 Skip to Navigation
Skip to Navigation
Backups and restores
Backups are important. I don't really think I need to tell you just how important. Still, it's worth discussing why we have backups. There are two reasons to have backups:
- Restoring the database after losing data.
- Recovering data from an earlier point in time.
Let's consider each reason independently. Restoration after data loss can be necessary because an operator accidentally deleted the wrong database, because the hard disk or the entire server died, etc. I intentionally picked these two examples because they represent very different scenarios. In the latter case — a hardware failure resulting in the loss of a node — the other members in the cluster will just pick up the slack. You can set up a new node or recover the old one and let the cluster fill in any missing details automatically.1
The case of accidental deletion of the database is more worrying. In this case, the database has been erased from all the nodes in the cluster. At this point, you can be saved by an offsite replica: a database to which you had set up external replication. Because that database isn't part of the same database group, it will not be impacted by the deletion, and you can manually fail over to it while you replicate the data back to the original cluster.
Restoring databases can take time
The potential that you could delete a database or lose a whole cluster is the perfect reason to have a backup. Why wouldn't we just restore from backup at this point? The answer is simple: time.
Imagine that we have a decent-sized database, 250GB in size. Just copying the raw data from the backup destination to the machine on which we want to restore can take a long time. Let's assume that we have a Provisioned IOPS SSD on Amazon Web Services (a high speed hard disk recommended for demanding database loads). Ignoring any transport/decompression costs, it will take about 10 minutes just to copy the backup to the local disk and another 10 minutes (with just I/O costs, ignoring everything else) for the actual restore.
That gives us a minimum of 20 minutes for the restore, assuming we are using a high end disk and are only limited by the speed of the disk itself. But the actual restore time will be higher. Plus, the I/O costs aren't the only costs to consider. Most of the cost of restoring a database is actually spent on getting the data to the machine. Backups are often optimized for long-term storage, and speed of access is not prioritized (such as with tape storage, for example).
So if you're interested in minimizing downtime in such scenarios, you would need access to a separate offsite replica (which we discussed at length in the previous chapter). There is a balance between how much protection you want and how much you are willing to pay for. If your threat scenario does not include an admin deleting a database by mistake or losing the entire cluster in one go, you probably don't need an offsite replica. Alternatively, you may decide that if those issues do come up, the time it will take to restore from backup is acceptable.
It's more common to restore a database to a particular point of time than to restore after data loss. You might want to restore from backup on an independent machine, to try to troubleshoot a particular problem, or to see what was in the database at a given time. In many cases, there are regulatory requirements dictating that backups should be kept for a certain period of time (often a minimum of seven years).
In short, backups are important. But I said that already. This is why I'm dedicating a full chapter to this topic, and why RavenDB has a whole suite of features around scheduling, managing and monitoring backups. We'll start by going over how backups work in RavenDB to make sure that you understand what your options are and the implications of the choices you make. Only after that will we start setting up backups and performing restores.
How backups work in RavenDB
Backups are often stored for long periods of time (years) and as such, their size matters quite a lot. The standard backup option for RavenDB is a gzipped JSON dump of all the documents and other data (such as attachments) inside the database. This backup option gives you the smallest possible size for your data and makes it easier and cheaper to store the backup files. On the other hand, when you need to restore, RavenDB will need to reinsert and re-index all the data. This can increase the time that it takes to restore the database.
Avoid backing up at the level of files on disk
It can be tempting to try to back up the database at the file system level. Just copy the directory to the side and store it somewhere. While this seems easy, it is not supported and is likely to cause failures down the line. RavenDB has an involved set of interactions with the file system with a carefully choreographed set of calls to ensure ACID compliance.
Copying the directory to the side will usually not capture the data at a point in time and is likely to cause issues, while the RavenDB backup handles such a scenario and ensures that there is a point in time freeze of the database. In the same manner, you should avoid using full disk snapshots for backups. Depending on exactly what technology and manner of disk snapshotting you use, it may or may not work.
In short, you should be using RavenDB's own backup system, not relying on the file system for that.
An alternative to the backup option is the snapshot. A snapshot is a binary copy of the database and journals at a given point in time. Like the regular backup, snapshots are compressed. But aside from that, they're pretty much ready to go as far as the database is concerned. The restoration process of a snapshot involves extracting the data and journal files from the archive and starting the database normally.
The advantage here is that it's much faster to restore the database using a snapshot. But a snapshot is also typically much larger than a regular backup. In most cases, you'll have both a regular backup defined for long-term storage (where the restore speed doesn't matter) and a snapshot backup written to immediately accessible storage (such as local SAN) for quick restores.
Both backups and snapshots save full clones of the database from specific points in time. However, there are many cases where you don't want to have a full backup everytime. You might just want just the changes that have happened since the last backup. This is called an incremental backup and is available for both backups and snapshots.
An incremental backup is defined as the set of changes that have happened since the last backup/snapshot. Regardless of the backup mode you choose, an incremental backup will always use gzipped JSON (since RavenDB doesn't do incremental snapshots). The reason for this is that applying incremental backups to a snapshot is typically very quick and won't significantly increase the time needed to restore the database, while incremental snapshots can be very big. One of the primary reasons incremental backups exist in the first place is to reduce the cost of taking backups, after all. Figure 17.1 shows the interplay between snapshots, full backups and incremental backups from a real production database (my blog).
blog.ayende.com database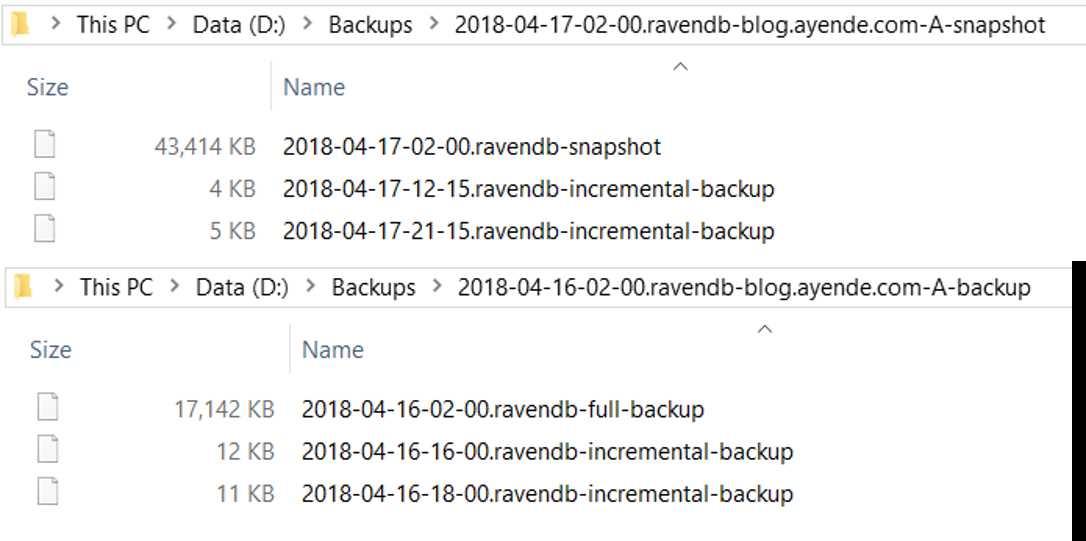
In Figure 17.1, you can see a snapshot taken April 17 at 2 a.m. on node A as well as two incremental backups after that. The
second folder shows a full backup on April 16 at 2 a.m. and two incremental backups after that. In both cases, the database
is blog.ayende.com, which powers my personal blog. The database size on disk is 790MB, so you can see that even for
snapshots, we have quite a big space saved. And keep in mind, this is a pretty small database. Figure 17.2 shows the same
snapshot/backup division for a database that is about 14GB in size.
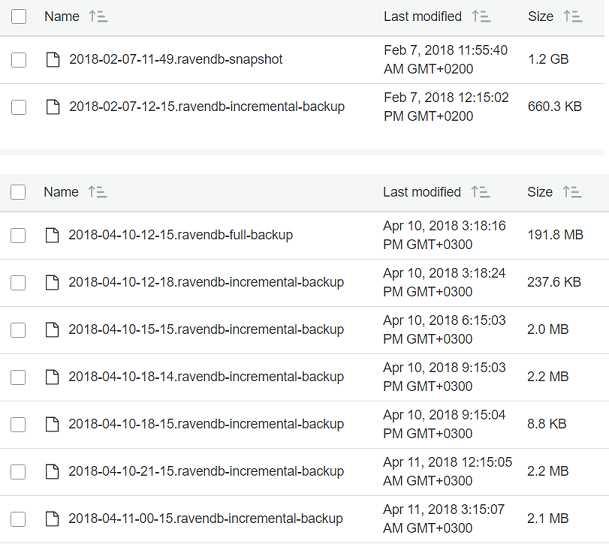
The reason why snapshots are so much smaller than the raw data is that the backup is compressed, even for snapshots. The cost of decompressing the backup is far overshadowed by the cost of I/O at such sizes. However, encrypted databases typically cannot be compressed, so you need to be prepared for snapshots that are the same size as the database (very big).
In Figure 17.1, you can see that there are only a couple of incremental backups; in Figure 17.2, we have a lot more. This is because while both backups were defined with roughly the same incremental backup duration, they represent very different databases. The blog database is seeing infrequent writes; when the incremental backup runs and sees that there have been no changes since the last time, there's nothing for it to do, so it skips out on its backup run. On the other hand, whenever a full backup gets run, it produces a full copy of the entire database even if no changes have been recently made.
In Figure 17.2, we are backing up a database that is under relatively constant write load. This means that we'll get an incremental backup on every run, although you can see that there are significant differences between the sizes of these incremental backups.
Incremental backups record the current state
An important consideration for the size of an incremental backup is the fact that the number of writes doesn't matter as much as the number of documents that have been written to. In other words, if a single document was modified a thousand times, when the incremental backup runs, the latest version of the document will be written to the backup. If a thousand different documents were written, we'll need to write all of them to the backup. That kind of difference in behavior can produce significant size changes between incremental backups.
Backups record the current state of documents, but if you want to get all the changes that have been made in between, you need to use revisions. Just like documents, revisions are included in backups. This means that even if you store revisions inside your database for only a short period of time, you can still restore a document to any point in time by finding relevant revision from the historical backups.
What is in the backup?
A backup (or a snapshot) contains everything that is needed to restore the database to full functionality. Table 17.1 shows all the gory details about what exactly is being backed up. This requires us to understand a bit more about where RavenDB stores different information about a database.
| Database | Cluster |
|---|---|
| Documents | Database Record (including tasks) |
| Attachments | Compare-exchange values |
| Revisions | Identities |
| Tombstones | Indexes |
| Conflicts | Tasks state (snapshot only) |
Table: What is backed up for a database and at what level.
We already discussed the differences between database groups and the cluster (see Chapter 7). At the database level, we manage documents and any node in the database group can accept writes. At the cluster level, we use a consensus algorithm to ensure consistency of the cluster-level operations. Such operations include identities, creating indexes, etc. These details are stored at the cluster level and are managed by the cluster as a whole, instead of independently on each node.
Incremental backup of the cluster-level state
At the cluster level, RavenDB backs up the entire cluster-level state of a database (on both full and incremental backups). If you have a lot of identities (very rare) or many compare-exchange values (more common), you might want to take that into account when defining the backup frequency.
Identities and compare-exchange values can be very important for certain type of usages, and they are stored outside of the database itself. When we back up a database, the cluster-level values are also backed up. The database tasks are another important factor to consider: backup definitions and schedules, ETL tasks, subscriptions, etc.
Important considerations
When a database is restored, the tasks that were defined to it are also restored. In other words, if you have an ETL task defined for a production database and you restore the backup on a development machine, you need to disable the task. Otherwise, assuming your development server can reach the ETL targets, your database might start running this task and writing to places you don't want it to write to.
The same applies to external replication, backups and any other tasks that were defined for the database. The restore includes all these tasks. That's what you want when restoring a node after failure, but it's something to note if you're restoring a backup on the side. During restoration, you have the option of disabling all such tasks so you can restore the database cleanly. But you'll have to manually select which tasks to re-enable. You should set that option when you're not restoring the backup to the same environment (or purpose) as before.
If you're using encrypted databases, you need to be aware that a snapshot backup keeps the actual data encrypted, but all the cluster-level data are stored in plain text (even if the server store itself is encrypted). And regular backups are always in plain text. As part of your backup strategy, you need to consider the security of the backups themselves. You can read more about backups and encrypted databases in Chapter 14.
Backing up the cluster itself
We've talked about backing up databases, but what about backing the cluster as a whole? In general, the cluster is mostly concerned with managing databases; there isn't a persistent state beyond the database data that needs backing up. If you look at Table 17.1, you'll see that all the details therein – whether they are stored at the cluster level or the database level – are for a particular database.
The only details at the cluster level that aren't directly related to a database are details about the cluster itself (nodes, topology, task assignments, history of health checks, etc). All of that data isn't going to be meaningful if you lost the entire cluster, so there is no real point to preserve it.
Backups in RavenDB are always done at the database level. Recreating the cluster from scratch takes very little time, after all. Once completed, you can restore the individual databases on the new cluster.
Who is doing the backup?
A database in RavenDB is usually hosted on multiple nodes in the cluster. When it comes to backups, we need to ask a very important question: who is actually going to run the backups? Individual database instances in a database group are independent of each other but hold the same data. We don't want to have each of the nodes in a database group create its own backup. We would wind up duplicating our backups and wasting a lot of resources.
A backup task, just like ETL tasks or subscriptions, is a task that is set for the entire database group. The cluster decides which node in the database group is the owner of this task and that node will be the one in charge of running backups. The cluster knows to pick an up-to-date node and will move responsibility for backups to another node if the owner node has failed.
For full backups, which node is selected doesn't matter. Any node will perform the backup from its current state as usual. If the cluster decides that a different node will execute the backup, that node's backup will be clearly marked and timestamped. From an operational perspective, there is no difference between the nodes in this regard.
For incremental backups, the situation is a bit different. You can only apply an incremental backup on top of a full backup from the same node that took the full backup. When the cluster decides that incremental backup ownership should switch because the owner node is down, the new node will not run an incremental backup. Instead, it will create a full backup first, and only when that is complete will it start creating incremental backups.
Backups from different nodes to the same location
RavenDB encodes the node ID in the backup folder name. This way, even if you have a backup triggered from multiple nodes at the same time, you'll be able to tell which node is responsible for which backup. This scenario can happen if there is a split in the network when the owner node of the backup is still functional but is unable to communicate with the cluster.
At this point, the cluster will assign another node as the owner for the backup (since the original node is missing in action, as far as the cluster is concerned). But since the original node can't communicate with the cluster, it won't be notified of the ownership change. This can cause both the original owner and the new owner to run the backup. This behavior is in place because backups are important; it's better to have extra backups than to go without.
Consider the case of a three-node cluster and a database that is configured to take a full backup every midnight and an incremental backup every four hours. Node C is the node that is usually assigned to do the backups, and indeed at midnight, it takes a full backup. It also dutifully creates incremental backups at 4 a.m. and 8 a.m. However, at noon, node C goes down and the cluster moves responsibility for the backups to node A.
Node A cannot create an incremental backup on top of node C's full backup, so node A starts its own full backup. If node C is still down at 4 p.m., node A will still own the backup task and will create an incremental backup of all changes that took place since noon. When node C comes back up at 6 p.m., the cluster transfers backup ownership back to it. At 8 p.m., node C creates an incremental backup of everything that happened since 8 a.m., the last time node C performed an incremental backup.
There are a few interesting behaviors that you might want to pay attention to with this example:
- The cluster ensures that the minimum backup definition is always respected. In other words, every four hours we have an incremental backup of the database's state.
- Only nodes that are up to date are considered appropriate candidates for backup ownership. Since node C was down for so long, the cluster considered it out of date. The cluster only transferred ownership of the backup task (as well as any other tasks) back to node C when node C had finally caught up with any changes that happened while it was down.
- The backup schedule is shared among all members of the cluster. In other words, the fact that one node fails doesns't automatically trigger a backup in another node. Only after the appropriate time has passed since the last successful backup will the cluster trigger a backup on a substitute node.
- Incremental backups apply from the last backup (incremental or full) on that particular node. This means that you can use a single-node backup to fully restore the database state.
- When the cluster moves the ownership of a backup from node to node, the new owner will first run a full backup even if only an incremental backup was scheduled to run. This is a good rule of thumb to remember, but in practice it's actually a bit more complex. When a new node is assigned the backup task, it will check to see if it has done a full backup on schedule. If it is not yet time to run a new full backup, it will only run an incremental backup (from the last full backup this node did).
The last two points are important for a simple reason: even though you may schedule your full backup to happen during off hours, a change in ownership could result in a full backup running when you only expect an incremental backup. This can be an issue because the cost of a full backup can be high in terms of disk I/O, CPU, etc. If you are running a full backup when you're are under high load — especially if you've already lost at least one node — this can put additional pressure on the server.
To handle this issue, RavenDB controls the amount of resources a backup can take. The I/O and CPU priority for the backup task is equal to the normal request processing priority, which is higher than the usual indexing priority. This will likely only be an issue if your system is teetering on resource exhaustion as it is.
Now that we know how backups behave in RavenDB, let's go ahead and see how to configure backups in RavenDB.
Setting up backups
Backups in RavenDB are set up using the Studio by going to Settings,
Manage Ongoing Tasks, clicking on Add Task and selecting Backup.2 You can see what the backup screen looks like in Figure 17.3.
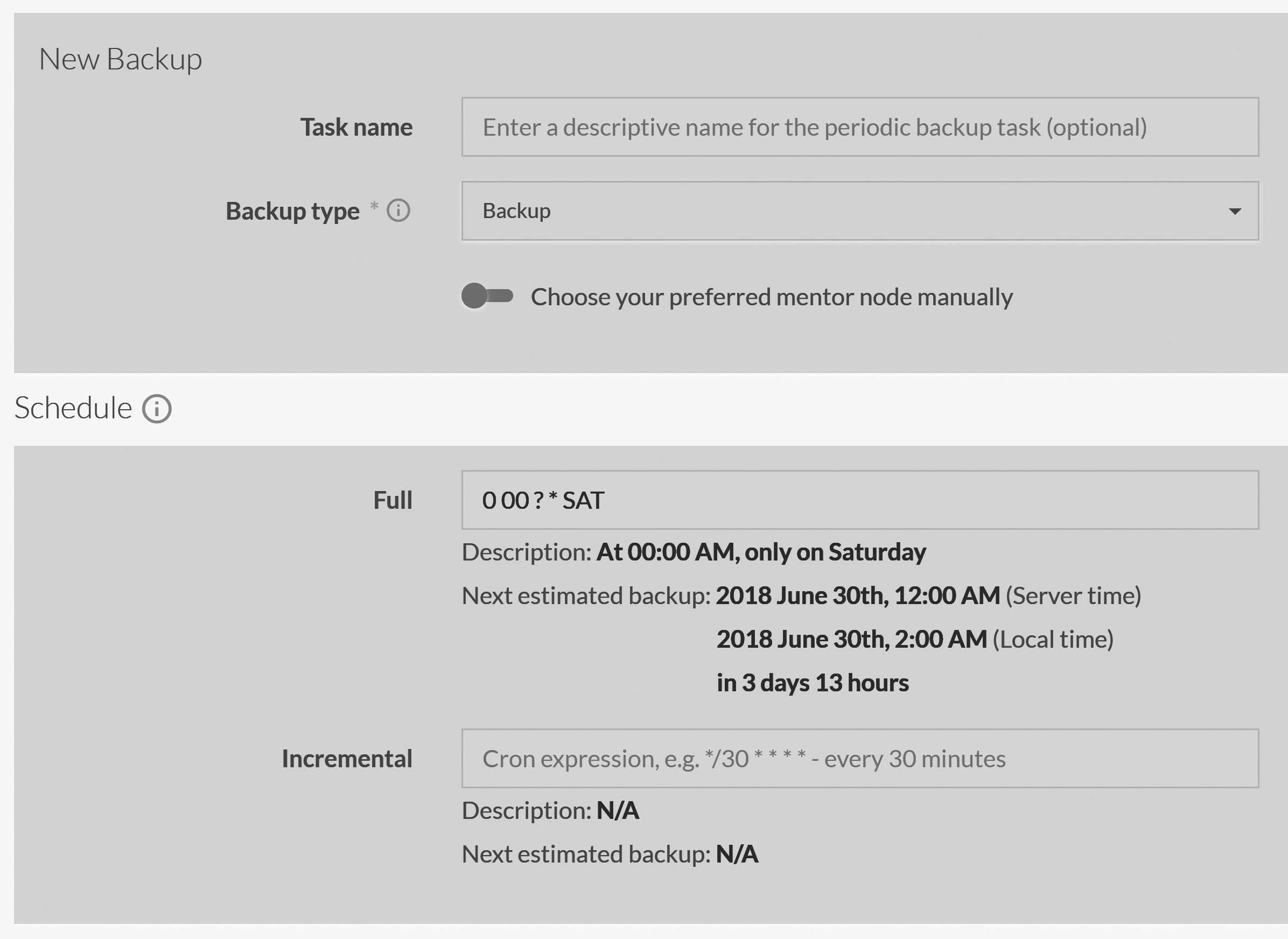
In Figure 17.3, we have defined a backup that is scheduled to run in full at 00:00 a.m. every Saturday. As you can see, RavenDB uses cron expressions to define recurring backup schedules. In the case of Figure 17.3, we have defined only one weekly full backup. The incremental backup duration is empty, so no incremental backups will be generated.
Manual backups aren't a thing for RavenDB
RavenDB doesn't have a way to specify a one-time backup. You can define a backup schedule, force it to run immediately and then discard it, but all backup operations in RavenDB are intrinsically tied to a schedule. This is because we treat backups not as something that the admin needs to remember to do, but as something that should be on a regular schedule. Once scheduled, RavenDB takes care of everything.
You can see in Figure 17.3 that we didn't select the preferred mentor node, which means we've let the server assign any node to the backup task. Even if we were to choose a preferred node, if that node were to go down at the time of the backup, the cluster would still re-assign that task to another node to ensure that the backup happens.
When will my backup run?
Time is an awkward concept. In the case of a backup schedule, we have a few conflicting definitions of time:
- The server's local time
- The admin's local time
- The user's local time
In some cases, you'll have a match between at least some of those definitions, but in many cases, you won't. When you define a backup schedule for RavenDB remember that RavenDB always uses the server local time. This can be confusing. You can see that Figure 17.3 lists the next estimated backup time in triplicate: once in the server local time (the time you actually used in your definition), once in the admin's own time and once as a time interval until the next backup.
RavenDB also expects that your servers' clock will be (more or less) in sync. There is no actual requirement for this to be the case, but since we use the server's local time to schedule backups, one node's midnight might be middle of the business day for you. In general, it is easier if all nodes agree to follow same timezone and sync their clocks on a regular basis.
You can save the backup task definition as it stands, but that won't really do much since no destinations have been defined yet. In order to be able to use the backup task, we need to tell the system where it should write backups to. RavenDB supports the following destinations:
- Local/network paths
- FTP/SFTP
- Amazon S3
- Azure Storage
- Amazon Glacier
Figure 17.4 shows how you can define a backup task that will write to a local folder as well as to an Amazon S3 account. The backup will run once each time it is executed, and the backup files will be sent to all the specified destinations from that single source.
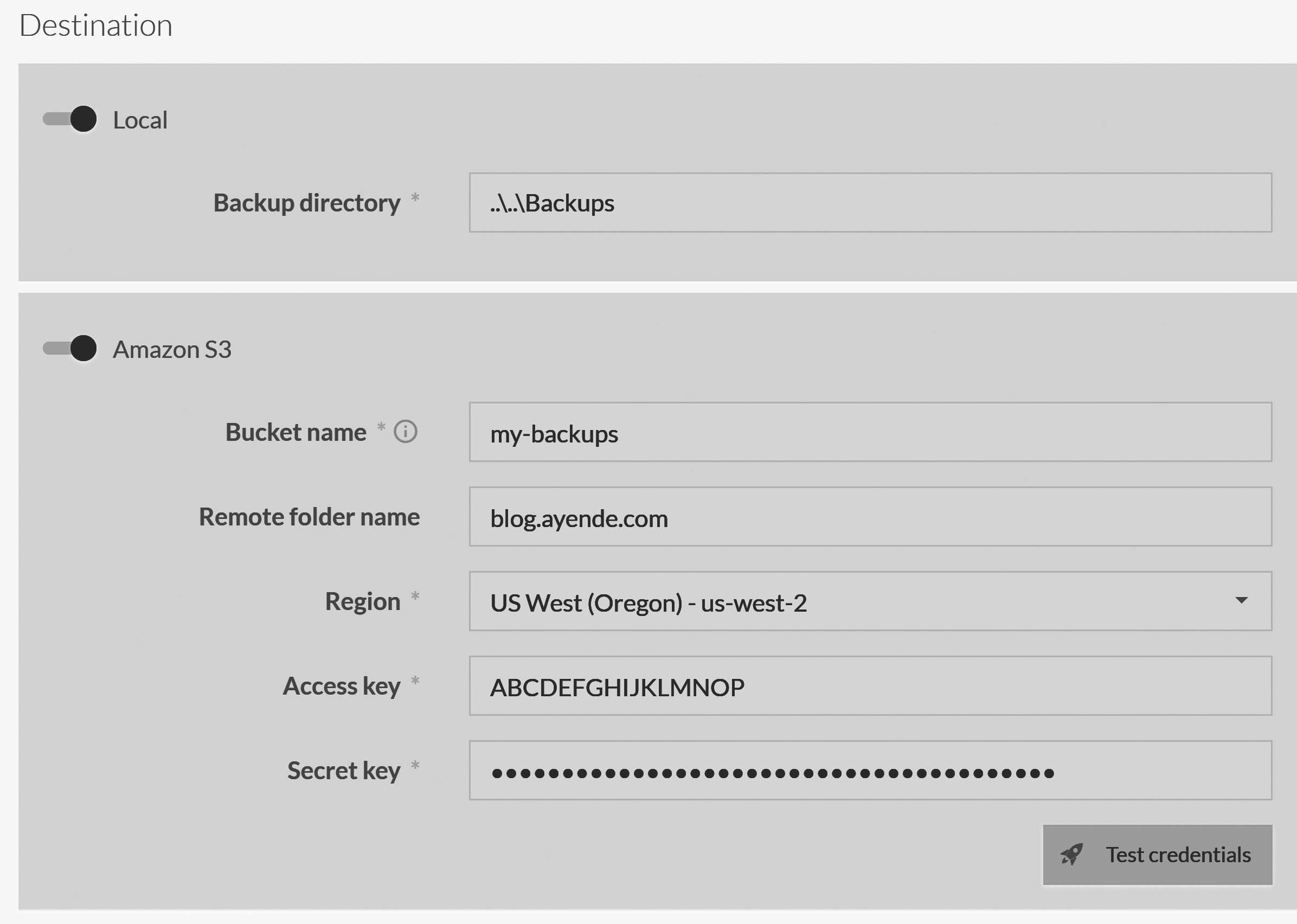
The backup process will first write the backup to the local path (or to a temporary path if the local path is not specified). Once that's done, the backup owner will start uploading the backup to all remote destinations in parallel. If any of the remote destinations fail, the entire backup will be considered to have failed.
Removing old backups
RavenDB does not remove old backups. Instead, RavenDB relies on the operations team to set things up properly. That can take the shape of a cron job that deletes backup folders that are too old, which can be as simple adding the following to your crontab:
0 4 * * * find /path/to/backup/* -type d -mtime +14 -deleteThis will run a backup every day at 4 a.m. and delete all directories over 14 days-old. If you don't set up a process something similar to this, backups will accrue until you run out of disk space. In particular, be very careful about setting backups to the same volume your database is using. There have been many not-so-humorous incidents where backups took up whole disk spaces and caused RavenDB to reject writes because there was no more space for them.
You'll need to decide your own policy for remote backups. It is fairly common to never delete backups in the interest of always being able to go back to a specific moment in time. Given how cheap disk space is today, that can be a valid strategy.
The local backup option also supports network paths (so you can mount an NFS volume or use \\remote\directory)
and it treats them as if they are local files. If you define both a local path and a remote one (for example, Azure Storage),
RavenDB will first write to the local path and then upload from there. If the local path is actually remote and only being treated as local, that
can increase the time it takes to complete the backup.
When selecting a local path, take into account that the backup task may run on different nodes. It is usually better to use either an absolute path (after verifying that it is valid on all machines) or a relative path. In the latter case, the path is relative to the RavenDB executable, not to the database location.
I'm going to skip going over the details of each of the backup options; the online documentation does a good job of covering them, and you can probably figure out how to use them even without reading the docs. Instead, let's look at what the backups look like after we have defined them.
Your database backup status
After defining the backup schedule and the backup destinations, you can click Save and the Studio will take
you back to the Manage Ongoing Tasks page where you'll see the tasks distribution across the cluster, as is shown
in Figure 17.5.
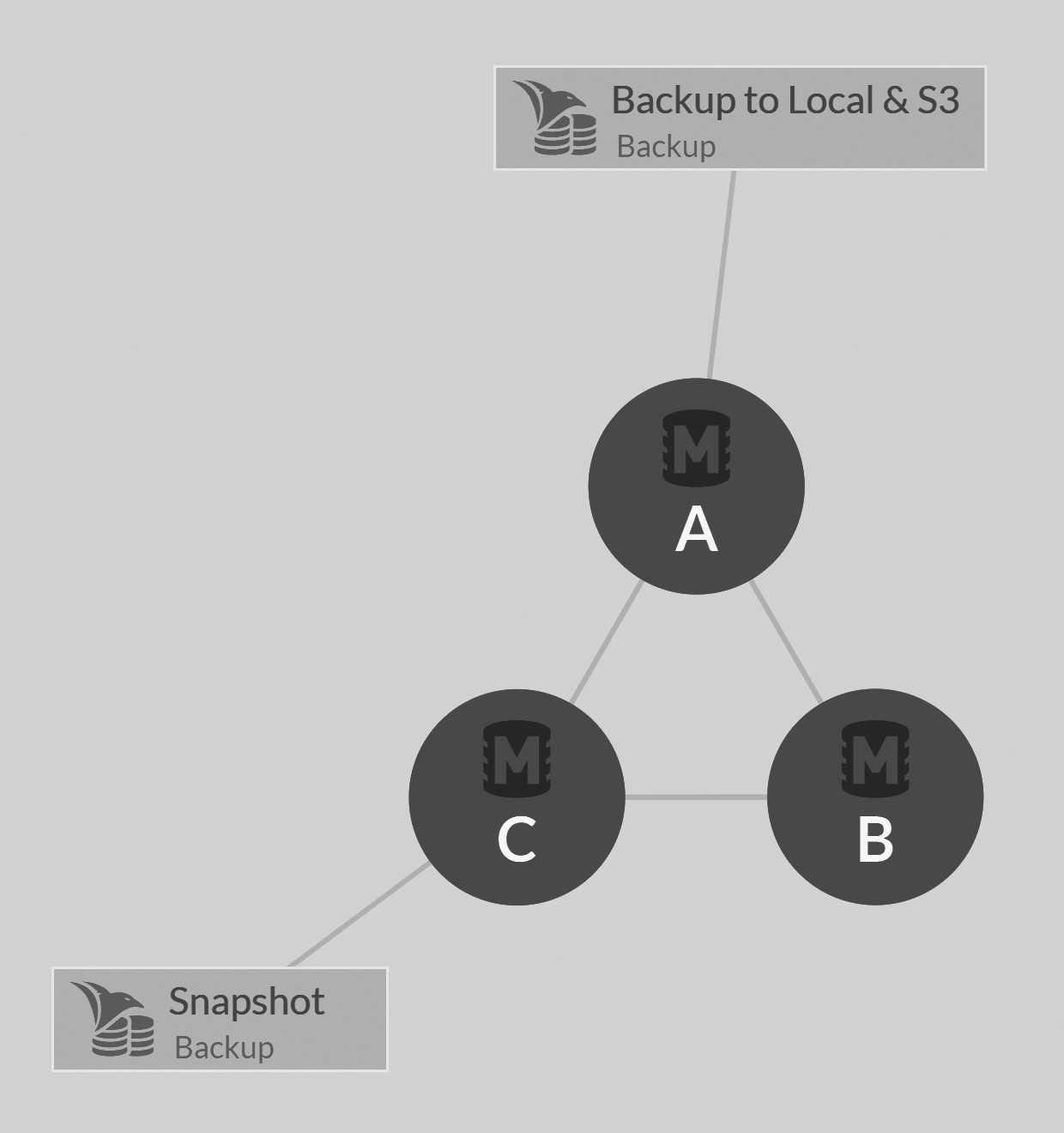
Figure 17.5 shows the nodes on which each task will run. Click the details icon to expand and see the full details for each backup task defined for the database, as can be seen in Figure 17.6.
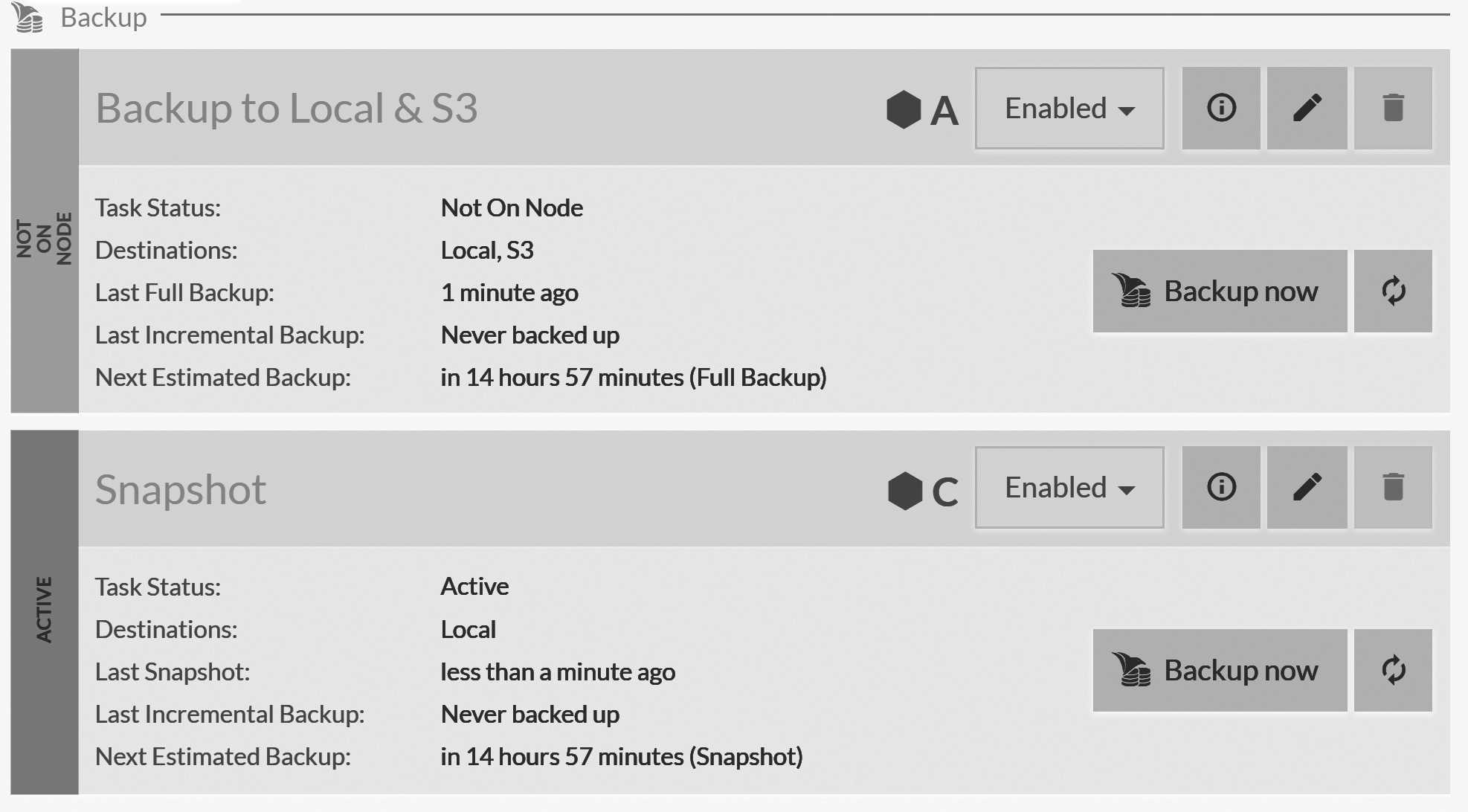
Figure 17.6 shows the most recent successful full and incremental backups, as well as the time of the next scheduled backup. You
can also see that you have the option to trigger a backup immediately. Note that the backup will run on the assigned node, not on the node opened in the Studio view.
So in this case, even though I'm accessing this view from node C, if I press Backup now on the first backup
(which is assigned to node A), it will be executed on node A.
Backup tasks are always defined as scheduled tasks that run automatically. If you haven't scheduled them, RavenDB will make it clearly visible to you in the
databases list view, as shown in Figure 17.7. You can see that the users.northwind database has never been backed up, while the
status of most recent backups for the other databases is also shown.
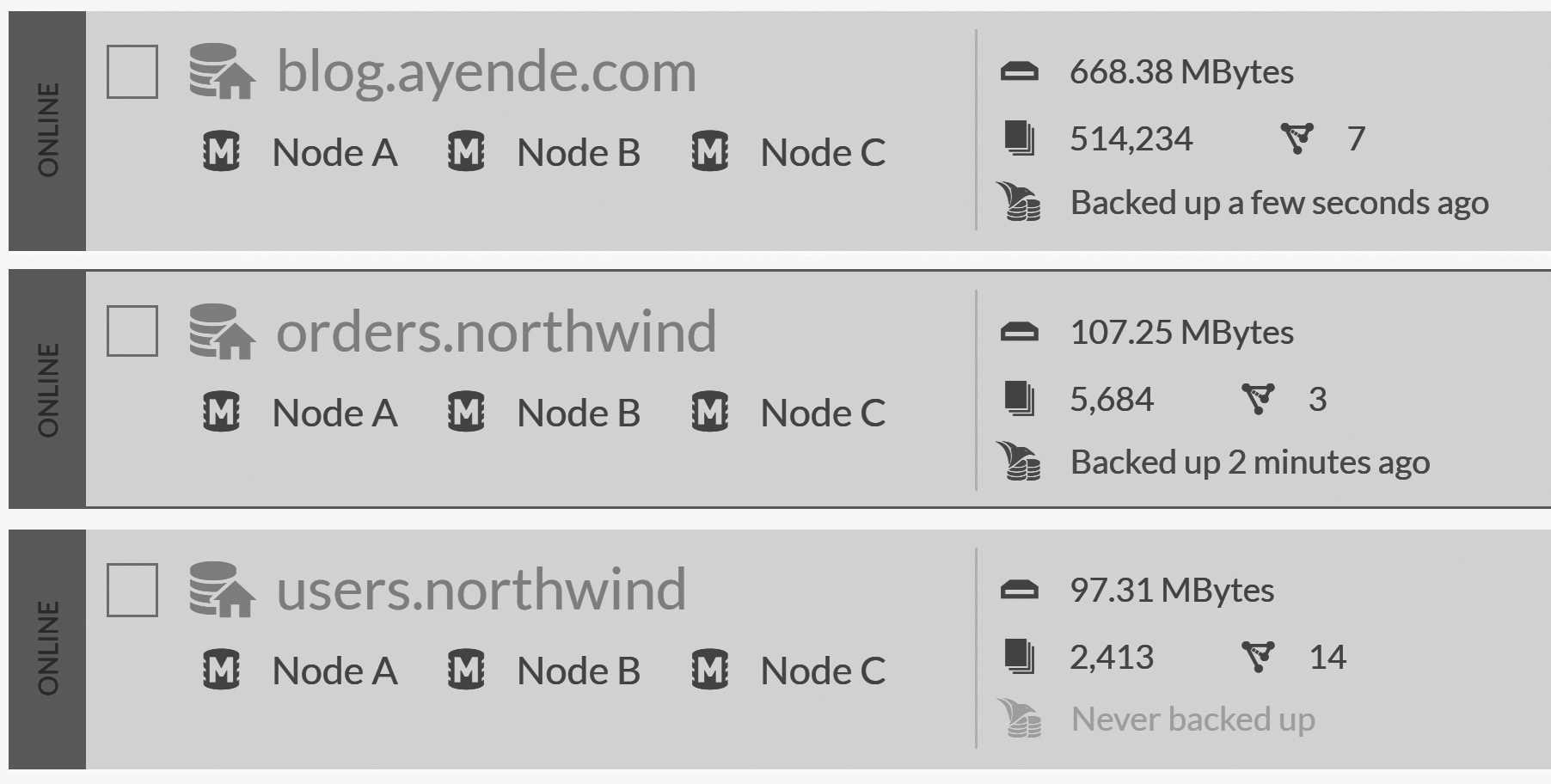
This is an important piece of information, and RavenDB makes sure that it is clearly visible to the operator.
This concludes the topic of backups. You now know everything there is to know about how to set up and schedule backups in RavenDB. But we aren't actually done. Backups are just half the job; we now need to talk about how we actually handle restores.
Restoring databases
We've talked about how to generate backups, but the most important thing about backups is actually restoring
a database from a backup. RavenDB attempts to make the restore process simple and obvious. To start the restore process, go to the Databases view in the Studio and click on the chevron near the New database button, then select
New database from backup. The result is shown in Figure 17.8.
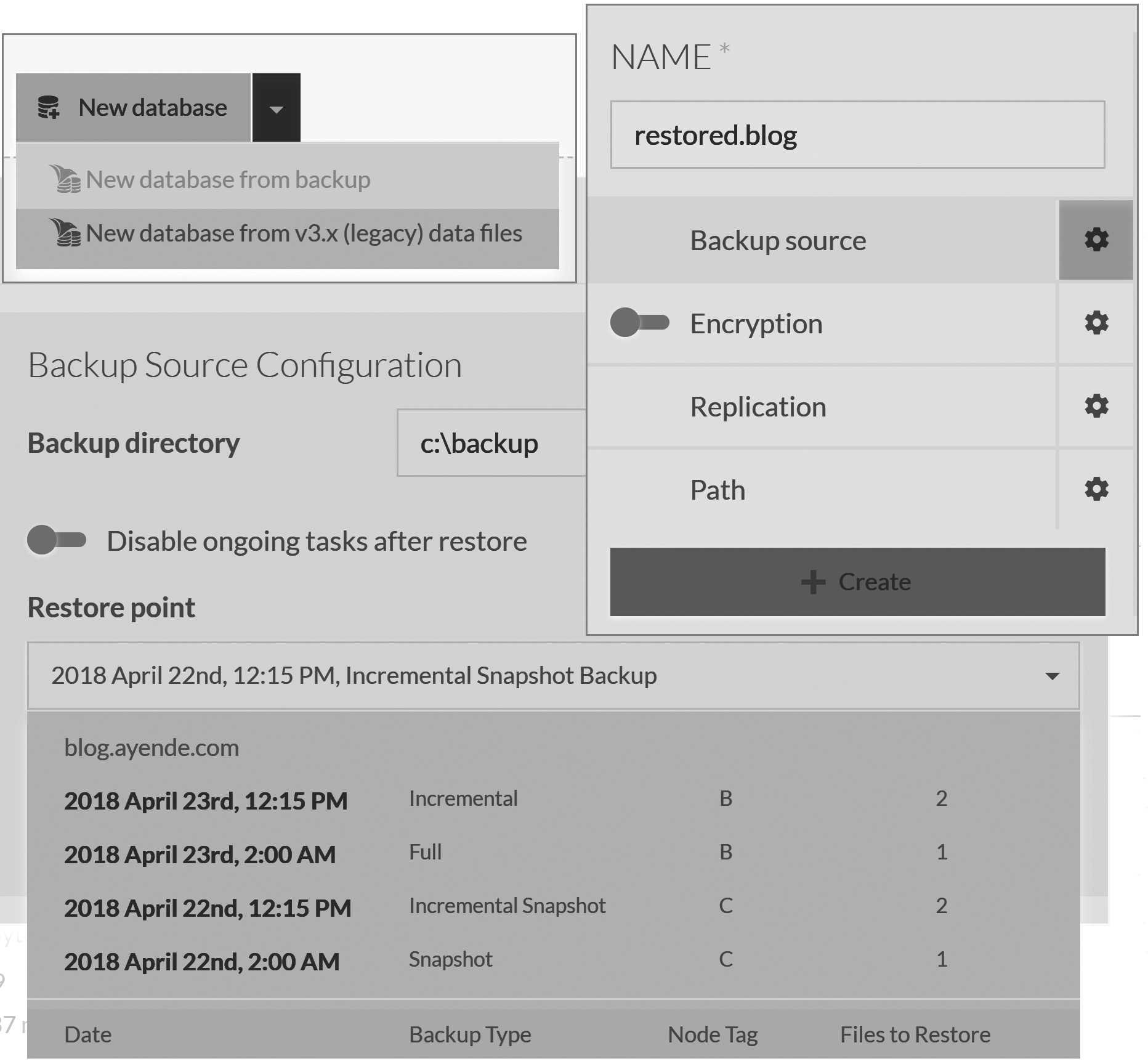
Figure 17.8 shows the basic structure of restoring a RavenDB database. You create a new database from backup, then provide the name for the new database (the name is cropped from Figure 17.8 for space reasons) and the path for the backup. Once you have provided the path, RavenDB will inspect the directory and list the backups that can be restored from that path.
You can see that in this case, we have a snapshot from node C from April 22 at 2 a.m. and an incremental snapshot from the same node from 12:15 p.m. of the same day. The next day, April 23, we have a full backup at 2 a.m. from node B and an incremental backup at 12:15 p.m. RavenDB makes it easy to decide to which point in time you will restore. RavenDB also knows how to start from a full backup or a snapshot and then apply the incremental backups up to the point you have specified.
Figure 17.8 also contains a bit more information. Some slicing and dicing was required to make everything fit into the pages of this
book, but it should be clear enough. Of great importance is the Disable ongoing tasks after restore flag. If this is set, RavenDB
will disable all ongoing tasks (backups, subscriptions, ETL processes, etc.) in the database. This is what you want if you are
restoring a database for a secondary purpose (i.e., you want another copy of the database, but you don't want the same behavior). You
want to disable this flag if you're restoring to replace the database. Since this is the primary reason for database restoration, this flag is disabled by default.
Backup locations
RavenDB doesn't care if all your databases put their backups in the same location; it uses the database name as part of the backup folder name to distinguish which database is responsible for which backup. On restore, you can provide the root backup path for all your backups and RavenDB will probe that path for all available backups, then sort them by their database and date.
If you have a lot of databases (or a lot of backups), it can be awkward to search for a specific one within a big list. It is usually easier to specify a separate backup folder for each database (such as
e:\backups\blog.ayende.com,e:\backups\users.northwind, etc).
Figure 17.8 also shows some interesting options. If you are using a full backup option, you can specify that the new database will be encrypted (and set up a new key).3 Figure 17.9 shows the result of the restoration process.
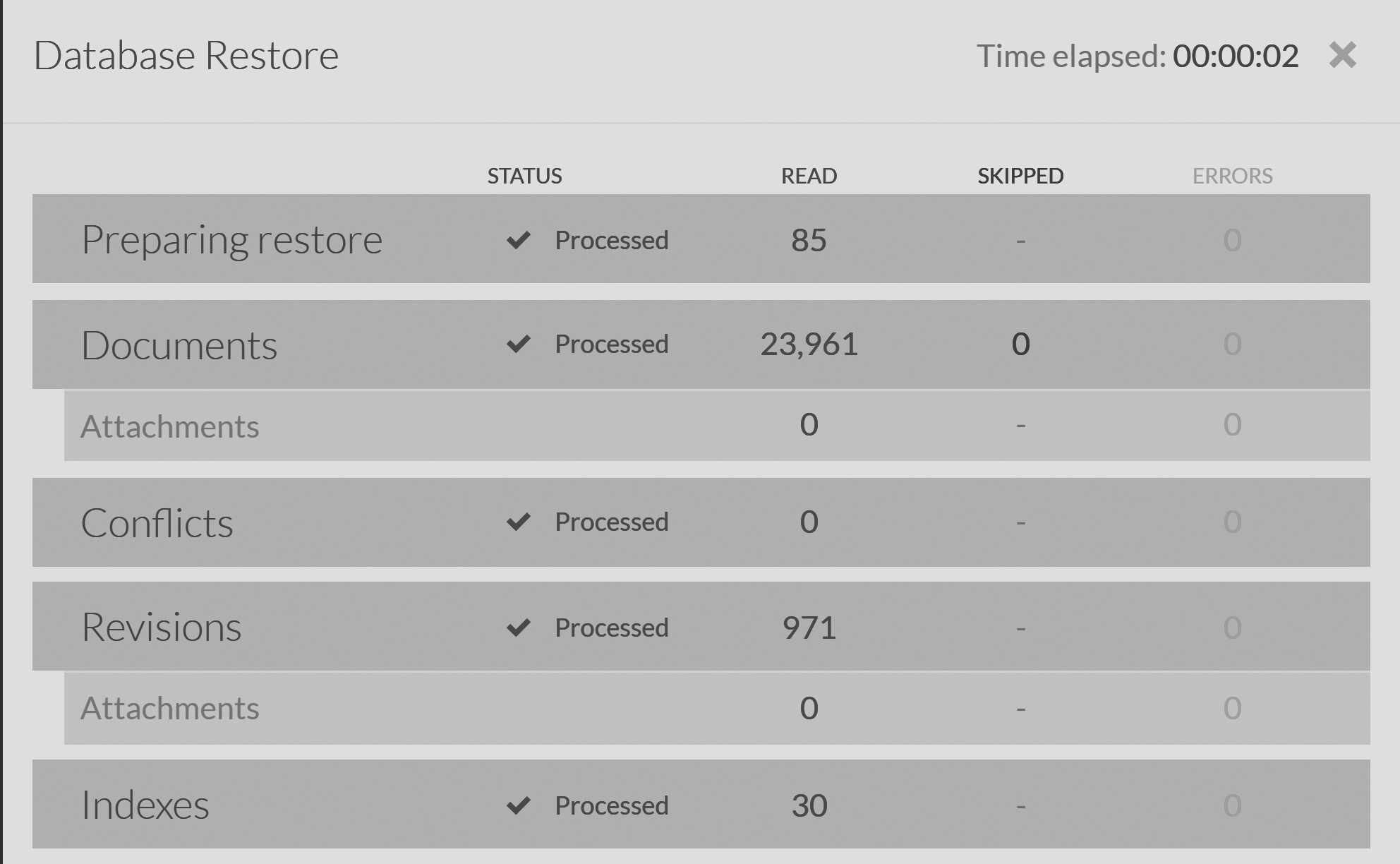
The restoration process can take a long time. In Figure 17.9, you can see that the process took two seconds or so when the database size was about 700MB ,and you can see the details about each part of the database that was restored from the backup. This is a very small database. For databases that range in the hundreds of GB or more, you can expect much longer restore durations. Snapshots speed up the process significantly, but the cost in I/O is significant and should be accounted for. You should practice your restores to see how much of a toll they take on your hardware and account for that in any disaster recovery plans you make.
In particular, you need to account for the fact that you must have the backup files accessible to the machine. Consider a backup strategy that backs up to a local folder (retained one week), Amazon S3 (retained one year) and Amazon Glacier (retained forever).
Assuming that you want to restore from a recent backup, you can expect a pretty speedy restore time. I have tested this on an
AWS machine (t2.large with 2 cores, 8GB of RAM and an EBS volume with 2,000 IOPS). Restoring a full backup from a 5GB
backup file had a restore time of about three hours.
A full backup that is 5GB in size is compressed JSON, which usually has really good compression properties. Such a backup
expanded to a database whose size exceeded 350GB. That takes time to insert to the database. A snapshot can usually
be restored more quickly. But the same 350GB database will have a snapshot of about 30GB, which on the t2.large machine
took just under an hour.
I intentionally took the numbers in the above example from a relatively low-powered machine; your real production machines are likely to be more powerful. But even on a more powerful machine, you will still have a length of time during which the server will be restoring the database. And remember that this is when the backup is available on the local machine. If you need to restore from Amazon S3, you also need to account for the time it will take to fetch the data from S3 (which can be significant for large databases). Using a service like Amazon Glacier has a minimum latency of days. These time lags have to play a part in your disaster recovery plans.
Remember to account for indexing time as well
When measuring the restore time, you need to take into account that indexes will need to be updated as well. A snapshot restore includes the database state (with all the indexes) at the time of the snapshot, but incremental restores on top of that (and full/incremental backups in general) only include the index definitions, not the indexed data.
RavenDB will complete the restore of the backup when all documents have been written; RavenDB will not wait for the indexes to complete. Indexing of the data is then done normally through async tasks and may take a while to complete, depending on how much there is to index. This is done to give you access to the documents and to enable you to start defining a replication factor for the new database as soon as possible.
Backups are not for high availability
I've emphasized the length of time restoring from backup can take a few times already, and I feel like I need to explain exactly why this is the case. There is a (mistaken) belief within some operations teams that they can get away with having just a single instance and handling any reliability issues that come up by restoring from backup.
To a certain extent, this is true, but only if you don't care about the availability of your system. Relying on restoring from backup could mean that you get stranded without a database for a long time. This is especially likely if you don't have a regularly practiced process for restoring the data.
Conversely, if you have a cluster and a database that spans multiple nodes, that does not mean you can just ignore making backups. Spreading the database on multiple nodes ensures that any single node (or even multiple nodes) going down will not affect your ability to access and modify your data. However, it does absolutely nothing to protect you from accidental data modifications or deletes. That is what a backup gives you: the ability to roll back the clock on a mistake and revert to a previous state of the database.
There's another option available to you that somewhat combines these two options: delayed external replication. You can set up a replication target that has a certain amount of lag built in. For example, you can specify that you want a six-hour delay in replication. This means that any change made to your system will not be reflected on the replica for six hours. This gives you a hot node that you can refer to and from which you can recover lost or modified data.
Restoring is done locally
When you restore a database, you always provide a file path. This is a path for the specific node that you are restoring from, and the path is local to this node. The database will also be restored only to that specific node. This local restoration has several interesting implications.
First, you need a file path: a way to expose the backups to RavenDB. This is easy enough when you are backing up to a local path in the first place, but what happens if you have backed up to Azure Blob Storage or to Amazon S3? In those cases, you will usually download the files to your local machine and then restore them from the local path.
Alternatively, you can use projects such as S3FS-FUSE and BlobFUSE to mount cloud storage as a normal volume in your system.
This will allow RavenDB to access the data directly from these systems without having to first download it to the local machine,
and that can save some time in the restoration process.
The second implication of the local restore is that if you want to restore a database to multiple nodes, the typical process is to restore it on one node and then modify the database group topology to spread it to the other nodes. Part of the reason that we make the database available immediately after backup, even before the indexes have had a chance to run, is that doing so allows us to start replicating the data to other nodes in the cluster as soon as possible.
Restoring to multiple nodes at the same time
As already mentioned previously, restoring from a backup can be a lengthy process. Even though we don't recommend treating backups as time-sensitive operations, you are likely to want to spend as little time on them as possible. One option for decreasing the time backups take is restoring databases to multiple nodes at the same time.
The idea is that restoring to multiple nodes at once cuts out the secondary step of replicating data to the other nodes in the cluster after the initial node restore is completed. The problem with this approach is that it ignores the real cost of data transfer. In most cases, you'll restore to the node where you have the latest backup because that is the node that will take the least amount of time to restore on. Then, once you have the database up and running, you can expand it at your leisure.
Restoring the database on other nodes simultaneously will require copying all the backup data to the other nodes and then restoring there as well. This is doable, but it rarely speeds up the entire process in any significant way, and it usually adds overhead. There are other issues as well. When restoring from a full backup to multiple nodes, each instance will generate its own separate change vectors for each document. RavenDB is able to handle that and can reconcile such changes automatically, but it still means that each of the nodes will have to send all the data to all the other nodes to compare between them.
The process is slightly different when using snapshots. Because snapshots are binary clones of the database from a specified time, restoring on multiple nodes can be done without generating different change vectors. This means that the databases can detect early on that the data they have is identical without even having to send it over the network. For this reason, I'm only going to explain how to perform a multiple node restore for snapshots (and still, it's probably not something that you should usually do). Here is what you'll need to do:
- Ensure that on all the nodes in the cluster you want to restore on, you have a way to access the data.
You could do this by copying it to each machine, having it shared on the network or using mount tools such as
S3FS-FUSEand the like. If you are using some sort of shared option (such as network drive, NAS or some form of a cloud drive) you have to take into account that the nodes might compete with one another for the I/O resources to read from the shared resource. - On the first node (node A), restore the database using the original name (
users.northwind, for example). On the other nodes (B and C), restore the database using different names (users.northwind.1,users.northwind.2). - Wait for the restore process to complete on all the nodes.
- Soft delete the additional databases on each of the nodes. This will remove the databases from the cluster but retain the data files on disk.
- On each of these nodes, rename the database folder on file to the proper database name (
users.northwind). - Expand the database group to all the other relevant nodes (so
users.northwindwill be on nodesA,BandC).
What does this process do? First, it restores the database on all the nodes in parallel, under different names. Because a snapshot is a binary copy of the database, the nodes end up with the same data on disk. We then soft delete the databases on all but one of the nodes and rename the database folders to the proper name on disk. When we add new nodes to the database, the new topology will be sent to all the nodes in the database group. Each of these nodes will open the database at the specified path and find the already restored data there.
For large restores, following these steps can save you quite a bit of time, though it will be at the expense of giving more work to the operator. You'll need to decide whether that's worth it for your scenario or not.
This process works because the change vectors across all the databases instances are the same, so there is no need to reconcile the data between the nodes. Since you're looking to reduce restoration time, I'm assuming you have a non-trivial amount of data. If you use a full backup instead of a snapshot, each node will generate different change vectors and each database instance will have to compare its documents to the other nodes' documents. This will work, mind you, but it can take time and a lot of network traffic.
It's true that any incremental backups that are applied to the snapshot restore will have the exact same problem. But I'm assuming that the amount of modified documents in this case is small enough that it effectively won't matter. The nodes will just need to reconcile the differences between the change vectors of the documents that were changed since the last full snapshot. That is unlikely to be a significant number of documents, so the process should finish quickly.
Restoring encrypted databases
We talked about encryption in detail in Chapter 14, so I'm going to focus here on just the practical details of handling the restoration of encrypted databases. In practice, there are three scenarios that interest us in this regard:
- Restoring a full backup.
- Restoring an encrypted snapshot.
- Restoring a non-encrypted snapshot.
If you look at Figure 17.8, you'll see that the restore dialog has an Encryption dialog, which is how you'll define
the encryption options for the restored database. For a database restored from backup, the data isn't encrypted in the
backup file. Defining an encryption key will encrypt the newly restored database.
When you restore from an encrypted snapshot, you must provide the encryption key (in the Encryption dialog) during
the restore process. The encryption key is not stored in the snapshot, and you must retrieve it from your own records.
(When creating a new database with encryption, you are prompted to save the encryption key in a safe location.)
Once you provide the encryption key for the snapshot, the database will be restored normally and any incremental updates
that happened after the snapshot was taken will also be encrypted and stored in the database.4
When restoring an unencrypted snapshot, you cannot provide an encryption key. You must first restore the snapshot and then export/import the data to a separate encrypted database.
Summary
In this chapter, we have gone over the backup and restore procedures for RavenDB. More importantly, we started by understanding how the RavenDB backup process works by looking into exactly what backup options are available to you with RavenDB. The first choice you have is between a backup and a snapshot. A snapshot is a full binary clone of the database at a particular point in time. Although compressed, it is typically fairly large. A backup (full or incremental), on the other hand, is a compressed JSON format that tends to be much smaller than a snapshot. Snapshots reduce restoration time, while backups take up a lot less space (particularly important for backups that you might retain for years).
We discussed what exactly is included in a backup or snapshot, from obvious things like documents and attachments to less-obvious things like data that is usually stored at the cluster level (such as indexes, identities and compare exchange values). All of these are bundled into a single location and can be restored as a single unit.
Then we delved into who actually runs backup tasks, which led to an exploration of the way the RavenDB cluster assigns ownership of backup tasks and how tasks get executed. In general, RavenDB will always ensure that someone is going to run the backup process to keep your data safe. That includes moving ownership of the backup task between nodes if there are failures and gracefully recovering from such failures.
We then turned to how backups get scheduled. RavenDB expects the administrator to set up a backup schedule and leave everything else at the hands of RavenDB. The automatic scheduling of full and incremental backups alongside the ability to shift backup ownership means that the administrator can relax and let RavenDB do its job. The only thing the administrator really needs to consider is what kind of cleanup policy should be in place for old backups. Everything else is handled for you.
RavenDB goes to great lengths to make sure that you're aware of the backup state of your database, and it will explicitly warn you if a database hasn't been backed up properly. You can also inspect quite a lot of details about backups to verify what is going on in this regard.
The other side of backups is actually restoring databases to their previous state. We talked about how to use the RavenDB Studio to restore a backup to a node and how to select the appropriate point in time to which the database will restore. Remember, restoring a database from backup takes time and can impact operations; you should not rely on "let's restore from backup" as a failover strategy.
Restoring a database is done on a single node, typically reading from local storage.5 After the database restore has completed, you can expand the database group to additional nodes in the cluster. It's also important that you remember to disable ongoing tasks during restoration if you're restoring for a secondary purpose (such as checking the state of the database at a particular point in time), rather than recovering from losing a database.
Databases are usually restored to a single node, but we also discussed some options for reducing recovery time by restoring a database to multiple nodes at once. This is a manual operation that has quite a few moving parts. If you can avoid it, restoring to a single node and then replicating the data from that node is often easier, simpler and in some cases, even faster.
We concluded the chapter with a short discussion on restoring encrypted databases, although the topic was covered in more depth in Chapter 14. Our next (and last) chapter is right around the corner, where we'll discuss operational recipes – specific scenarios you might run into in your day-to-day work maintaining RavenDB clusters – and how best to deal with them.
-
Remember that a single–node system cannot have any uptime SLA, since a single node failure will bring the whole thing down.↩
-
You can also set up backups through the API, of course.↩
-
This option is not available for snapshots. A snapshot is a binary copy of the database at a given point in time. Either it is already encrypted and has its own key, or it is unencrypted and will require an import/export cycle for encryption.↩
-
It's important to remember that while the snapshot itself is encrypted, the incremental updates made since the snapshot was taken are not encrypted and are storing the data in plain text mode.↩
-
You can also set up cloud storage mount volumes using external tools, which will be exposed to RavenDB as a local path.↩
