifies the big documents?
While big documents are typically frowned upon because of the awkwardness of working with large amounts of data (network, parsing and memory costs) there's another, more theoretical aspect to the problems they bring: who owns a very big document?
Remember that good document modeling implies there's only a single reason to change a document. But if an order document contains so many items, that likely means there are multiple sources that add items to the order, such as different departments working with the same supplier. At that point, it isn't a single document we're working with. It's multiple independent orders merged into a single, final shipping/billing order.
Again, falling back to the real-world example, we'd find it strange if a van stopped by our store and started unpacking crates full of pages detailing all the things a customer wanted to purchase. But when we're working on a single document, this is pretty much what we're doing. Instead, we'll typically accept individual requests from each contact person/department and associate them with the appropriate billing/shipping cycle.
In other words, the reason we split the document isn't so much to artificially reduce its size but because that's how the business will typically work, and doing it any other way is really hard. Splitting it so the document structure follows the structure of the business is usually the right thing to do.
So how do we handle large documents? We typically split them into smaller pieces along some sort of business boundary. Let's consider the case of a bank account and the transactions we need to track. Keeping all the transactions inside the account document isn't feasible on a long-term basis. But how are we going to split them? Here, we look at the business and see that the bank itself doesn't look at the account and all its history as a single unit.
Instead, the bank talks about transactions that happened on a particular business day or in a particular month. And we can model our documents accordingly. In the bank example, we'll end up with the following documents:
accounts/1234— account details, status, ownership, conditions, etc.accounts/1234/txs/2017-05— the transactions in this account on May 2017accounts/1234/txs/2017-04— the transactions in this account on April 2017
Within a given time frame, we can be reasonably certain that there's going to be an upper bound to the number of transactions in an account. I quite like this approach because it aligns closely with how the business is thinking about the domain and it results in clear separation of documents. But you can't always split things apart on such a convenient boundary. What happens if there isn't a time element that you can use?
At that point, you still split the document, but you do so arbitrarily. You can decide that you'll generate a new document for the items
in the collection every N items, for example. Often, that N value is some multiple of the typical page size you have in your
system. If we go back to the example of order and items in the order, assuming we don't go the route of splitting the order
itself into separate requests, we'll just split the order every 100 items. So, we'll end up with the following documents:
orders/1234— the order header, shipping details, billing, etc.orders/1234/items/1— the first 100 items for this orderorders/1234/items/2— the second 100 items for this order
The order document will contain the IDs of all the items documents (so we can easily Include them), as well as the ID of the last items
document, so we'll know where to add an item to this order.
This approach is a bit clumsier, in my eyes. But if we don't have another alternative natural boundary, this will work fine.
Cached queries properties
A common modeling technique is to keep track of some cached global state inside our entities. The most trivial example I can think of is
the customer.NumberOfOrders property. I want to call out this behavior specifically because it's common, it makes sense and it's
usually a bad idea.
But why? Well, let's consider why we need to have this property in the first place. In most domains, a property such as NumberOfOrders
doesn't comprise an intrinsic part of the customer. In other words, the information is interesting, but it doesn't belong inside the
customer document. Moreover, in order to keep this property up to date, we need to update it whenever we add an order, decrement it when
an order is deleted, etc. For that matter, what do we do about an order that was returned? Does it count? What about the replacement
order?
In other words, this is a pretty hefty business decision. But most of the time, this property is added because we want to show that value in the user interface, and issuing an aggregation query can be expensive. Or, rather, an aggregation query is expensive if you aren't using RavenDB.
With RavenDB, aggregation is handled via MapReduce operations, and you don't pay any cost at all for querying on the results of the aggregation. We dedicated a whole chapter (Chapter 11) to discussing this topic, so I'll go into the details there, but the impact of such a feature is profound. Cheap aggregation means that you can do a lot more of it, and you don't have to manage it yourself.
That frees you from a lot of worries, and it means you can focus on building your model as it's used. You can let RavenDB handle the side channel operations, like calculating exactly how many orders a customer has and in what state.
Another problem with customer.NumberOfOrders is how you update it. Two orders generated at once for the same customer may result
in lost updates and invalid data. How does RavenDB handle concurrency, and how does it impact your model?
Concurrency control
RavenDB is inherently concurrent, capable of handling hundreds of thousands8 of requests per second.
That leads to a set of interesting problems regarding concurrency. What happens if two requests are trying to modify the same document at the same time? That depends on what, exactly, you asked RavenDB to do. If you didn't do anything, RavenDB will execute those two modifications one at a time, and the last one will win. There's no way to control which would be last. Note that both operations will execute. That means that in certain cases, it will leave marks. In particular, if you have revisions enabled for this collection, there are going to be two revisions for this document. We'll discuss revisions in the next chapter.
Change Vectors in RavenDB
RavenDB makes extensive use of the notion of change vectors. A change vector is composed of a list of node IDs and etags. A node ID uniquely identifies a node, while an etag is a 64 bit number that is incremented on every operation in a database. Each time a document is modified, it's associated with the current etag value and a new change vector is generated.
This change vector uniquely marks the specific version of the document globally and is used for optimistic concurrency control, for various internal operations and caching. We'll discuss change vectors in detail in the Chapter 6.
The last write wins model is the default option in RavenDB except when you're creating a new document. When the RavenDB client API
is generating the ID, it knows it intends to create a new document, and it sets the expected change vector accordingly. So if the document
already exists, an error will be generated.
What about when you want to take advantage of this feature? You can ask RavenDB to enable optimistic concurrency at several levels. The following code enables optimistic concurrency for all sessions created by this document store.
store.Conventions.UseOptimisticConcurrency = true;
And you can also enable this on a more selective basis, on a particular session, using the following snippet:
session.Advanced.UseOptimisticConcurrency = true;
Or you can enable it on a single particular operation:
session.Store(entity, changeVector);
In all cases, the RavenDB client API will send the expected change vector to the server, which will compare it to the current change vector. If the
current change vector does not match the expected change vector, a ConcurrencyException will be thrown, aborting the entire transaction.
The first two options use the change vector that the server supplied when the document was loaded. In other words, they would error if the document was modified between the time we fetched it from the server and the time we wrote it back. The third option is a lot more interesting, though.
The ability to specify the change vector on a specific entity is quite important because it allows you to perform offline optimistic concurrency
checks. You can render a web page to the user and, along with the document data there, include the change vector that you got when you loaded that
document. The user can look at the document, modify it, and then send it back to your application. At that point, you'll store the
document with the tag as it was when we rendered the page to the user and call SaveChanges. If the document has been modified by
anyone in the meantime, the operation will fail.
In this manner, you don't need to keep the session around. You just need to pass the change vector back and forth. As you can see, the change vector is quite important for concurrency, but it also plays another important role with caching.
Caching
RavenDB uses REST over HTTP for communication between client and server. That means whenever you load a document or perform a
query, you're actually sending an HTTP call over the wire. This lets RavenDB take advantage of the nature of HTTP to play some
nice tricks.
In particular, the RavenDB client API is capable of using the nature of HTTP to enable transparent caching of all requests from the
server, which provides the client API with some assistance. Here's how it works. Each response from the server contains an
Etag header. In the case of loading a single document, that ETag header is also the document etag, but if we're querying or loading
multiple documents, that ETag header will contain a computed value.
On the client side, we'll cache the request from the server alongside the URL and the ETag value. When a new request comes in for the
same URL, we'll send it to server, but we'll also let the server know we have the result of the request with a specific ETag value.
On the server side, there are dedicated code paths that can cheaply check if the ETag we have on the client is the same as the
current one. If it is, we'll just let the client know that it can use the cached version, and that's it.
We don't have to execute any further code or send anything other than 304 Not Modified to the client. And on the client side, there's
no need to download any data from the server. We can access our local copy, already parsed and primed for us. That can represent
significant speed savings in some cases because we have to do a lot less work.
If the data has changed, we'll have a different ETag for the request, and the server will process it normally. The client will replace
the cached value and the process will repeat. You can take advantage of that when designing your software because you know certain
operations are likely to be cached and thus cheap.
RavenDB also has a feature called Aggressive Caching, which allows the RavenDB client API to register for changes from the server. At
that point, we don't even need to make a call to the server if we already have a cached value. We can wait for the server to let us know
that something has changed and that we need to call back to the database to see what that change was. For certain types of data — config/reference documents in particular — that can provide major performance savings.
Reference handling, Include and LoadDocument
Earlier in this chapter, we looked at various types of relationships between objects and documents, like embedding a value inside a larger document, many-to-one and many-to-many relationships and more. While we were focused on building our model, I skipped a bit on explaining how we work with relationships beyond the diagram stage. I'd like to return to that now.
There are two separate operations that we need to take into account. Fetching related information during a query or a document load can be
done using an Include call, which we already covered in Zero to RavenDB. I'm pointing this out again because it's a
very important feature that deserves more attention (and use). It's an incredibly powerful tool to reduce the number of
server requests when working with complex data.
The second operation is querying, or more to the point, when I want to query for a particular document based on the properties of a related
document. Going back to the kindergarten example, searching for all the children whose mothers' names are Lorina would be a great example.
The child document no longer contains the name of the parent, so how are we going to search for that? RavenDB doesn't allow you to perform
joins, but it does allow you to index related data during the indexing phase and then query on that. So querying the children by their
mothers' names is quite easy to do, using the LoadDocument feature. LoadDocument is discussed in full in
Chapter 10.
I'm mentioning it here because knowing that it exists has an impact on the way we model data. Be sure to read all about what
LoadDocument can do and how it works. It can be of great help when deciding how to model related data. In the end, though, the decision
almost always comes down to whether we want a point-in-time view of the data or the current value. For the first option,
we'll typically copy the value from the source to its own document, and for the second, we can use LoadDocument during indexing and
querying and Include when fetching the data from the server.
Attachments and binary data
RavenDB is a JSON document database, but not all data can be (or should be) represented in JSON. This is especially true when you consider that a document might reasonably include binary data. For example, when working with an order document, the invoice PDF might be something we need to keep.9. If we have a user document, the profile picture is another piece of binary data that is both part of the document and separate from it.
RavenDB's answer to that need is attachments. Attachments are binary data that can be attached to documents. An attachment is always on a document, and beyond the binary data, there's an attachment name (which must be unique within the scope of the parent document). Attachments are kept on the same storage as the documents, although in a separate location, and can be worked on together with documents.
That means attachments can participate in the same transaction as documents with the same ACID semantics (all in or none at all).
There's no size limit for attachments, and a single document can have multiple attachments.
The ability to store binary data easily is important for our modeling, especially because we can treat attachment changes as part of
our transaction. That means an operation such as "the lease is signed" can be done in a single transaction that includes both the update
of the Lease document and the storage of the signed lease scan in the same operation. That can save you a bit of a headache with error
handling.
When modeling, consider which external data is strongly related to the document and should be stored as an attachment. The easiest mental model I have for doing this is to consider attachments in email. Imagine that the document is the email content, and the attachments are just like attachments in email. Typically, such attachments provide additional information about the topic in question, and that's a good use case for attachments in RavenDB.
Revisions and Auditing
Tracking changes in data over time is a challenging task. Depending on the domain in question,10 we need to be able to show all changes that happened to a document. RavenDB supports that with its revisions feature.
The database administrator can configure RavenDB to keep track of document revisions. Whenever a document is changed, an immutable revision will be created, which can be used later on to follow all changes that happened to a document. RavenDB can be set to track only specific collections and to only keep track of the last N revisions, but often you'll choose "track everything" since disk space is relatively cheap and those domains need this accountability. It's better to keep too much than not enough.
Revisions also can apply to deletes, so you can restore a deleted document if you need to. One way of looking at revisions is as a way to have a copy of all changes on a per-document level.11
Auditing is a bit different. While revisions tell you what changed, auditing tells you by whom and typically what for. RavenDB supports this kind of auditing using client-side listeners, which can provide additional context for the document whenever it's changed. We'll discuss listeners and their use in more depth in Chapter 4.
Expiration
When storing documents inside RavenDB, you can specify that they will expire at a given point in time. RavenDB will periodically remove all the expired documents automatically. This is a relatively small feature, but it's nice to be able to implement functionality like "the link in this email will expire in 12 hours."
We'll see how to use the expiration feature in Chapter 4. There isn't much to say about it besides that it works, but it should be noted that the expiration is a soft one. In other words, if you specified an expiration time, the document might still be there after that time has passed because RavenDB didn't get around to cleaning it yet. By default, RavenDB will clear expired documents every minute. So the document might live just a bit longer than expected, but not terribly so.
ACID vs. BASE
The final topic in the modeling chapter is one of the more important ones. ACID stands for atomic, consistent, isolated and durable, while
BASE stands for basically available, soft state, eventually consistent. Those are two very different approaches for
dealing with data.
RavenDB uses both, in different parts of its operations. In general, ACID is what we always strive for. A fully consistent model makes
it easy to build upon and reason about, but it also can be quite expensive to build and maintain. In a distributed system, ensuring atomicity
can be quite expensive, since you need to talk to multiple machines for each operation, for example. On the other hand, BASE give us a lot more freedom, and that translates into a lot more optimization opportunities.
In RavenDB, all operations on a document or attachment using its ID (put, modify, delete) are always consistent and run in an
ACID transaction. Bulk operations over sets of documents (update all that match a particular query, bulk insert, etc.) are composed of
multiple separate transactions instead of one very big one.
By default, when you save a document into RavenDB, we'll acknowledge the write when the data has been saved on one node in a durable
fashion.12
You can also ask the write to be acknowledged only when the write has been made durable on multiple nodes (using
the WaitForReplicationAfterSaveChanges method) for additional safety. We discuss all such details in
Chapter 6.
One of the typical balancing acts that database administrators have to do is to choose how many indexes they will have. Too many indexes and the write process grinds to a halt. Not enough indexes and your queries are going to require table scans, which are horrendously expensive even on moderately sized databases.
The reason for the tradeoff is that a transaction must update all the relevant indexes on every change. That means that index updates are right there in the main pathway for updating data, which explains why they can so severely degrade performance. When designing our indexing implementation, we took a different approach.
Indexing in RavenDB is handled as an asynchronous task running in the background whenever there are updates to the database. This means that we don't have to wait for the index to finish updating before completing the write. And that means that we have far better opportunities for optimizations. For example, we can roll up multiple changes that happened in different transactions into the same index update batch.
This also allows us to be able to prioritize certain operations on the fly. If we're under a load of pressure right now, we can reduce the amount of time we spend indexing in order to serve more requests. This follows the idea that we always want to be able to return a result from RavenDB as soon as possible and that, in many cases, a triple-checked answer that came too late is worse than useless.
Indexes in RavenDB are BASE in the sense that they can lag behind the documents they reflect. In practice, indexes are kept up to date and
the lag time between a document update and an index update is typically measured in microseconds. The BASE nature of indexes allows us to
achieve a number of desirable properties. Adding an index to the system doesn't block anything, and updating an index definition can be done in
a side-by-side manner. Various optimizations are possible because of this (mostly related to batching and avoidance of locks).
What are the costs in waiting
Waiting for indexing or waiting for replication is something that you have to explicitly ask for because it costs. But what are those costs? In the case of replication, it means waiting for another server (or servers) to get the information and persist it safely to disk. That can add latency in the order of tens of milliseconds when running on a local data center — and hundreds of milliseconds if your cluster is going over the public internet.
For indexing, this is usually a short amount of time since the indexes are updated quickly. If there's a new index, it may take longer because the write will have to wait for the index to catch up not just with this write but also with all the writes that the new index is processing.
We typically measure RavenDB performance in tens or hundreds of thousands of requests per second. Even going with just 10,000 requests per second, that gives us a budget of 1/10 of a millisecond to process a request. Inside RavenDB, requests are handled in an async manner, so it isn't as if we're holding hundreds of threads open. But additional wait time for the request is something we want to avoid.
For the most part, those costs are pretty small, but there are times where they might be higher. If there's a new index running, and we asked to wait for all indexes, we may be waiting for a while. And we want the default behavior to be as predictable as possible. That isn't meant to discourage you from using these features, but we suggest that you give it some thought.
In particular, spraying the waits at any call is possible and it will work, but it's usually not the best solution. You typically want to apply them in specific scenarios: either high-value writes (and you want to make sure that it's saved on multiple nodes) or if you intend to issue a query immediately after the write and want to ensure that it will be included in the results. Otherwise, you should accept the defaults and allow RavenDB the freedom to optimize its operations.
The BASE on indexing behavior is optional. You can ask RavenDB to wait for the indexes to update (using the WaitForIndexesAfterSaveChanges method)
so you have the option of choosing. If this is a write you intend to immediately query, you can force a wait. Usually, that isn't required, so
you don't need to pay the cost here.
You need to be aware of the distinctions here between queries (which can be BASE and lag a bit13) and
bulk operations (many small transactions) and operations on specific documents (either one at a time or in groups), which happen as ACID transactions.
Taking advantage of the BASE nature of indexing allows you to reduce the cost of querying and writing, as well as selectively apply the decision
on a case-by-case basis.
Summary
Modeling data in RavenDB isn't a trivial topic, and it isn't over just because you finished this chapter. I tried to highlight certain features and their impact on modeling, but I suggest finishing the book and then reading this chapter again, with fresh perspective and a better understanding of how things are playing together.
We started by looking at RavenDB as a simple key/value store. Just throw data in (such as session information, shopping cart, etc.) and access it by a well-known key. That has the advantage of giving us fast operations without hiding the data behind an opaque barrier. We can also use the expiration feature to store time dependent data.
From the trivial model of key/value store, we moved to considering real document models. By looking at how documents in the real world — physical ones — are modeled, we made it much easier to explain document models to the business. Reducing the impedance mismatch between the business and the application is always a good thing, and proper modeling can help there. Of course, don't go too far. Remember that documents are virtual concepts and aren't limited to the physical world. We then looked at the issue of denormalization and noted the difference between the same value of the data and the same meaning of the data.
The next topic was actual modeling. We looked at how we should structure embedded values to store data that's intrinsically part of the document instead of holding that data outside of the document. We looked at how to model relations and collections, many-to-one and many-to-many associations. Then we covered more advanced modeling techniques, such as how to handle references and configuration data and how to deal with temporal information and hierarchical structures.
Next, we went over some of the constraints that we have to take into account when modeling, like how to deal with the growth of a document and what constitutes a good
size for a document in RavenDB. We looked at concurrency control and how change vectors are useful for optimistic concurrency and for caching. And we examined why we should avoid caching
aggregated data in our model (NumberOfOrders).
We looked at handling binary data with attachments, as well as auditing and change tracking using the revisions feature, and we learned that we can expire documents natively in RavenDB. Reference handling at indexing and query time was briefly covered (we'll cover it in depth in Chapter 9), as it's important to how you model your documents.
A repeating theme was the use of semantic IDs to give you better control over documents and their meaning — not so much for RavenDB's sake14 but because it increases understanding and visibility in your domain. Using document IDs to "nest" documents
such as accounts/1234/tx/2017-05 or having meaningful document IDs such as config/states helps a lot in setting out the structure for your model.
The final topic we covered was ACID vs. BASE in RavenDB. Documents in RavenDB are stored and accessed in an ACID manner, while we default
to BASE queries to get higher performance and have more chances for optimizations. This behavior is controlled by the user on a case-by-case basis, so you
can select the appropriate mode for each scenario.
Our next chapter is going to cover the client API in depth, going over all the tools that you have to create some really awesome behaviors. After that, we'll get to running clusters of RavenDB and understanding how the distributed portion of RavenDB is handled.
-
This ended up being sorted out eventually by uttering the magic words: "computer error." But it was very exciting for a while there.↩
-
The book is a bit dry, but I remember being very impressed when I read it the first time.↩
-
Circle the appropriate choice.↩
-
Except maybe which rabbit hole she wandered down...↩
-
The real Harry and Lorina had a total of 10 children, by the way.↩
-
I removed all extra information from the documents to make it clearer.↩
-
By default, that's set to 5 MB, and it's configurable.↩
-
Not a typo! In our benchmarks, we're always saturating the network long before we saturate any other resource, so the current limit is how fast your network cards are in packet processing.↩
-
A signed PDF invoice is pretty common, and you're required to keep it for tax purposes and can't just generate it on the fly.↩
-
This is common in insurance and healthcare, for example.↩
-
Obviously, this does not alleviate the need to have proper backups.↩
-
That means that the data has been written to disk and fsync() or the equivalent was called, so the data is safe from power loss.↩
-
The typical lag time for indexing is under 1 ms.↩
-
The database doesn't care what your document IDs look like.↩
