 Skip to Navigation
Skip to Navigation
Zero to RavenDB
The very first step we need to take in our journey to understand RavenDB is to get it running on our machine so we can actually get things done. I'm deferring discussion on what RavenDB is and how it works to a later part of this book because I think having a live version that you can play with will make it much easier to understand.
Setting RavenDB on your machine
For this section, I'm assuming that you're a developer trying to get a RavenDB instance so you can explore it. I'm going to ignore everything related to actual production deployments in favor of getting you set up in as few steps as possible. A full discussion on how to deploy, secure and run RavenDB in production is available in the "Production Deployments" chapter.
I'm going to go over a few quick install scenarios, and you can select whichever one makes the most sense for your setup. After that, you can skip to the next section, where we'll actually start using RavenDB.
Running on Docker
The easiest way to get RavenDB is probably via Docker. If you already have Docker installed, all you need to do is run the following command (using PowerShell):
$rvn_args = "--Setup.Mode=None --License.Eula.Accepted=true"
docker run `
-p 8080:8080 `
-e RAVEN_ARGS=$rvn_args `
ravendb/ravendb
Docker will now get the latest RavenDB version and spin up a new container to host it. Note that we run it in developer mode, without any authentication.
The output of this command should look something like Listing 2.1.
Listing 2.1 RavenDB Server Output
_____ _____ ____
| __ \ | __ \| _ \
| |__) |__ ___ _____ _ __ | | | | |_) |
| _ // _` \ \ / / _ \ '_ \| | | | _ <
| | \ \ (_| |\ V / __/ | | | |__| | |_) |
|_| \_\__,_| \_/ \___|_| |_|_____/|____/
Safe by default, optimized for efficiency
Build 40038, Version 4.0, SemVer 4.0.4-patch-40038, Commit 4837206
PID 7, 64 bits, 2 Cores, Phys Mem 1.934 GBytes, Arch: X64
Source Code (git repo): https://github.com/ravendb/ravendb
Built with love by Hibernating Rhinos and awesome contributors!
+---------------------------------------------------------------+
Using GC in server concurrent mode retaining memory from the OS.
Server available on: http://a698a4246832:8080
Tcp listening on 172.17.0.2:38888
Server started, listening to requests...
TIP: type 'help' to list the available commands.
ravendb> End of standard input detected, switching to server mode...
Running non-interactive.
You can now access your RavenDB instance using http://localhost:8080. If something is already holding port 8080
on your machine, you can map it to a different one using the -p 8081:8080 option.
Running on Windows
To set up RavenDB on Windows, you'll need to go to https://ravendb.net/download,
select the appropriate platform (Windows x64, in this case) and download the zip file containing the binaries.
Extract the file to a directory and then run the Start.cmd script or Server\Raven.Server.exe executable. This
will run RavenDB in interactive mode, inside a console application, and you can access the server by going to
http://localhost:8080 in your browser.
If something is already using port 8080, RavenDB will fail to start and give you an "address in use" error
(more specifically, EADDRINUSE). You can customize the port and host from the command line by issuing this command:
Server\Raven.Server.exe --ServerUrl=http://localhost:8081
That will run RavenDB on port 8081, avoiding the conflicting port issue. You might need to try another port as well if
port 8081 is also taken on your machine, of course.
Running on Linux
To set up RavenDB on Linux, you'll need to go to https://ravendb.net/download,
select the appropriate platform (Linux x64, most likely) and download the tar.bz2 file containing the binaries.
Extract the file to a directory and then run the run.sh script or ./Server/Raven.Server executable. This
will run RavenDB in interactive mode, inside a console application, and you can access the server by going to
http://localhost:8080 in your browser.
If something is already using port 8080, RavenDB will fail to start and give you an "address in use" error
(more specifically, EADDRINUSE). You can customize the port and host from the command line by issuing this
command:
./Server/Raven.Server.exe --ServerUrl=http://localhost:8081
That will run RavenDB on port 8081, avoiding the conflicting port issue. You might need to try another port as well if
port 8081 is also taken on your machine, of course.
Using the live demo instance
Without installing anything, you can point your browser to http://live-test.ravendb.net and access the public demo instance that we have available. This is useful for quick checks and verifications, but it isn't meant for anything more serious than that.
Obviously, all data in the live instance is public, and there are no guarantees about availability. We use this instance to try out the latest versions, so you should take that into consideration. In short, if you need to verify something small, go ahead and hit that instance. Otherwise, you'll need your own version.
Your first database
At this point, you've already set up an instance of RavenDB to work with, and you've loaded the RavenDB Studio in
your browser. For simplicity's sake, I'm going to assume from now on that you're running RavenDB on the local machine
on port 8080. Point your browser to http://localhost:8080, and you should be greeted with
an empty RavenDB instance. You can see how it looks in Figure 2.1.
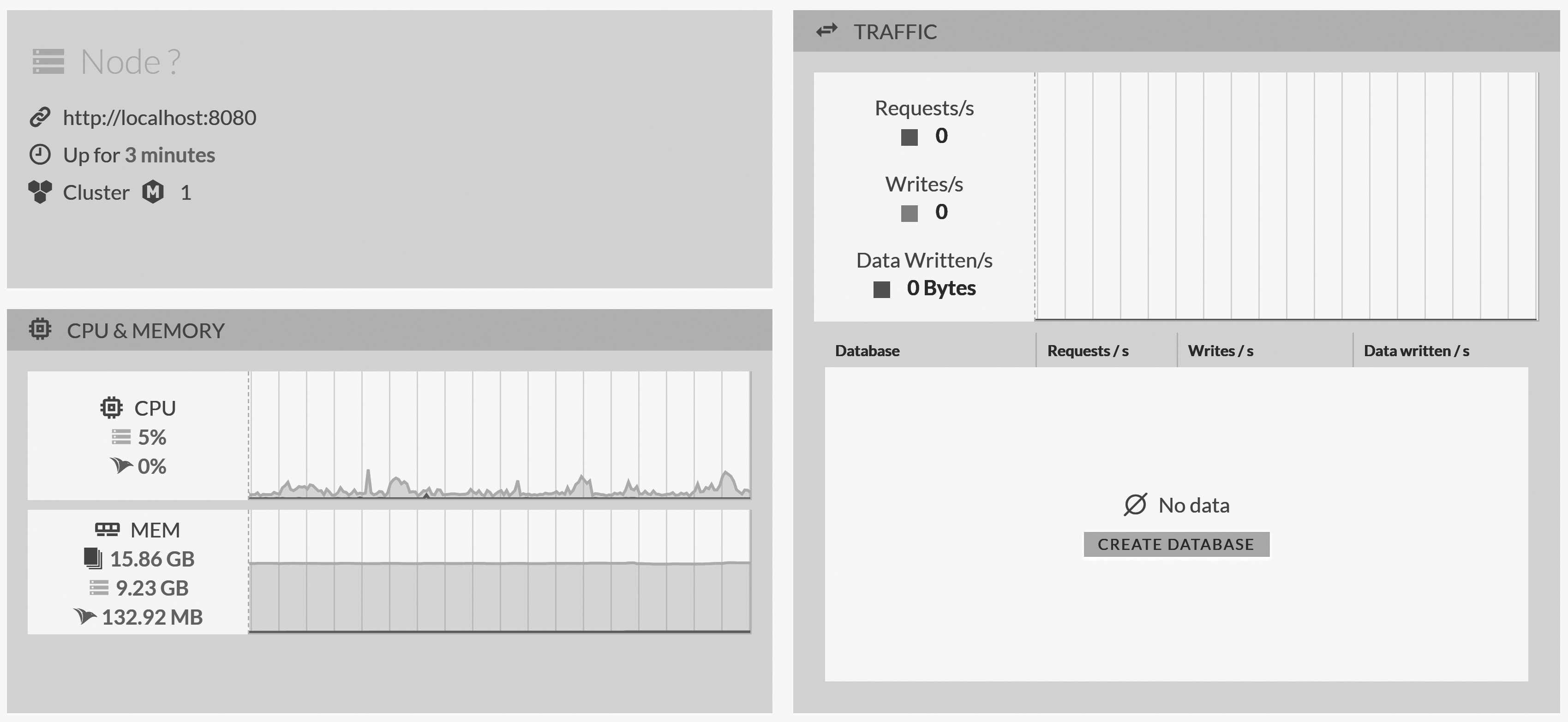
What we have right now is a RavenDB node that is a self-contained cluster.1 Now that we have a running node, the next step is to create a new database on this node.
You can do that by clicking the Create Database button, naming the new database Northwind and accepting all
the defaults in the dialog. We'll discuss what all of those mean later in this book.
Click the Create button, and that's pretty much it. Your new database is ready.
Click on the Databases button on the left to see what this looks, as shown in Figure 2.2.

Creating sample data
Of course, this new database contains no data, which makes it pretty hard to work with. We'll use the
sample data feature in RavenDB to have some documents to experiment with. Go to Create Sample Data under
Tasks in the left menu and click the Create button.
Clicking this button will populate the database with the sample Northwind dataset. For those not familiar with
Northwind, it's a sample dataset of an online store, and it includes common concepts such as orders, customers and
products. Let's explore this dataset inside of RavenDB.
On the left menu, select Documents, and you'll see a view similar to what's pictured in Figure 2.3, showing the recently created
documents and collections.
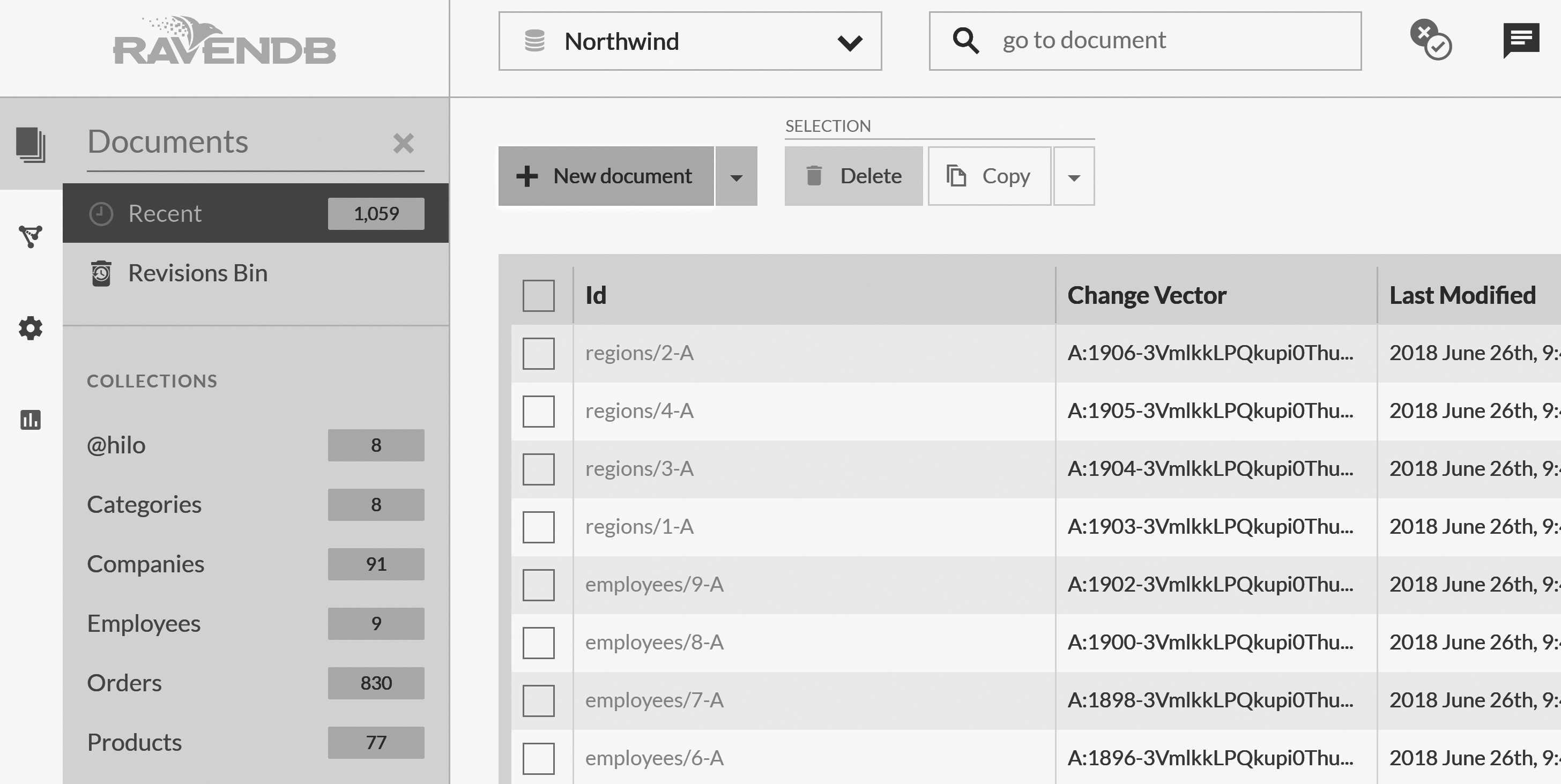
Collections are the basic building blocks inside RavenDB. Every document belongs to exactly one collection, and the collection typically holds similar documents (though it doesn't have to). These documents are most often based on the entity type of the document in your code. It's very similar to tables in a relational database, but unlike tables, there's no requirement that documents within the same collection will share the same structure or have any sort of schema.
Collections are very important to the way data is organized and optimized internally within RavenDB. We'll frequently use collections to group similar documents together and apply an operation to them (subscribing to changes, indexing, querying, ETL, etc.).
Our first real document
Click on the Orders collection and then on the first document in the listing, which should be orders/830-A. The
result is shown in Figure 2.4. For the first time, we're looking at a real JSON document inside of RavenDB.
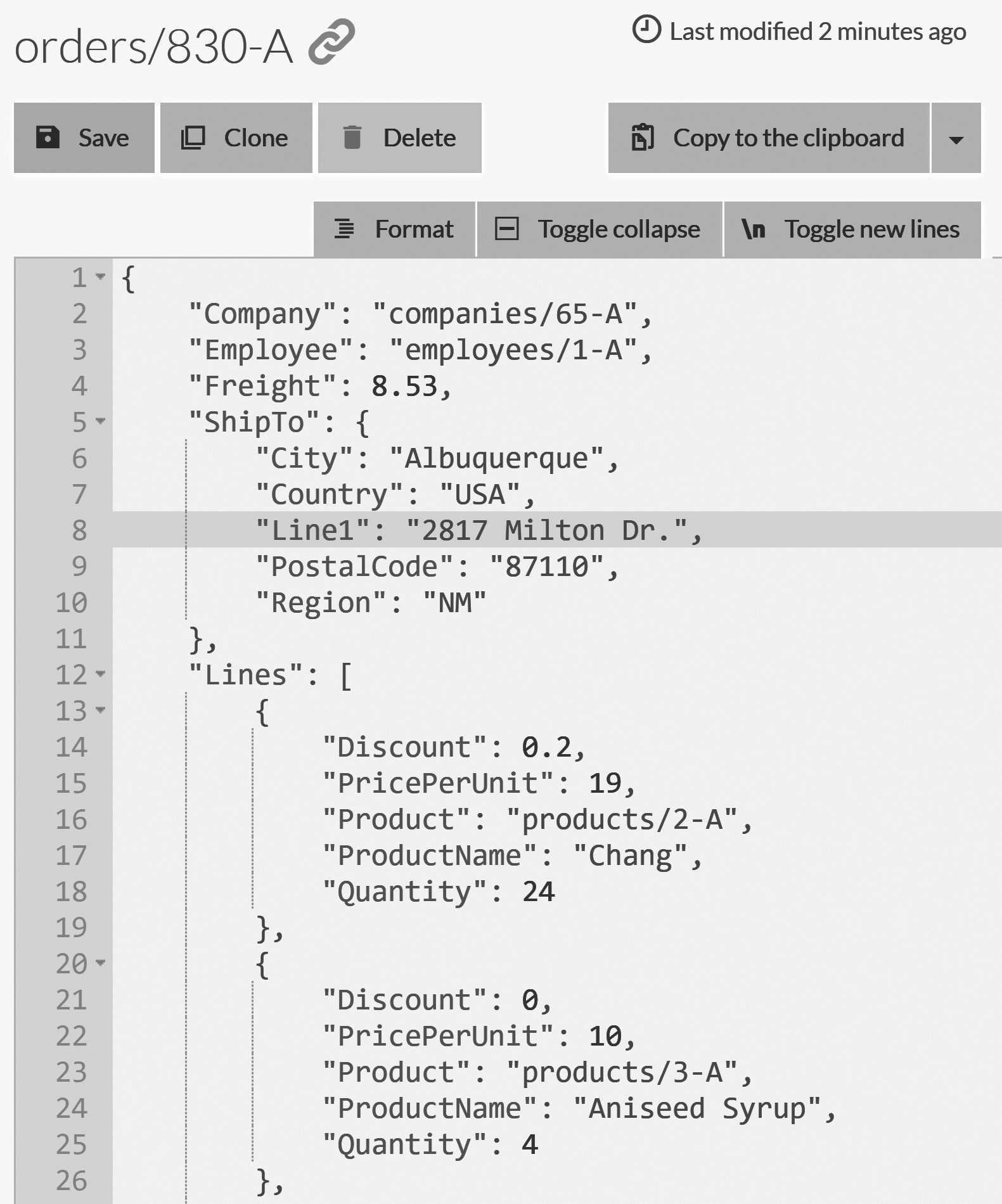
If you're used to working with non-relational databases, this is pretty obvious and not too exciting. But if you're mostly used to relational databases, there are several things to note here.
In RavenDB, we're able to store arbitrarily complex data as a single unit. If you look closely at Figure 2.4,
you'll see that instead of just storing a few columns, we can store rich information and work with nested
objects (the ShipTo property) or arrays of complex types (the Lines property).
This means that we don't have to split our data to satisfy the physical constraints of our storage. A whole object graph can be stored in a single document. Modeling will be further discussed in Chapter 3, but for now I'll just mention that the basic modeling method in RavenDB is based around root aggregates.
In the meantime, you can explore the different collections and the sample data in the Studio. We spent a lot of time and effort on the RavenDB Studio. Though it's pretty, I'll be the first to admit that looking at a syntax highlighted text editor isn't really that impressive. So let's see what kind of things we can do with the data as a database.
Working with the RavenDB Studio
This section will cover the basics of working with data within RavenDB Studio. If you're a developer, you're probably anxious to start seeing code. We'll get into that in the next section — no worries.
Creating and editing documents
When you look at a particular document, you can edit the JSON and click Save, and the document will be saved.
There isn't really much to it, to be honest. Creating new documents is a bit more interesting. Let's create a new
category document.
Go to Documents in the left menu, click Categories under Collections and select
New document in current collection, as shown in Figure 2.5.
This will open the editor with an empty, new document that's based on one of the existing categories. Note
that the document ID is set to categories/. Fill in some values for the properties in the new document and
save it. RavenDB will assign the document ID automatically for you.
One thing that may not be obvious is that while the Studio generates an empty document based on the existing ones, there is no such thing as schema in RavenDB, and you are free to add or remove properties and values and modify the structure of the document however you like. This feature makes evolving your data model and handling more complex data much easier.
Patching documents
The first thing we'll learn is how to do bulk operations inside the Studio. Go to
Documents on the left menu and click the Patch menu item. You'll be presented with the screen shown in Figure 2.6.
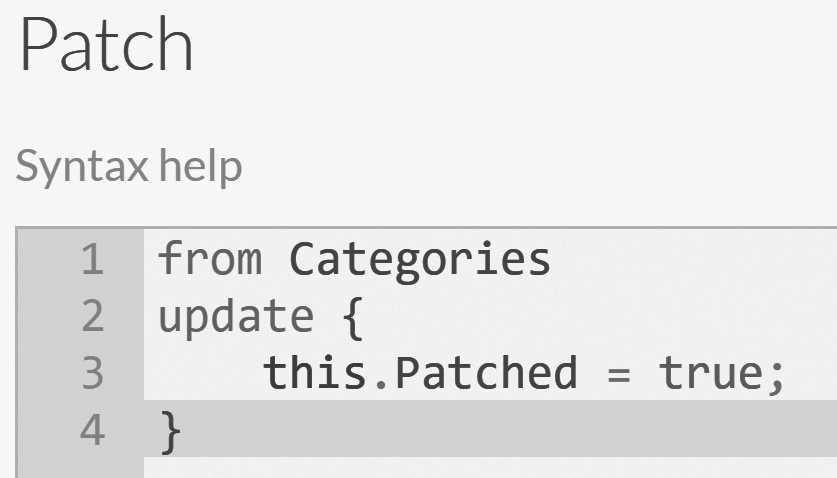
Patching allows you to write a query that executes a JavaScript transformation that can modify the matching documents.
To try this out, let's run a non-trivial transformation on the categories documents. Using a patch script,
we'll add localization support — the ability to store the category name and description in multiple languages.
Start by adding the code in Listing 2.2 to the query text.
Listing 2.2 Patching categories for internationalization support
from Categories
update {
this.Name = [
{ "Lang": "en-us", "Text": this.Name }
];
this.Description = [
{ "Lang": "en-us", "Text": this.Description }
];
}
Click the Test button, and you can see the results of running this operation: a category document. You can also select which
specific document this test will be tested on. The before-and-after results of running this script on categories/4-A are
shown in Figure 2.7.
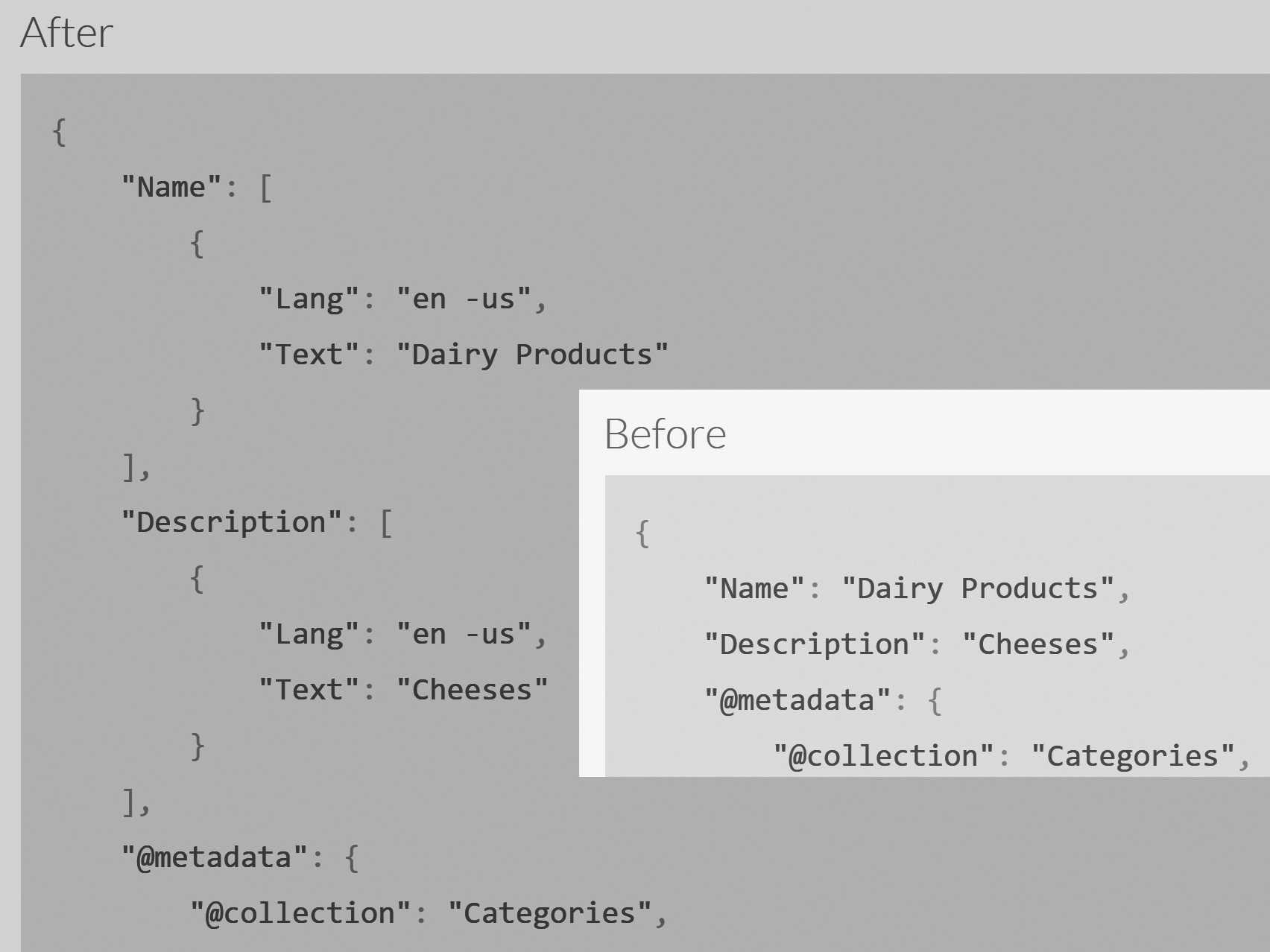
Patch scripts allow us to modify our documents en masse, and they are very useful when you need to reshape existing data. They can be applied on a specific document, a whole collection or all documents matching a specific query.
It's important to mention that for performance reasons, such bulk operations can be composed of multiple, independent and concurrent transactions instead of spanning a single large transaction. Each such independent transaction processes some portion of the data with full ACID properties (while the patch operation as a whole does not).
Deleting documents
If you want to delete a particular document in the Studio, you can simply go to the document and hit the Delete button.
You can delete a whole collection by going to the collection page (in the left
menu, choose Documents and then select the relevant collection in the Collections menu), selecting all the
documents in the header row and clicking Delete.
Querying documents
The previous sections talked about how to create, update and delete documents. But for full CRUD support, we still need to read documents. So far, we've looked at documents whose IDs were already known to us, and we've looked at entire collections. In this section, we'll focus on querying documents based on their data.
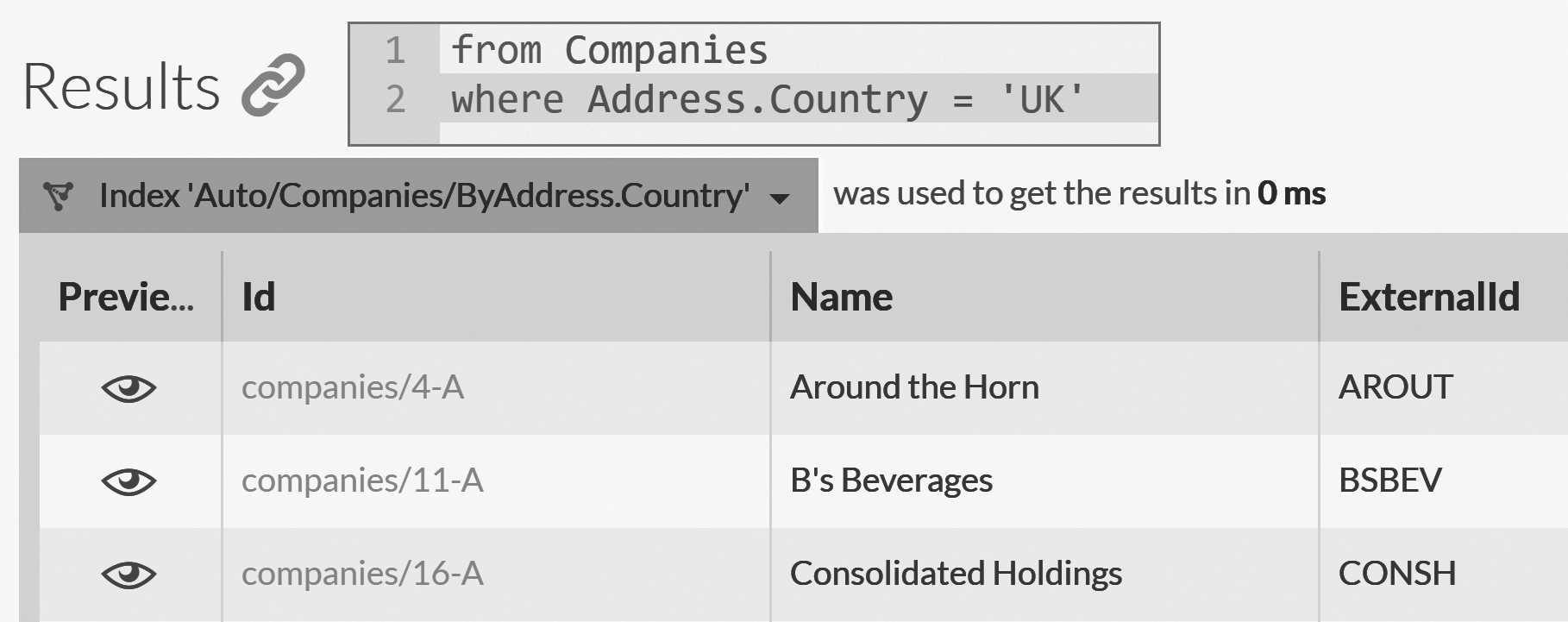
In the left menu, go to Indexes and then to Query. This is the main screen for querying documents in the
RavenDB Studio. Enter the following query and then click the query button: from Companies where Address.Country = 'UK'
You can see the results of this query in Figure 2.8.
The overview in this section was not meant to be a thorough walk-through of all options in RavenDB Studio, but only show you some basic usage so that you can get familiar with the Studio and be able to see the results of the coding done in the next section within the Studio.
Your first RavenDB program
We're finally at the good parts, where we can start slinging code around. For simplicity's sake, I'm going to use a simple console application to explore the RavenDB API. Typically, RavenDB is used in web/backend applications, so we'll also explore some of the common patterns of organizing your RavenDB usage in your application later in this chapter.
Most of the code samples in this book use C#, but the documentation can guide you on how to achieve the same results with any supported client.
Create a new console application with RavenDB, as shown Listing 2.3.
Listing 2.3 Installing RavenDB Client NuGet package
dotnet new console --name Rvn.Ch02
dotnet add .\Rvn.Ch02\ package RavenDB.Client --version 4.*
This will setup the latest client version for RavenDB 4.0 on the project. The next step is to add a namespace
reference by adding using Raven.Client.Documents; to the top of the Program.cs file.
And now we're ready to start working with the client API. The first thing we need to do is to set up access
to the RavenDB cluster that we're talking to. This is done by creating an instance of DocumentStore and
configuring it as shown in Listing 2.4.
Listing 2.4 Creating a document store pointed to a local instance
var store = new DocumentStore
{
Urls = new[] { "http://localhost:8080" },
Database = "Tasks"
};
store.Initialize();
This code sets up a new DocumentStore instance and lets it know about a single node — the one running on the local
machine — and that we are going to be using the Tasks database. The document store is the starting location for
all communication with the RavenDB cluster. It holds the configuration, topology, cache and any customizations that you might
have applied.
Typically, you'll have a single instance of a document store per application (singleton pattern) and use that same
instance for the lifetime of the application. However, before we can continue, we need to go ahead and create the
Tasks database in the Studio so we'll have a real database to work with.
The document store is the starting location for all RavenDB work, but the real workhorse is the session. The session is what will hold our entities, talk with the server and, in general, act as the front man to the RavenDB cluster.
Defining entities and basic CRUD
Before we can actually start using the session, we need something to actually store. It's possible to work with completely dynamic data in RavenDB, but that's a specific scenario covered in the documentation. Most of the time, you're working with your entities. For the purpose of this chapter, we'll use the notion of tasks to build a simple list of things to do.
Listing 2.5 shows what a class that will be saved as a RavenDB document looks like.
Listing 2.5 Entity class representing a task
public class ToDoTask
{
public string Id { get; set; }
public string Task { get; set; }
public bool Completed { get; set; }
public DateTime DueDate { get; set; }
}
This is about as simple as you can get, but we're only starting, so that's good. Let's create a new task inside RavenDB, reminding us that we need to pick up a bottle of milk from the store tomorrow. The code to perform this task (pun intended) is shown in Listing 2.6.
Listing 2.6 Saving a new task to RavenDB
using (var session = store.OpenSession())
{
var task = new ToDoTask
{
DueDate = DateTime.Today.AddDays(1),
Task = "Buy milk"
};
session.Store(task);
session.SaveChanges();
}
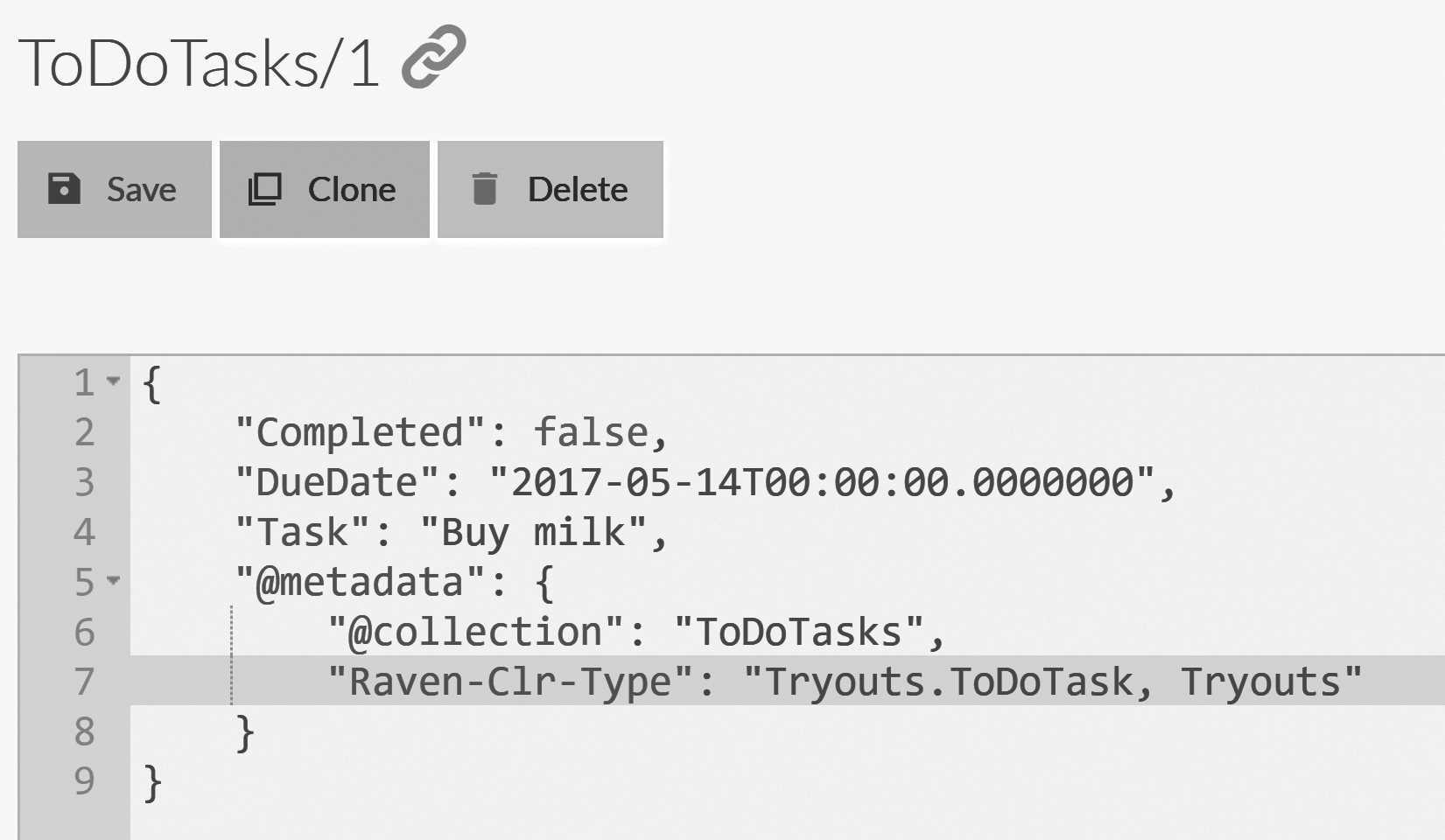
We opened a new session and created a new ToDoTask. We then stored the task in the session and called
SaveChanges to save all the changes in the session to the server. You can see the results of this in Figure 2.9.
As it so happened, I was able to go to the store today and get some milk, so I need to mark this task as completed. Listing 2.7 shows the code required to handle updates in RavenDB.
Listing 2.7 Loading, modifying and saving a document
using (var session = store.OpenSession())
{
var task = session.Load<ToDoTask>("ToDoTasks/1-A");
task.Completed = true;
session.SaveChanges();
}
Several interesting things can be noticed even in this very small sample. We loaded the document and modified it, and then
we called SaveChanges. We didn't need to call Store again. Because the task instance was loaded via the session,
it was also tracked by the session, and any changes made to it would be sent back to the server when SaveChanges
was called. Conversely, if the Completed property was already set to true, the RavenDB client would detect that
and do nothing since the state of the server and the client match.
The document session implements the Unit of Work and Identity Map design patterns. This makes it much easier to
work with complex behaviors since you don't need to manually track changes to your objects and decide what needs
to be saved and what doesn't. It also means that the only time the RavenDB client will send updates to the
server is when you call SaveChanges. That, in turn, means you'll experience a reduced number of network
calls. All of the changes will be sent as a single batch to the server. And because RavenDB is transactional, all those changes will happen as a single transaction, either completing fully or not at all.
Let's expand on that and create a few more tasks. You can see how this works in Listing 2.8.
Listing 2.8 Creating multiple documents in a single transaction
using (var session = store.OpenSession())
{
for (int i = 0; i < 5; i++)
{
session.Store(new ToDoTask
{
DueDate = DateTime.Today.AddDays(i),
Task = "Take the dog for a walk"
});
}
session.SaveChanges();
}
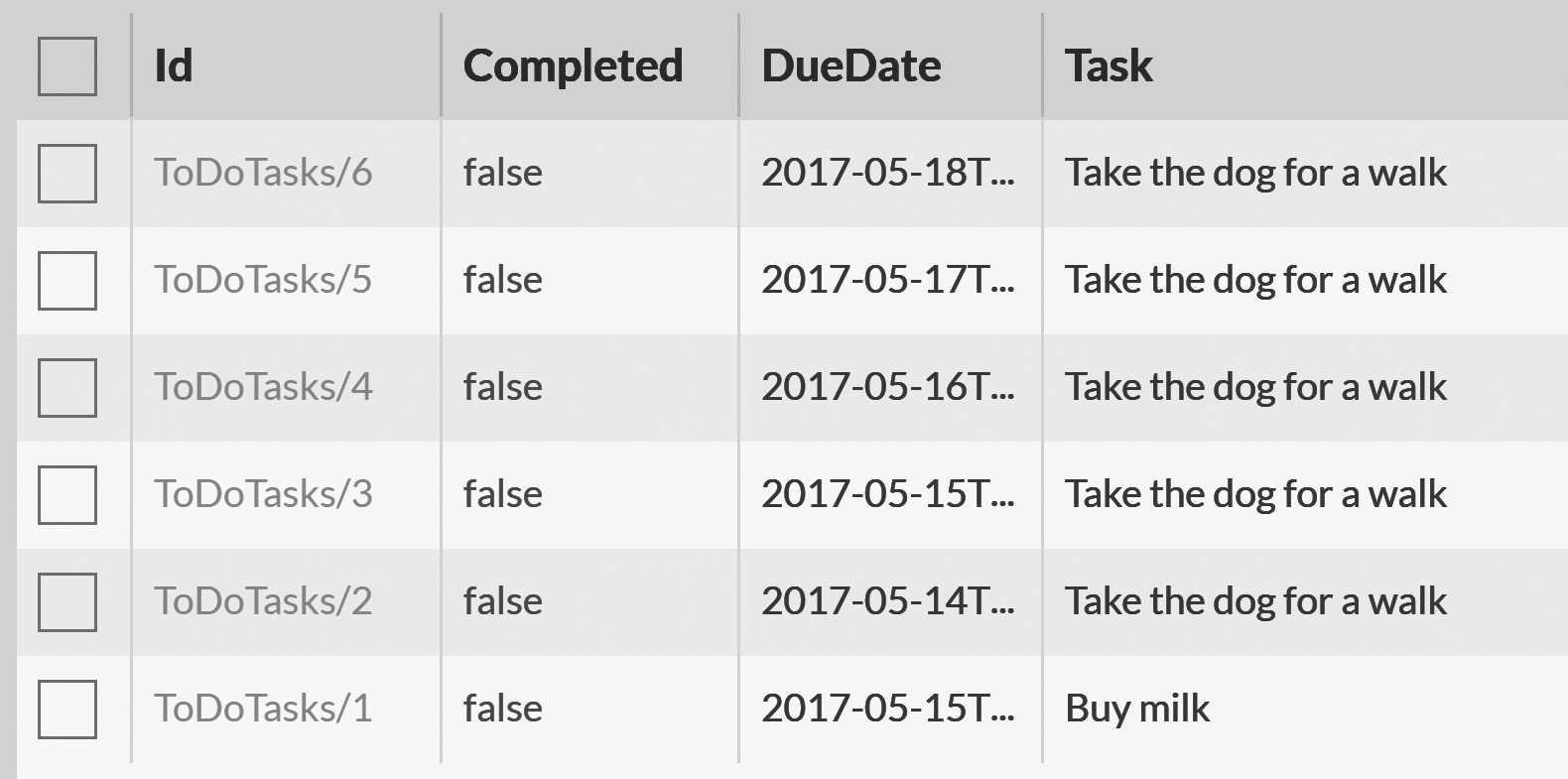
Figure 2.10 shows the end result of all this playing around we've done. We're creating five new tasks and saving them in
the same SaveChanges call, so they will be saved as a single transactional unit.
Querying RavenDB
Now that we have all these tasks, we want to start querying the data. Before we get to querying these tasks from code,
I want to show you how to query the data from the Studio. Go to Indexes and then Query in the Studio and you'll see the query page.
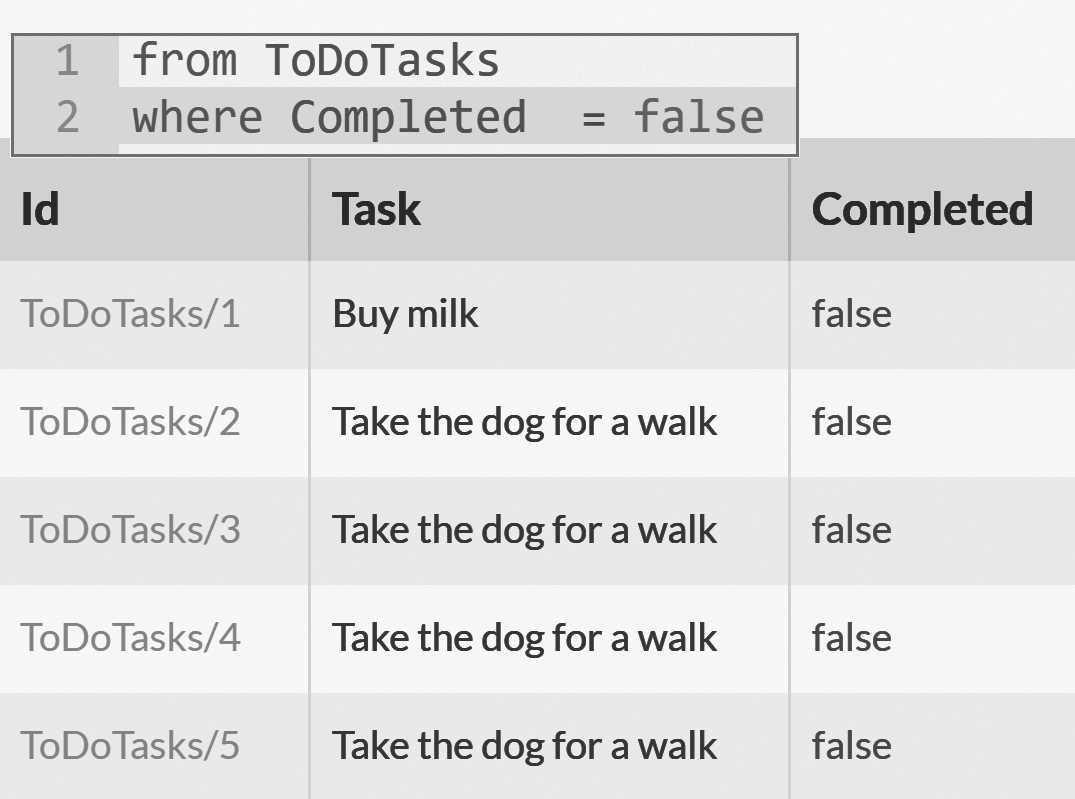
Let us find all the tasks we still have to do, we can do that using the following query: from ToDoTasks where Completed = false.
You can see the results of this in Figure 2.11.
We'll learn all about querying RavenDB in Part III. For now, let's concentrate on getting results, which means looking
at how we can query RavenDB from code. Let's say I want to know what kind of tasks I have for
the next couple of days. In order to get that information, I can use the query in Listing 2.9. (Remember to add using System.Linq;
to the top of the Program.cs file.)
Listing 2.9 Querying upcoming tasks using LINQ
using (var session = store.OpenSession())
{
var tasksToDo =
from t in session.Query<ToDoTask>()
where t.DueDate >= DateTime.Today &&
t.DueDate <= DateTime.Today.AddDays(2) &&
t.Completed == false
orderby t.DueDate
select t;
Console.WriteLine(tasksToDo.ToString());
foreach (var task in tasksToDo)
{
Console.WriteLine($"{task.Id} - {task.Task} - {task.DueDate}");
}
}
Running the code in Listing 2.9 gives the following output:
from ToDoTasks where DueDate between $p0 and $p1
and Completed = $p2 order by DueDate
ToDoTasks/2-A - Take the dog for a walk - 5/14/2017 12:00:00 AM
ToDoTasks/3-A - Take the dog for a walk - 5/15/2017 12:00:00 AM
ToDoTasks/4-A - Take the dog for a walk - 5/16/2017 12:00:00 AM
The query code sample shows us using LINQ to perform queries against RavenDB with very little hassle and no ceremony
whatsoever. There is actually a lot going on behind the scenes, but we'll leave all of that to
Part III. You can also see that we can call .ToString() on the query to get the query text from
the RavenDB client API.
Let's look at an aggregation query. The code in Listing 2.10 gives us the results of all the tasks per day.
Listing 2.10 Aggregation query on tasks
using (var session = store.OpenSession())
{
var tasksPerDay =
from t in session.Query<ToDoTask>()
group t by t.DueDate into g
select new
{
DueDate = g.Key,
TasksPerDate = g.Count()
};
// from ToDoTasks
// group by DueDate
// select key() as DueDate, count() as TasksPerDate
Console.WriteLine(tasksPerDay.ToString());
foreach (var tpd in tasksPerDay)
{
Console.WriteLine($"{tpd.DueDate} - {tpd.TasksPerDate}");
}
}
If you're familiar with LINQ, there isn't much to say about the code in Listing 2.10. It works, and it's obvious and easy to understand. If you aren't familiar with LINQ and working with the .NET platform, I strongly recommend learning it. From the consumer side, Linq is quite beautiful. Now, if you were to implement querying using LINQ, it's utterly atrocious — take it from someone who's done it a few times. But lucky for you, that isn't your problem. It's ours.
So far, we've explored the RavenDB API a bit, saved documents, edited a task and queried the tasks in various
ways. This was intended to familiarize you with the API and how to work with RavenDB. The client API was designed
to be very simple, focusing on the common CRUD scenarios. Deleting a document is as easy as calling session.Delete,
and all the complex options that you would need are packed inside the session.Advanced property.
Now that you have a basic understanding of how to write a Hello World in RavenDB, we're ready to dig deeper and
see the client API in all its glory.
The client API
We've already used a document store to talk with a RavenDB server. At the time, did you wonder what its purpose is? The
document store is the main entry point for the whole client API. It holds the server URLs, for one. (So far we used only a single server but
in many cases, our data can span across multiple nodes.) It also holds the default database we will want to operate on, as well as the
X509 client certificate that will be used to authenticate ourselves to the server.
Its importance goes beyond connection management, so let's take a closer look at it.
The document store
The document store holds all the client-side configuration, including serialization configuration, failover behavior, caching options and much more. In a typical application, you'll have a single document-store instance per application (singleton). Because of that, the document store is thread safe, with an initialization pattern that typically looks like the code in Listing 2.11.
Listing 2.11 Common pattern for initialization of the DocumentStore
public class DocumentStoreHolder
{
private readonly static Lazy<IDocumentStore> _store =
new Lazy<IDocumentStore>(CreateDocumentStore);
private static IDocumentStore CreateDocumentStore()
{
var documentStore = new DocumentStore
{
Urls = // urls of the nodes in the RavenDB Cluster
{
"https://ravendb-01:8080",
"https://ravendb-02:8080",
"https://ravendb-03:8080",
},
Certificate =
new X509Certificate2("tasks.pfx"),
Database = "Tasks",
};
documentStore.Initialize();
return documentStore;
}
public static IDocumentStore Store
{
get { return _store.Value; }
}
}
The use of "Lazy" ensures that the document store is only created once, without you having to worry about double locking or
explicit thread safety issues. And you can configure the document store as you see fit. The rest of the code can access the
document store using DocumentStoreHolder.Store. That should be relatively rare since, apart from configuring the document
store, the majority of the work is done using sessions.
Listing 2.11 shows how to configure multiple nodes, set up security and select the appropriate database. We'll learn about how to work with a RavenDB cluster in Chapter 6. We still have a lot to cover on the document store without getting to clusters, though.
Conventions
The client API, just like the rest of RavenDB, aims to just work. To that end, it's based on the notion of conventions: a series of policy decisions that have already been made for you. Those decisions range from which property holds the document ID to how the entity should be serialized to a document.
For the most part, we expect that you'll not have to touch the conventions. A lot of thought and effort has gone into ensuring you'll have little need to do that. But there's simply no way that we can foresee the future or anticipate every need. That's why most of the client API parts are customizable.
Customizations can be applied by changing various settings and behaviors via the DocumentStore.Conventions property. For example,
by default, the client API will use a property named Id (case sensitive) to store the document ID. But there are users
who want to use the entity name as part of the property name. So they'll have OrderId for orders, ProductId for products, etc.
2
Here's how we tell the client API to apply the TypeName + Id policy:
documentStore.Conventions.FindIdentityProperty =
prop => prop.Name == prop.DeclaringType.Name + "Id";
Don't worry. We won't go over all of the available options, since there are quite a few of them. Please refer to the online documentation to get the full list of available conventions and their effects. It might be worth your time to go over and quickly study them just to know what's available to you, even if they aren’t something that you'll touch all that often (or ever).
Beside the conventions, there are certain settings available directly from the document store level that you should be aware of, like default request timeouts, caching configuration and event handlers. We'll cover all of those later on. But for now, let’s focus on authentication.
Authentication
A database holds a lot of information. Usually, it's pretty important that you have control over who can access that information and what they can do with it. RavenDB fully supports this notion.
In development mode, you'll most commonly work in an unsecured mode, which implies that any connection will be automatically granted cluster administrator privileges. This reduces the number of things that you have to do upfront. But as easy as that is for development, for production, you'll want to run in a secure fashion. After doing so, all access to the server is restricted to authenticated users only.
Caution: unsecured network-accessible databases are bad for you.
By default, RavenDB will refuse to listen to anything but
localhostin an unsecured mode. This is done for security reasons, to prevent admins from accidentally exposing RavenDB without authentication over the network. If you attempt to configure a non-localhost URL with authentication disabled, RavenDB will answer all requests with an error page explaining the situation and giving instructions on how to fix the issue.You can let RavenDB know this is something you actually want, if you're running on a secure and isolated network. It requires an additional and explicit step to make sure this is your conscious choice and not an admin oversight.
RavenDB uses X509 client certificates for authentication. The good thing about certificates
is that they're not users. They're not tied to a specific person or need to be managed as such. Instead, they represent specific
access that was granted to the database for a particular reason. I find that this is a much more natural way to handle
authentication, and typically X509 client certificates are granted on a per application / role basis.
A much deeper discussion of authentication, managing certificates and security in general can be found in the Chapter 13.
The document session
The session (also called "document session", but we usually shorten it to just "session") is the primary way your code interacts with RavenDB. If you're familiar with Hibernate (Java), Entity Framework (.NET) or Active Record (Ruby), you should feel right at home. The RavenDB session was explicitly modeled to make it easy to work with.
Terminology
We tend to use the term "document" to refer both to the actual documents on the server and to manipulating them on the client side. It's common to say, "load that document and then..." But occasionally, we need to be more precise.
We make a distinction between a document and an entity (or aggregate root). A document is the server-side representation, while an entity is the client-side equivalent. An entity is the deserialized document that you work with in the client-side and save back to the database to become an updated server-side document.
We've already gone over the basics previously in this chapter, so you should be familiar with basic CRUD operations using the session. Let's look at the session with a bit more scrutiny. One of the main design forces behind RavenDB was the idea that it should just work. And the client API reflects that principle. If you look at the surface API for the session, here are the following high level options:
- Load()
- Include()
- Delete()
- Query()
- Store()
- SaveChanges()
- Advanced
Those are the most common operations that you'll run into on a day-to-day basis. And more options are available under the
Advanced property.
Disposing the session
The .NET implementation of the client API holds resources that must be freed. Whenever you make use of the session, be sure to wrap the variable in a
usingstatement or else do something to ensure proper disposal. Not doing so can force the RavenDB client to clean up using the finalizer thread, which can in turn increase the time it takes to release the acquired resources.
Load
As the name implies, this gives you the option of loading a document or a set of documents into the session. A document
loaded into the session is managed by the session. Any changes made to the document would be persisted to the database when
you call SaveChanges. A document can only be loaded once in a session. Let's look at the following code:
var t1 = session.Load<ToDoTask>("ToDoTasks/1-A");
var t2 = session.Load<ToDoTask>("ToDoTasks/1-A");
Assert.True(Object.ReferenceEquals(t1, t2));
Even though we called Load<ToDoTask>("ToDoTasks/1-A") twice, there's only a single remote call to the server and only a single
instance of the ToDoTask class. Whenever you load a document, it's added to an internal dictionary that the session
manages, and the session checks the dictionary to see if the document is already there. If
so, it will return the existing instance immediately. This helps avoid aliasing issues and also generally helps performance.
For those of you who deal with patterns, the session implements the Unit of Work and Identity Map patterns. This is most
obvious when talking about the Load operation, but it also applies to Query and Delete.
Load can also be used to read more than a single document at a time. For example, if I wanted three documents, I could use:
Dictionary<string, ToDoTask> tasks = session.Load<ToDoTask>(
"ToDoTasks/1-A",
"ToDoTasks/2-A",
"ToDoTasks/3-A"
);
This will result in a dictionary with all three documents in it, retrieved in a single remote call from the server. If a document we tried to load wasn't found on the server, the dictionary will contain null for that document ID.
Budgeting remote calls
Probably the easiest way to kill your application performance is to make a lot of remote calls. And a likely culprit is the database. It's common to see a web application making dozens of calls to the database to service a single request, usually for no good reason. In RavenDB, we've done several things to mitigate that problem. The most important among them is to allocate a budget for every session. Typically, a session would encompass a single operation in your system. An HTTP request or the processing of a single message is usually the lifespan of a session.
A session is limited by default to a maximum of 30 calls to the server. If you try to make more than 30 calls to the server, an exception is thrown. This serves as an early warning that your code is generating too much load on the system and is a circuit breaker.3
You can increase the budget, of course, but just having that warning in place ensures that you'll think about the number of remote calls you're making.
The limited number of calls allowed per session also means that RavenDB has a lot of options to reduce the number of calls. When you call SaveChanges(), you don't need to make a separate call per changed entity; you can go to the database once. In the same manner, we also allow you to batch read calls. We'll discuss the
Lazyfeature in more depth in Chapter 4.
The client API is pretty smart about it. If you try to load a document that was already loaded (directly or via Include), the
session can serve it directly from the session cache. And if the document doesn't exist, the session will also remember that it
couldn't load that document and will immediately return null rather than attempt to load the document again.
Working with multiple documents
We've seen how to work with a single document, and we even saved a batch of several documents into RavenDB in a single
transaction. But we haven't actually worked with anything more complex than a ToDoTask. That's pretty limiting, in terms
of the amount of complexity we can express. Listing 2.12 lets us add the notion of people who can be assigned tasks to the model.
Listing 2.12 People and Tasks model in RavenDB
public class Person
{
public string Id { get; set; }
public string Name { get; set; }
}
public class ToDoTask
{
public string Id { get; set; }
public string Task { get; set; }
public bool Completed { get; set; }
public DateTime DueDate { get; set; }
public string AssignedTo { get; set; }
public string CreatedBy { get; set; }
}
From looking at the model in Listing 2.12, we can learn a few interesting tidbits. First, we can see that each class stands on
its own. We don't have a Person property on ToDoTask or a Tasks collection on Person. We'll learn about modeling more
extensively in Chapter 3, but the gist of modeling in RavenDB is that each document is independent, isolated and coherent.
What does this mean? It means we should be able to take a single document and work with it successfully without having to look at or load additional documents. The easiest way to conceptualize this is to think about physical documents. With a physical document, I'm able to pick it up and read it, and it should make sense. References to other locations may be frequent, but there will usually be enough information in the document itself that I don't have to go and read those references.
In the case of the ToDoTask, I can look at my tasks, create new tasks or mark them as completed without having to look at the
Person document. This is quite a shift from working with relational databases, where traversing between rows and tables is
very common and frequently required.
Let's see how we can create a new task and assign it to a person. Listing 2.13 shows an interesting feature of RavenDB. Take a look and see if you can find the oddity.
Listing 2.13 Creating a new person document
using (var session = store.OpenSession())
{
var person = new Person
{
Name = "Oscar Arava"
};
session.Store(person);
Console.WriteLine(person.Id);
session.SaveChanges();
}
RavenDB is transactional, and we only send the request to the server on SaveChanges. So how could we print
the person.Id property before we called SaveChanges? Later in this chapter, we'll cover document identifiers and how they're
generated, but the basic idea is that the moment we returned from Store, the RavenDB client
ensured that we had a valid ID to use with this document. As you can see with Listing 2.14, this can be quite
important when you're creating two documents at the same time, with references between them.
Listing 2.14 Creating a new person and assigning him a task at the same time
using (var session = store.OpenSession())
{
var person = new Person
{
Name = "Oscar Arava"
};
session.Store(person);
var task = new ToDoTask
{
DueDate = DateTime.Today.AddDays(1),
Task = "Buy milk",
AssignedTo = person.Id,
CreatedBy = person.Id
};
session.Store(task);
session.SaveChanges();
}
Now that we know how to write multiple documents and create associations between documents, let's see how we read them back. There's a catch, though. We want to do it efficiently.
Includes
RavenDB doesn't actually have references in the usual sense. There's no such thing as foreign keys, like you might be used to. A reference to another document is just a string property that happens to contains the ID of another document. What does this mean for working with the data? Let's say that we want to print the details of a particular task, including the name of the person assigned to it. Listing 2.15 shows the obvious way to do this.
Listing 2.15 Displaying the details of a task (and its assigned person)
using (var session = store.OpenSession())
{
string taskId = Console.ReadLine();
ToDoTask task = session.Load<ToDoTask>(taskId);
Person assignedTo = session.Load<Person>(task.AssignedTo);
Console.WriteLine(
$"{task.Id} - {task.Task} by {assignedTo.Name}");
// will print 2
Console.WriteLine(session.Advanced.NumberOfRequests);
}
This code works, but it's inefficient. We're making two calls to the server here, one to fetch the task and another to fetch the assigned user. The last line of Listing 2.15 prints how many requests we made to the server. This is part of the budgeting and awareness program RavenDB has, aimed at reducing the number of remote calls and speeding up your applications.
Error handling
Listing 2.15 really bugged me when I wrote it, mostly because there's a lot of error handling that isn't being done: the task ID being empty, the task document not existing, the task not being assigned to anyone...you get the drift. I just wanted to mention that most code samples in this book will contain as little error handling as possible so as not to distract from the code that actually does things.
Having to go to the database twice is a pity because the server already knows the value of the AssignedTo property,
and it could send the document that matches the value of that property at the same time it's sending us the task. RavenDB's
Includes functionality, which handles this in one step, is a favorite feature of mine because I still remember how excited
I was when we finally figured out how to do this in a clean fashion. Look at Listing 2.16 to see how it works, and compare it
to Listing 2.15.
Listing 2.16 Task and assigned person - single roundtrip
using (var session = store.OpenSession())
{
string taskId = Console.ReadLine();
ToDoTask task = session
.Include<ToDoTask>(x => x.AssignedTo)
.Load(taskId);
Person assignedTo = session.Load<Person>(task.AssignedTo);
Console.WriteLine(
$"{task.Id} - {task.Task} by {assignedTo.Name}");
// will print 1
Console.WriteLine(session.Advanced.NumberOfRequests);
}
The only difference between the two code listings is that in Listing 2.16 we're calling to Include before the Load. The
Include method gives instructions to RavenDB: when it loads the document, it should look at the AssignedTo property. If there's a
document with the document ID that's stored in the AssignedTo property, it should send it to the client immediately.
However, we didn't change the type of the task variable. It remains a ToDoTask. So what exactly did this Include method
do here? What happened is that the session got a reply from the server, saw that there are included documents, and put them
in its Identity Map. When we request the Person instance that was assigned to this task, we already have that information
in the session and can avoid going back to the server to fetch the same document we already have.
The API is almost the same — and except for that call, everything else remains the same — but we managed to significantly cut
the number of remote calls we make. You can Include multiple properties to load several referenced documents (or even a
collection of them) efficiently. This is similar to a JOIN in a relational database, but it's much more efficient since you don't
have to deal with Cartesian products and it doesn't modify the shape of the results.
Includes aren't joins
It's tempting to think about includes in RavenDB as similar to a join in a relational database. And there are similarities, but there are also fundamental differences. A join will modify the shape of the output. It combines each matching row from one side with each matching row on the other, sometimes creating Cartesian products that can cause panic attacks for your DBAs.
And the more complex your model, the more joins you'll have, the wider your result sets become and the slower your application will become. In RavenDB, there's very little cost to adding includes. That's because they operate on a different channel than the results of the operation and don't change the shape of the returned data.
Includes are also important in queries. There, they operate after paging has applied, instead of before, like joins.
The end result is that includes don't modify the shape of the output, don't have a high cost when you use more than one of them and don't suffer from problems like Cartesian products.
Include cannot, however, be used to include documents that are referenced by included documents. In other words, Include is
not recursive. This is quite intentional because allowing includes on included documents will lead to complex requests,
both for the user to write and understand and for the server to execute. You can actually do recursive includes in RavenDB,
but that feature is exposed differently (via the declare function mode, which we'll cover in Chapter 9).
Using multiple Includes on the same operation, however, is just fine. Let's load a task, and with it we'll include both the
assigned to person and the one who created the task. This can be done using the following snippet:
ToDoTask task = session.Include<ToDoTask>(x => x.AssignedTo)
.Include(x => x.CreatedBy)
.Load(taskId);
Now I can load both the AssignedTo person and the CreatedBy one, and there's still only a single round trip to the server.
What about when both of them are pointing at the same document? RavenDB will return just a single copy of the document, even if
it was included multiple times. On the session side of things, you'll get the same instance of the entity when you load it
multiple times.
Beware of relational modeling inside of RavenDB
As powerful as the
Includefeature is, one of the most common issues we run into with RavenDB is people using it with a relational mindset — trying to use RavenDB as if it was a relational database and modeling their entities accordingly.Includecan help push you that way because it lets you get associated documents easily.
We'll talk about modeling in a lot more depth in the next chapter, when you've learned enough about the kind of environment that RavenDB offers to make sense of the choices we'll make.
Delete
Deleting a document is done through the appropriately named Delete method. This method can accept an entity instance or a
document ID. The following are various ways to delete a document:
var task = session.Load<ToDoTask>("ToDoTasks/1-A");
session.Delete(task); // delete by instance
session.Delete("ToDoTasks/1-A"); // delete by ID
It's important to note that calling Delete doesn't actually delete the document. It merely marks that document as deleted
in the session. It's only when SaveChanges is called that the document will be deleted.
Query
Querying is a large part of what RavenDB does. Not surprisingly, queries strongly relate to indexes, and we'll talk about those extensively in Part III. You've already seen some basic queries in this chapter, so you know how we can query to find documents that match a particular predicate, using LINQ.
Like documents loaded via the Load call, documents that were loaded via a Query are managed by the session. Modifying
them and calling SaveChanges will result in their update on the server. A document that was returned via a query and was
loaded into the session explicitly via Load will still have only a single instance in the session and will retain all the
changes that were made to it.4
Queries in RavenDB don't behave like queries in a relational database. RavenDB doesn't allow computation during queries, and it doesn't have problems with table scans or slow queries. We'll touch on exactly why and cover details about indexing in Part III, but for now you can see that most queries will just work for you.
Store
The Store command is how you associate an entity with the session. Usually, this is done because you want to create a new
document. We've already seen this method used several times in this chapter, but here's the relevant part:
var person = new Person
{
Name = "Oscar Arava"
};
session.Store(person);
Like the Delete command, Store will only save the document to the database when SaveChanges is called. However,
it will give the new entity an ID immediately, so you can refer to it in other documents that you'll save in the same batch.
Beyond saving a new entity, Store is also used to associate entities of existing documents with the session. This is common
in web applications. You have one endpoint that sends the entity to the user, who modifies that entity and then sends it back to
your web application. You have a live entity instance, but it's not loaded by a session or tracked by it.
At that point, you can call Store on that entity, and because it doesn't have a null document ID, it will be treated as an
existing document and overwrite the previous version on the database side. This is instead of having to load the database
version, update it and then save it back.
Store can also be used in optimistic concurrency scenarios, but we'll talk about this in more detail in Chapter 4.
SaveChanges
The SaveChanges call will check the session state for all deletions and changes. It will then send all of those to the server as a
single remote call that will complete transactionally. In other words, either all the changes are saved as a single unit or
none of them are.
Remember that the session has an internal map of all loaded entities. When you call SaveChanges, those loaded entities
are checked against the entity as it was when it was loaded from the database. If there are any changes, that entity will be
saved to the database.
It's important to understand that any change would force the entire entity to be saved. We don't attempt to make partial
document updates in SaveChanges. An entity is always saved to a document as a single full change.
The typical way one would work with the session is:
using (var session = documentStore.OpenSession())
{
// do some work with the session
session.SaveChanges();
}
So SaveChanges is usually only called once per session, although there's nothing wrong with calling it multiple times. If
the session detects that there have been no changes to the entities, it will skip calling the server entirely.
With this, we conclude the public surface area of the session. Those methods allow us to do about 90% of everything you
could wish for with RavenDB. For the other 10%, we need to look at the Advanced property.
Advanced
The surface area of the session was carefully designed so that the common operations were just a method call away from the session, and that there would be few of them. But while this covers many of the most common scenarios, it isn't enough to cover them all.
All of the extra options are hiding inside the Advanced property. You can use them to configure the behavior of optimistic concurrency on a per-session basis using:
session.Advanced.UseOptimisticConcurrency = true;
Or you can define it once globally by modifying the conventions:
documentStore.Conventions.UseOptimisticConcurrency = true;
You can force a reload of an entity from the database to get the changes made since the entity was last loaded:
session.Advanced.Refresh(product);
And you can make the session forget about an entity completely (it won't track it, apply changes, etc.):
session.Advanced.Evict(product);
I'm not going to go over the Advanced options here. There are quite a few, and they're covered in the documentation quite nicely.
It's worth taking the time to read about, even if you'll rarely need the extra options.
Hiding the session: avoid the
IRepositorymessA common problem we see with people using the client API is that they frequently start by defining their own data access layer, usually named
IRepositoryor something similar.This is generally a bad idea. We've only started to scratch the surface of the client API, and you can already see there are plenty of valuable features (
Includes, optimistic concurrency, change tracking). Hiding behind a generic interface typically results in one of two situations:
Because a generic interface doesn't expose the relevant (and useful) features of RavenDB, you're stuck with using the lowest common denominator. That means you give up a lot of power and flexibility, and in 99% of cases, the interface won't allow you to switch between data store implementations.5
The second situation is that, because of issues mentioned in the previous point, you expose the RavenDB features behind the
IRepository. In this case, you're already tied to the RavenDB client, but you added another layer that doesn't do much but increase code complexity. This can make it hard to understand what's actually going on.The client API is meant to be easy to use and high level enough that you'll not need to wrap it for convenience’s sake. In all likelihood, if you do wrap it, you'll just wind up forwarding calls back and forth.
One thing that's absolutely wrong to do, however, is to have methods like
T IRepository.Get<T>(string id)that will create and dispose of a session within the scope of theGetmethod call. That cancels out a lot of optimizations, behaviors and functionality,6 and it would be a real shame for you to lose these features of RavenDB.
The Async Session
So far, we've shown only synchronous work with the client API. But async support is crucial for high performance applications. That's why RavenDB has full support for it. In fact, that's the recommended mode, and the synchronous version is actually built on top of the async version. The async API is exposed via the async session. In all respects, it's identical to the sync version.
Listing 2.17 Working with the async session
using (var session = documentStore.OpenAsyncSession())
{
var person = new Person
{
Name = "Oscar Arava"
};
await session.StoreAsync(person);
await session.SaveChangesAsync();
}
using (var session = documentStore.OpenAsyncSession())
{
var tasksPerDayQuery =
from t in session.Query<ToDoTask>()
group t by t.DueDate into g
select new
{
DueDate = g.Key,
TasksPerDate = g.Count()
};
List<ToDoTask> tasksToDo = await tasksPerDayQuery.ToListAsync();
foreach (var task in tasksToDo)
{
Console.WriteLine($"{task.Id} - {task.Task} - {task.DueDate}");
}
}
Listing 2.17 shows a few examples of working with the async session. For the rest of the book, we'll use both the async and synchronous sessions to showcase features and behavior of RavenDB.
RavenDB splits the sync and async API because their use cases are quite different, and having separate APIs prevents you from doing some operations synchronously and some operations asynchronously. Because of that, you can't mix and use the synchronous session with async calls or vice versa. You can use either mode in your application, depending on the environment you're using. Aside from the minor required API changes, they're completely identical.
The async support is deep — all the way to the I/O issued to the server. In fact, as I mentioned earlier, the synchronous API is built on top of the async API and async I/O.
We covered the basics of working with the client API in this section, but that was mostly mechanics. We'll dive deeper into using RavenDB in the next chapter, where we'll also learn how it's all put together.
Going below the session
"Ogres are like onions," said Shrek. In a way, so is the client API. At the top, and what you'll usually interact
with, are the document store and the document session. They, in turn, are built on top of the notion of Operations
and Commands. An Operation is a high level concept, such as loading a document from the server.
Deep dive note
I'm going to take a small detour to explain how the client API is structured internally. This shouldn't have an impact on how you're using the client API, but it might help you better understand how the client is put together. Feel free to skip this section for now and come back to it at a later date.
The LoadOperation is the canonical example of this. A session Load or LoadAsync will translate into a call to the
LoadOperation, which will run all the associated logic (Identity Map, Include tracking, etc.) up to the point where it
will make a call to the server. That portion is handled by the GetDocumentCommand, which knows how to ask the server for a document
(or a set of documents) and how to parse the server reply.
The same GetDocumentCommand is also used by the session.Advanced.Refresh method to get an updated version of the document
from the server. You won't typically be using any of that directly, going instead through the session. Occasions to use an Operation
directly usually arise when you're writing some sort of management code, such as Listing 2.18, which creates a new database
on the cluster.
Listing 2.18 Creating a database named 'Orders' using Operation
var dbRecord = new DatabaseRecord("Orders");
var createDbOp = new CreateDatabaseOperation(dbRecord);
documentStore.Admin.Server.Send(createDbOp);
A lot of the management functionality (creating and deleting databases, assigning permissions, changing configuration, etc.) is available as operations that can be invoked in such a manner.
In other cases, you can use an Operation to run something that doesn't make sense in the context of a session. For example,
let's say I wanted to delete all of the tasks in the database. I could do it with the following code:
store.Operations.Send(new DeleteByQueryOperation(
new IndexQuery { Query = "from ToDoTasks" }
));
The reason that the tasks are exposed to the user is that the RavenDB API, at all levels, is built with the notion of layers. The expectation is that you'll usually work with the highest layer: the session API. But since we can't predict all things, we also provide access to the lower level API, on top of which the session API is built, so you can use it if you need to.
Document identifiers in RavenDB
The document ID is a unique string that globally identifies a document inside a RavenDB database. A document ID can be any
UTF8 string up to 2025 bytes, although getting to those sizes is extremely rare. You've already seen document IDs used in
this chapter — people/1-A, ToDoTasks/4-A and the like. Using a Guid like 92260D13-A032-4BCC-9D18-10749898AE1C
is possible but not recommended because it's opaque and hard to read/work with.
By convention, we typically use the collection name as the prefix, a slash and then the actual unique portion of the key. But
you can also call your document hello/world or what-a-wonderful-world. For the adventurous, Unicode is also a valid
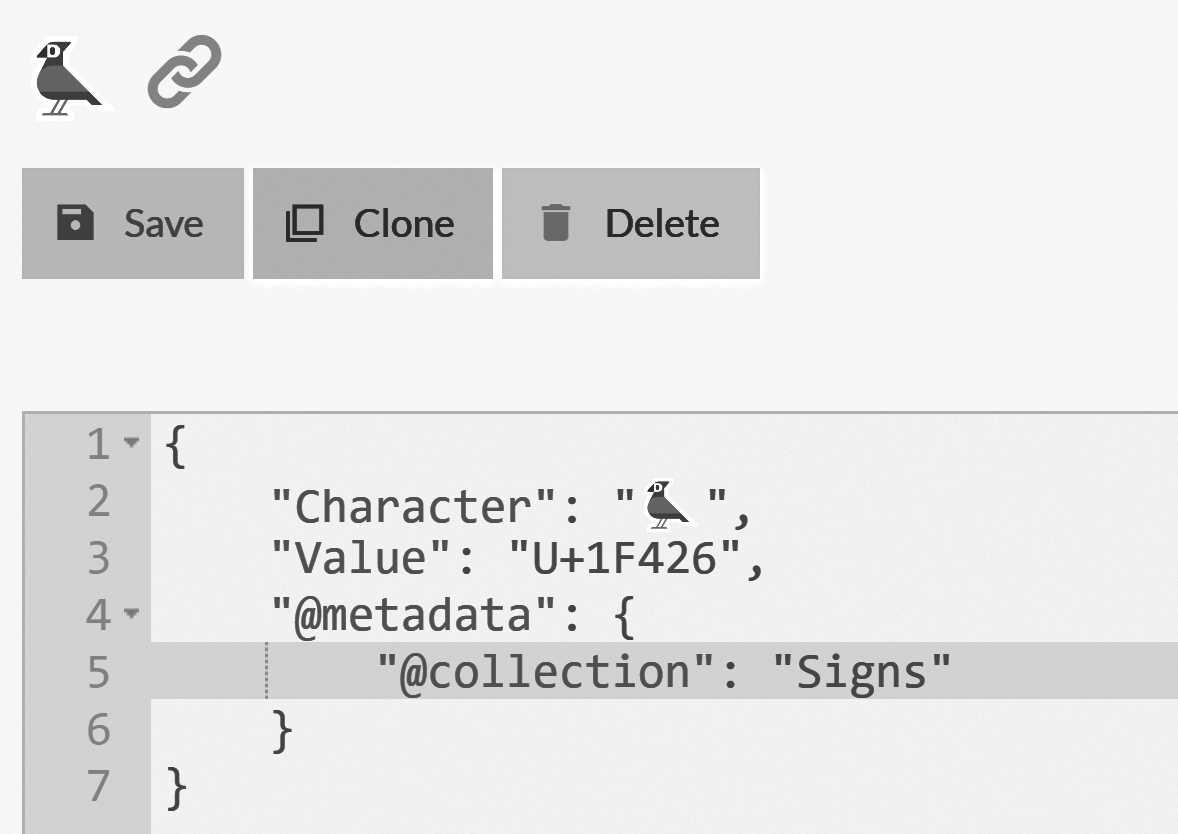
option. The character U+1F426 is a valid document ID, and trying to use it in RavenDB is possible, as you can
see in Figure 2.12. Amusingly enough, trying to include a raw emoji character broke the build for this book.
While going full-on emoji for document identifiers might be going too far7, using Unicode for document IDs means that you don't have to worry if you need to insert a Unicode character (such as someone's name).
RavenDB and Unicode
I hope it goes without saying that RavenDB has full support for Unicode. Storing and retrieving documents, querying on Unicode data and pretty much any related actions are supported. I haven't talked about it so far because it seems like an obvious requirement, but I think it's better to state this support explicitly.
So RavenDB document IDs are Unicode strings up to 2025 bytes in length, which must be globally unique in the scope of the database. This is unlike a relational database, in which a primary key must only be unique in the scope of its table. This has never been a problem because we typically use the collection name as the prefix to the document key. Usually, but not always, there's no requirement that a document in a specific collection will use the collection name prefix as the document key. There are a few interesting scenarios that open up because of this feature, discussed later in this section.
Human-readable document IDs
Usually, we strongly recommend to have document IDs that are human-readable (
ToDoTasks/123-A,people/oscar@arava.example). We often use identifiers for many purposes. Debugging and troubleshooting are not the least of those.A simple way to generate IDs is to just generate a new
Guid, such as92260D13-A032-4BBC-9D18-10749898AE1C. But if you've ever had to read aGuidover the phone, keep track of multipleGuids in a log file or just didn't realize that theGuidin this paragraph and the one at the start of this section aren't, in fact, the same Guid...If you're anything like me, you went ahead and compared the two
Guids to see if they actually didn't match. Given how hard finding the difference is, I believe the point is made.Guids are not friendly, and we want to avoid having to deal with them on an ongoing basis if we can avoid it.
So pretty much the only thing we require is some way to generate a unique ID as the document ID. Let's see the strategies that RavenDB uses to allow that.
Semantic (external) document identifiers
The most obvious way to get an identifier is to ask the user to generate it. This is typically done when you want an
identifier that's of some meaningful value. For example, people/oscar@arava.example or accounts/591-192 are two document IDs
that the developer can choose. Listing 2.19 shows how you can provide an external identifier when creating documents.
Listing 2.19 Saving a new person with an externally defined document ID
using (var session = store.OpenSession())
{
var person = new Person
{
Name = "Oscar Arava"
};
session.Store(person, "people/oscar@arava.example");
session.SaveChanges();
}
The people/oscar@arava.example example, which uses an email address in the document identifier, is a common technique to generate a
human-readable document identifier that makes it easy to locate a document based on a user provided value (the email). While
the accounts/591-192 example uses a unique key that's defined in another system. This is common if you're integrating with
existing systems or have an external feed of data into your database.
Nested document identifiers
A special case of external document naming is when we want to handle nested documents. Let's consider a financial system that
needs to track accounts and transactions on those accounts. We have our account document accounts/591-192, but we
also have all the financial transactions concerning this account that we need to track.
We'll discuss this exact scenario in the next chapter, where we'll talk about modeling, but for now I'll just say that it isn't
practical to hold all the transactions directly inside the account document. So we need to put the transactions in separate documents.
We could identify those documents using transactions/1234-A, transactions/1235-A, etc. It would work, but there are better ways.
We're going to store the transaction information on a per-day basis, using identifiers that embed both the owner account and the
time of the transactions: accounts/591-192/txs/2017-05-17. This document holds all the transactions for the 591-192
account for May 17th, 2017.
RavenDB doesn't care about your document IDs
RavenDB treats the document IDs as opaque values and doesn't attach any meaning to a document whose key is the prefix of other documents. In other words, as far as RavenDB is concerned, the only thing that
accounts/591-192andaccounts/591-192/txs/2017-05-17have in common is that they're both documents.In practice, the document IDs are stored in a sorted fashion inside RavenDB, and it allows for efficient scanning of all documents with a particular prefix quite cheaply. But this is a secondary concern. What we're really trying to achieve here is to make sure our document IDs are very clear about their contents.
You might recall that I mentioned that RavenDB doesn't require documents within a given collection to be have an ID with the collection prefix. This is one of the major reasons why — because it allows you to nest document IDs to get yourself a clearer model of your documents.
Client-side identifier generation (hilo)
External identifiers and nesting document IDs are nice, but they tend to be the exception rather than the rule. For the most part, when we create documents, we don't want to have to think about what IDs we should be giving them. We want RavenDB to just handle that for us.
RavenDB is a distributed database
A minor wrinkle in generating identifiers with RavenDB is that the database is distributed and capable of handling writes on any of the nodes without requiring coordination between them. On the plus side, it means that in the presence of failures we stay up and are able to process requests and writes. On the other hand, it can create non-trivial complexities.
If two clients try to create a new document on two nodes in parallel, we need to ensure that they will not accidentally create documents with the same ID.8
It's important to note, even at this early date, that such conflicts are part of life in any distributed database, and RavenDB contains several ways to handle them (this is discussed in Chapter 6 in more detail).
Another wrinkle that we need to consider is that we really want to be able to generate document IDs on the client, since that allows us to write code that creates a new document and uses its ID immediately, in the same transaction. Otherwise, we'll need to call to the server to get the ID, then make use of this ID in a separate transaction.
RavenDB handles this by using an algorithm called hilo. The concept is pretty simple. The first time you need to
generate an identifier, you reserve a range of identifiers from the server. The server is responsible for ensuring it
will only provide that range to a single client. Multiple clients can ask for ranges at the same time, and they will receive
different ranges. Each client can then safely generate identifiers within the range it was given, without requiring any further
coordination between client and server.
This is extremely efficient, and it scales nicely. RavenDB uses a dynamic range allocation scheme, in which the ranges provided to the client can expand if the client is very busy and generates a lot of identifiers very quickly (thus consuming the entire range quickly).
This is the default approach in RavenDB and the one we've used so far in this book. There's still another wrinkle to deal with, though. What happens if two clients request ID ranges from two different nodes at the same time? At this point, each node is operating independently (indeed, a network failure might mean that we aren't able to talk to other nodes). In order to handle this scenario properly, each range is also stamped with the ID of the node that assigned that range. This way, even if those two clients have managed to get the same range from each node, the generated IDs will be unique.
Let's assume the first client got the range 128 - 256 from node A and the second client got the same range from node
B. The hilo method on the first client will generate document IDs like people/128-A, people/129-A, and on the second
client, it will generate people/128-B, people/129-B, etc. These are different documents. Using shorthand to refer to
documents using just the numeric portion of the ID is common, but pay attention to the full ID as well.
It's important to note that this scenario rarely occurs. Typically, the nodes can talk to one another and share information about the provided ID ranges. Even if they can't, all clients will typically try to use the same server for getting the ranges, so you need multiple concurrent failures to cause this. If it does happen, RavenDB will handle it smoothly, and the only impact is that you'll have a few documents with similar IDs. A minor consideration indeed.
Server-side identifier generation
Hilo is quite nice, as it generates human-readable and predictable identifiers. However, it requires both client and
server to cooperate to get to the end result. This is not an issue if you're using any of the client APIs, but if
you're writing documents directly (using the RavenDB Studio, for example) or don't care to assign the IDs yourself, there
are additional options.
You can ask RavenDB to assign a document ID to a new document when it is saved. You do that by providing a document ID that
ends with the slash (/). Go into the RavenDB Studio and create a new document. Enter in the ID the value tryouts/
and then click on the Save button. The generated document ID should look something like Figure 2.13.
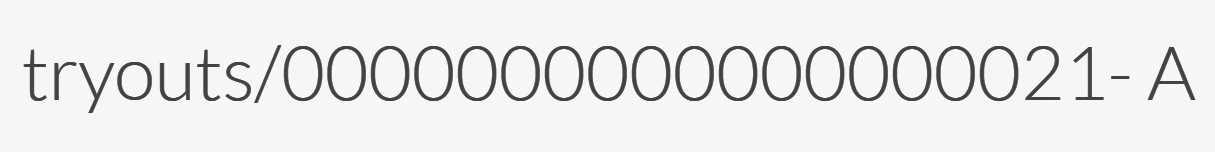
When you save a document whose ID ends with a slash, RavenDB will generate the ID for you by appending a numeric value (the only guarantee you have about this value is that it's always increasing) and the node ID.
Don't generate similar IDs manually
Due to the way we implement server-side identifier generation, we can be sure that RavenDB will never generate an ID that was previously generated. That allows us to skip some checks in the save process (avoid a B+Tree lookup). Since server-side generation is typically used for large batch jobs, this can have a significant impact on performance.
What this means is that if you manually generate a document ID with a pattern that matches the server-side generated IDs, RavenDB will not check for that and may overwrite the existing document. That's partly why we're putting all those zeros in the ID — to make sure that we aren't conflicting with any existing document by accident.
This kind of ID plays quite nicely with how RavenDB actually stores the information on disk, which is convenient. We'll give this topic a bit more time further down in the chapter. This is the recommended method if you just need to generate a large number of documents, such as in bulk insert scenarios, since it will generate the least amount of work for RavenDB.
Identity generation strategy
All the ID generation strategies we've outlined so far have one problem: they don't give you any promises with regards to the end result. What they do give you is an ID you can be sure will be unique, but that's all. In the vast majority of cases, this is all you need. But sometimes you need a bit more.
If you really need to have consecutive IDs, you can use the identity option. Identity, just like in a relational database
(also called sequence), is a simple always-incrementing value. Unlike the hilo option, you always have to go to the server
to generate such a value.
Generating identities is very similar to generating server-side IDs. But instead of using the slash (/) at the end of
the document, you use a pipe symbol (|). In the Studio, try to save a document with the document ID tryouts|.
The pipe character will be replaced by a slash (/) and a document with the ID tryouts/1 will be created.
Doing so again will generate tryouts/2, and so on.
Invoices and other tax annoyances
For the most part, unless you're using semantic IDs (covered earlier in this chapter), you shouldn't care what your document ID is. The one case you care about is when you have an outside requirement to generate absolute consecutive IDs. One such common case is when you need to generate invoices.
Most tax authorities have rules about not missing invoice numbers, to make it just a tad easier to audit your system. But an invoice document's identifier and the invoice number are two very different things.
It's entirely possible to have the document ID of
invoices/843-Cfor invoice number523. And using an identity doesn't protect you from skipping values because documents have been deleted or a failed transaction consumed the identity and now there's a hole in the sequence.
For people coming from a relational database background, the identity option usually seems to be the best one, since it's what
they're most familiar with. But updating an identity happens in a separate transaction from the current one.
In other words, if we try to save a document with the ID invoices| and the transaction fails, the identity value is still
incremented. So even though identity generated consecutive numbers, it might still skip identifiers if a transaction has been
rolled back.
Except for very specific requirements, such as a legal obligation to generate consecutive numbers, I would strongly recommend not using identity. Note my wording here. A legal obligation doesn't arise because someone wants consecutive IDs since they are easier to grasp. Identity has a real cost associated with it.
The biggest problem with identities is that generating them in a distributed database requires us to do a lot more work than one might think. In order to prevent races, such as two clients generating the same identity on two different servers, part of the process of generating a new identity requires the nodes to coordinate with one another.9
That means we need to go over the network and talk to the other members in the cluster to guarantee we have the next value of the identity. That can increase the cost of saving a new document with identity. What's worse is that, under failure scenarios, we might not be able to communicate with a sufficient number of nodes in our cluster. This means we'll also be unable to generate the requested identity.
Because we guarantee that identities are always consecutive across the cluster, if there's a failure scenario that prevents us from talking to a majority of the nodes, we'll not be able to generate the identity at all, and we'll fail to save the new document. All the other ID generation methods can work without issue when we're disconnected from the cluster, so unless you truly need consecutive IDs, use one of the other options.
Performance implications of document identifiers
We've gone over a lot of options for generating document identifiers, and each of them have their own behaviors and costs. There are also performance differences among the various methods that I want to talk about.
Premature optimization warning
This section is included because it's important at scale, but for most users, there's no need to consider it at all. RavenDB is going to accept whatever document IDs you throw at it, and it's going to be very fast when doing so. My strong recommendation is that you use whatever document ID generation that best matches your needs, and only consider the performance impact if you notice an observable difference — or have crossed the hundreds of millions of documents per database mark.
RavenDB keeps track of the document IDs by storing them inside a B+Tree. If the document IDs are very big, it will mean that RavenDB can pack less of them in a given space.10
The hilo algorithm generates document IDs that are lexically sortable, up to a degree (people/2-A is sorted after
people/100-A). But with the exception of when we add a digit to the number11, values
are nicely sorted. This means that for the most part we get nice trees and very efficient searches. It also generates the
most human-readable values.
The server-side method using the slash (/) generates the best values in terms of suitability for storage. They're a
bit bigger than the comparable hilo values, but they make up for it by being always lexically sorted and predictable as
far as the underlying storage is concerned. This method is well suited for large batch jobs and contains a number of additional
optimizations in its codepath. (We can be sure this is a new value, so we can skip a B+Tree lookup, which matters if you are
doing that a lot.)
Semantic IDs (people/oscar@arava.example or accounts/591-192/txs/2017-05-17) tend to be unsorted, and sometimes that can
cause people to want to avoid them. But this is rarely a good reason to do so. RavenDB can easily handle a large
number of documents with semantic identifiers without any issue.
Running the numbers
If you're familiar with database terminology, then you're familiar with terms like B+Tree and page splits. In the case of RavenDB, we're storing document IDs separately from the actual document data, and we're making sure to coalesce the pages holding the document keys so we have a good locality of reference.
Even with a database that holds a hundred million documents, the whole of the document ID data is likely to be memory resident, which makes the cost of finding a particular document extremely cheap.
The one option you need to be cautious of is the identity generation method. Be careful not to use it without careful consideration and analysis. Identity requires network round trips to generate the next value, and it will become unavailable if the node cannot communicate with a majority of the nodes the cluster.
Document metadata
Document data is composed of whatever it is that you're storing in the document. For the order document, that would be the shipping details, the order lines, who the customer is, the order priority, etc. You also need a place to store additional information that's unrelated to the document itself but is rather about the document. This is where metadata comes into play.
The metadata is also in JSON format, just like the document data itself. RavenDB reserves for its own use metadata property names that
start with @ , but you're free to use anything else. By convention, users' custom metadata properties
use Pascal-Case capitalization. In other words, we separate words with a dash, and the first letter of each word is
capitalized while everything else is in lower case. RavenDB's internal metadata properties use the @ prefix, all lower cased,
with words separated by a dash (e.g., @last-modified).
RavenDB uses the metadata to store several pieces of information about the document that it keeps track of:
- The collection name — stored in the
@collectionmetadata property and determines where RavenDB will store the document. If the collection isn't set, the document will be placed in the@emptycollection. The client API will automatically assign an entity to a collection based on its type. (You can control exactly how using the conventions.) - The last modified date — stored in the
@last-modifiedmetadata property in UTC format. - The client-side type — This is a client-side metadata property. So for .NET, it will be named
Raven-Clr-Type; for a Java client, it will beRaven-Java-Class; for Python,Raven-Python-Typeand...you get the point. This is used solely by the clients to deserialize the entity into the right client-side type.
You can use the metadata to store your own values. For example, Last-Modified-By is a common metadata property that's
added when you want to track who changed a document. From the client side, you can access the document metadata using the
code in Listing 2.20.
Listing 2.20 Modifying the metadata of a document
using (var session = store.OpenSession())
{
var task = session.Load<ToDoTask>("ToDoTasks/1-A");
var metadata = session.Advanced.GetMetadataFor(task);
metadata["Last-Modified-By"] = person.Name;
session.SaveChanges();
}
Note that there will be no extra call to the database to fetch the metadata. Whenever you load the document, the metadata is fetched as well. That metadata is embedded inside the document and is an integral part of it.
Changing a document collection
RavenDB does not support changing collections, and trying to do so will raise an error. You can delete a document and then create a new document with the same ID in a different collection, but that tends to be confusing, so it's best to be avoided if you can.
Once you have the metadata, you can modify it as you wish, as seen in Listing 2.20. The session tracks changes to
both the document and its metadata, and changes to either one of those will cause the document to be updated on the server
once SaveChanges has been called.
Modifying the metadata in this fashion is possible, but it's pretty rare to do so explicitly in your code. Instead, you'll usually use event handlers (covered in Chapter 4) to do this sort of work.
Distributed compare-exchange operations with RavenDB
RavenDB is meant to be run in a cluster. You can run it in single-node mode, but the most common (and recommended) deployment option is with a cluster. You already saw some of the impact this has had on the design of RavenDB. Auto-generated document IDs contain the node ID that generated them to avoid conflicts between concurrent work on different nodes in the cluster.
One of the challenges of any distributed system is how to handle coordination across all the nodes in the cluster. RavenDB uses several strategies for this, discussed in Part II of this book. At this point, I want to introduce one of the tools RavenDB provides specifically in order to allow users to manage the distributed state correctly.
If you've worked with multi-threaded applications, you are familiar with many of the same challenges. Different threads can be doing different things at the same time. They may be acting on stale information or modifying the shared state. Typically, such systems use locks to coordinate the work between threads. That leads to a whole separate issue of lock contention, deadlock prevention, etc. With distributed systems, you have all the usual problems of multiple threads with the added complication that you may be operating in a partial failure state. Some of the nodes may not be able to talk to other nodes (but can still talk to some).
RavenDB offers a simple primitive to handle such a scenario: the compare-exchange feature. A very common primitive
with multi-thread solutions is the atomic compare-and-swap operation. From code, this will be
Interlocked.CompareExchange when using C#. Because this operation is so useful, it's supported at the hardware level with
the CMPXCHG assembly instruction. In a similar way, RavenDB offers a distributed compare-exchange feature.
Let's take a look at Listing 2.21, for a small sample of what this looks like in code.
Listing 2.21 Using compare exchange to validate unique username in a distributed system
var cmd = new PutCompareExchangeValueOperation<string>(
key: "names/john",
value: "users/1-A",
index: 0);
var result = await store.Operations.SendAsync(cmd);
if (result.Successful)
{
// users/1-A now owns the username 'john'
}
The code in Listing 2.21 uses PutCompareExchangeValueOperation to submit a compare-exchange operation to the cluster
at large. This operation compares the existing index for names/john with the expected index (in this case, 0, meaning
we want to create a new value).
If successful, the cluster will store the value users/1-A for the key names/john. However, if there is already a value
for the key and the index does not match, the operation will fail. You'll get the existing index and the current value
and can decide how to handle things from that point (show an error to the user, try writing again with the new index, etc.).
The most important aspect of this feature is the fact that this is a cluster-wide, distributed operation. It is guaranteed to behave properly even if you have concurrent requests going to separate nodes. This feature is a low-level one; it is meant to be built upon by the user to provide more sophisticated features. For example, in Listing 2.21, we ensure a unique username for each user using a method that is resilient to failures, network partitions, etc.
You can see how this is exposed in the Studio in Figure 2.14.
We'll talk more about compare-exchange values in Chapter 6. For now, it's good to remember that they're there and can help
you make distributed decisions in a reliable manner. A compare-exchange value isn't limited to just a string. You can also
use a complex object, a counter, etc. However, remember that these are not documents. You can read the current value of
compare-exchange value using the code in Listing 2.22. Aside from checking the current value of the key, you get the
current index, which you can then use in the next call to PutCompareExchangeValueOperation.
Listing 2.22 Reading an existing compare exchange value by name
var cmd = new GetCompareExchangeValueOperation<string>("names/john");
var result = await store.Operations.SendAsync(cmd);
Aside from getting the value by key, there is no other way to query for the compare-exchange values. Usually you already know what the compare-exchange key will be (as in the case of creating a new username and checking the name isn't already taken). Alternatively, you can store the compare-exchange key in a document that you'll query and then use the key from the document to make the compare-exchange operation.
If you know the name of the compare-exchange value, you can use it directly in your queries, as shown in Listing 2.23.
Listing 2.23 Querying for documents using cmpxchg() values
from Users
where id() == cmpxchg('names/john')
The query in Listing 2.23 will find a document whose ID is located in the names/john compare-exchange value. We'll discuss
this feature again in Chapter 6. This feature relies on some of the low-level details of RavenDB distributed flow, and it
will make more sense once we have gone over that.
Testing with RavenDB
This chapter is quite long, but I can't complete the basics without discussing testing. When you build an application, it's important to be able to verify that your code works. That has become an accepted reality, and an application using RavenDB is no exception.
In order to aid in testing, RavenDB provides the Raven.TestDriver NuGet package. Using the test driver, you can get an
instance of an IDocumentStore that talks to an in-memory database. Your tests will be very fast, they won't require you to do complex
state setup before you start and they will be isolated from one another.
Listing 2.24 shows the code for a simple test that saves and loads data from RavenDB.
Listing 2.24 Basic CRUD test using RavenDB Test Driver
public class BasicCrud : RavenTestDriver<RavenExecLocator>
{
public class Play
{
public string Id { get; set; }
public string Name { get; set; }
public string Author { get; set; }
}
[Fact]
public void CanSaveAndLoad()
{
using (var store = GetDocumentStore())
{
string id;
using (var session = store.OpenSession())
{
var play = new Play
{
Author = "Shakespeare",
Name = "As You Like It"
};
session.Store(play);
id = play.Id;
session.SaveChanges();
}
using (var session = store.OpenSession())
{
var play = session.Load<Play>(id);
Assert.Equal("Shakespeare", play.Author);
Assert.Equal("As You Like It", play.Name);
}
}
}
}
There are two interesting things happening in the code in Listing 2.24. The code inherits from the RavenTestDriver<RavenExecLocator>
class, and it uses the GetDocumentStore method to get an instance of the document store. Let's break apart what's going on.
The RavenTestDriver<T> class is the base test driver, which is responsible for setting up and tearing down databases. All
your RavenDB tests will use this class as a base class.12
Most importantly, from your point of view, is that the RavenTestDriver<T> class provides the GetDocumentStore method, which
generates a new in-memory database and is responsible for tearing it down at the end of the test. Each call to the
GetDocumentStore method will generate a new database. It will run purely in memory, but other then that, it's fully functional and
behaves in the same manner as a typical RavenDB server.
If you've been paying attention, you might have noticed the difference between RavenTestDriver<RavenExecLocator> and
RavenTestDriver<T>. What's that about? The RavenTestDriver<T> uses its generic argument to find the Raven.Server.exe
executable. Listing 2.25 shows the implementation of RavenExecLocator.
Listing 2.25 Letting the RavenTestDriver know where the Raven.Server exec is located
public class RavenExecLocator : RavenTestDriver.Locator
{
public override string ExecutablePath =>
@"d:\RavenDB\Raven.Server.exe";
}
The code in Listing 2.24 is using xunit for testing, but there's no dependency on the testing framework from
Raven.TestDriver. You can use whatever testing framework you prefer.
How does Raven.TestDriver work?
In order to provide fast tests and reduce environment noise, the test driver runs a single instance of the RavenDB server using an in-memory-only node binding to
localhostand a dynamic port. Each call to theGetDocumentStoremethod will then create a new database on that single-server instance.When the test is closed, we'll delete the database, and when the test suite is over, the server instance will be closed. This provides you with a test setup that's both very fast and that runs the exact same code as you will run in production.
Debugging tests
Sometimes a test fails and you need to figure out what happened. This is easy if you're dealing with in-memory state only,
but it can be harder if your state resides elsewhere. The RavenDB test driver provides the WaitForUserToContinueTheTest
method to make that scenario easier. Calling this method will pause the current test and open the RavenDB Studio, allowing you
to inspect, validate and modify the content of the in-memory database (while the test is still running). After
you've looked at the database state, you can resume the test and continue execution.
This makes it much easier to figure out what's going on because you can just look. Let's test this out. Add the following line between the two sessions in the code in Listing 2.24 and then run the test:
WaitForUserToContinueTheTest(store);
When the test reaches this line, a magical thing will happen, as shown in Figure 2.15. The Studio will open, and you'll be able to see and interact with everything that's going on inside RavenDB. One nice feature I like for complex cases is the ability to just export the entire database to a file, which lets me import it into another system later on for further analysis.
At this time, the rest of the test is suspended, waiting for you to confirm you're done peeking inside. You can do that by clicking the button shown in Figure 2.16, after which your test will resume normally and (hopefully) turn green.

The test driver can do quite a bit more (configure the database to your specifications, create relevant indexes, load initial data, etc.). You can read all about its features in the online documentation.
Summary
At this point in the book, we've accomplished quite a lot. We started by setting up a development instance of RavenDB on your machine.13 And we learned how to set up a new database and played a bit with the provided sample database.
We then moved to the most common tasks you'll do with RavenDB:
- Creating/editing/deleting documents via the Studio.
- Querying for documents in the Studio.
The idea was to get you familiar with the basics of working with the Studio so you can see the results of your actions and learn to navigate the Studio well enough that it's useful. We'll talk more about working with the Studio throughout the rest of the book, but remember that the details are covered extensively in the online documentation and are unlikely to need additional verbiage.
Things got more interesting when we started working with the RavenDB API and wrote our first document via code. We looked at the very basics of defining entities to work with RavenDB (the next chapter will cover this exact topic in depth). We learned about creating and querying documents and were able to remind ourselves to buy some milk using RavenDB.
We dove deeper and discussed the architecture of the RavenDB client, as well as the use of Document Store and Document Session to
access the cluster and a specific database, respectively. As a reminder, the document store is the single access point to a
particular RavenDB cluster, and it allows you to globally configure a wide range of behaviors by changing the default conventions.
The session is a single Unit of Work that represents a single business transaction against a particular database and is the
most commonly used API to talk to RavenDB. It was designed explicitly to make it easy to handle 90% of pure CRUD scenarios,
and more complex scenarios are possible by accessing the session.Advanced functionality.
From the client API, we moved to discussing how RavenDB deals with the crucial task of properly generating document identifiers. We looked at a few of RavenDB's identifier generation strategies and how they work in a distributed cluster:
- The hilo algorithm: generates the identifier on the client by collaborating with the server to reserve identifier ranges that can be exclusively generated by a particular client.
- Server-side: generates the identifier on the server side, optimized for very large tasks. It allows each server to generate human-readable, unique identifiers independently of each other.
- Identity: generates a consecutive numeric value using a consensus of the entire cluster. Typically the slowest method to use and only useful if you really need to generate consecutive IDs for some reason.
You can also generate the document ID yourself, which we typically call a semantic ID. Semantic IDs are identifiers that have meaning: maybe it's an external ID brought over from another system, or maybe it's a naming convention that implies the content of the document.
We briefly discussed document metadata and how it allows you to store out-of-band information about the document (auditing details, workflow steps, etc.) without impacting the document's structure. You can modify such metadata seamlessly on the client side (and access it on the server). RavenDB makes use of metadata to hold critical information such as the document collection, when it was last modified, etc.
Last but certainly not least, we discussed testing your applications and how the RavenDB test driver allows you to easily set up in-memory instances that will let you run your code against them. The test driver even allows you to stop a test midway through and inspect the running RavenDB instance using the Studio.
In this chapter, we started building the foundation of your RavenDB knowledge. In the next one, we'll build even further on that foundation. We'll discuss modeling data and documents inside RavenDB and how to best structure your system to take advantage of what RavenDB has to offer.
-
Actually, that's not exactly the case, but the details on the state of a newly minted node are a bit complex and covered in more detail in Chapter 6.↩
-
I'll leave aside Id vs. ID, since it's handled in the same manner.↩
-
See Release It!, a wonderful book that heavily influenced the RavenDB design.↩
-
You can call
session.Advanced.Refreshif you want to force the session to update the state of the document from the server.↩ -
The 1% case where it will help is the realm of demo apps with little to no functionality.↩
-
Unit of Workwon't work. Neither will change tracking, optimistic concurrency you'll have to deal with manually, etc.↩ -
Although, when you think about it, there's a huge untapped market of teenage developers...↩
-
If the user explicitly specified the document ID, there's nothing that RavenDB can do here. But for IDs that are being generated by RavenDB (client or server), we can do better than just hope that we'll have no collisions.↩
-
This is done using the Raft consensus protocol, which covered in Chapter 6.↩
-
RavenDB is using B+Tree for on disk storage, and uses pages of 8KB in size. Bigger document IDs means that we can fit less entries in each page, and need to traverse down the tree, requiring us to do a bit more work to find the right document. The same is true for saving unsorted document IDs, which can cause page splits and increase the depth of the tree. In nearly all cases, that doesn't really matter.↩
-
Rolling from
99to100or from999to1000.↩ -
Not strictly necessary, but this is the easiest way to build tests.↩
-
The steps outlined in this chapter are meant to be quick and hassle-free, rather than an examination of proper production deployments. Check Chapter 15 for details on those.↩
