 Skip to Navigation
Skip to Navigation
Batch Processing With Subscriptions
RavenDB needs to handle some very different use cases in its day-to-day operations. On the one hand, we have transaction-oriented processing, which typically touches a small number of documents as part of processing a single request. And on the other hand, we have batch processing, which usually operates on large amounts of data. Implementing those kinds of processes with the OLTP mode is possible, but it isn't easy to do.
RavenDB supports a dedicated batch processing mode, using the notion of subscriptions. A subscription is simply a way to register a query with the database and have the database send us all the documents that match the query. An example of this might be, "Give me all the support calls." So far, this sounds very much like the streaming feature, which we covered in the previous chapter. However, subscriptions are meant for batch processing. Instead of just getting all the data that matches the criteria, the idea is that we'll keep the subscription open forever.
The first stage in the subscription is to send all the existing data that matches the query. Depending on the amount of data, this can take a while. It's done in batches, and RavenDB will only proceed to send the next batch when the current one has already been acknowledged as successfully processed.
The second stage in the lifetime of a subscription is when it's done going through all the data that's already in the database. This is where things start to get really interesting. At this point, the subscription isn't done. Instead, it's kept alive and waiting for new or updated documents that match the query. When that happens, the server will immediately send that document to the subscription. In other words, not only did we get traditional batch processing, but in many cases, we also have live batch processes.
Instead of waiting for a nightly process to run, you can keep the subscription open and handle changes as they come in. This keeps you from having to do things like polling and remembering the last items that you read. RavenDB's subscription also includes error handling, high availability and on-the-fly updates.
With subscriptions, work is divided into two distinct operations. First we need to create the subscription. Then we need to open it. Subscriptions aren't like queries; they aren't ephemeral. A subscription is a persistent state of a specific business process. It indicates what documents that particular subscription has processed, the query it is using, etc.
You can create the subscription through the RavenDB Studio. In the same database that we used in the previous chapter, go to Settings and then Manage Ongoing Tasks, and you'll
see the task selection dialog shown in Figure 5.1. Ignore the rest of the tasks and select Subscription. You'll see the subscription edit form. Now, name the task "CustomersSubscription" and enter from Customers in the query field. That's it. You can save the subscription. The result of this is shown in Figure 5.2.


You can also do the same through code, as shown in Listing 5.1. Here, you can see how we create a subscription for Customer documents.
Listing 5.1 Creating a subscription to process customers
var options = new SubscriptionCreationOptions
{
Name = "CustomersSubscription"
};
store.Subscriptions.Create<Customer>(options);
Regardless of whether you created the subscription manually or via code, the result is a named subscription. But the question is, what exactly is that? In the Studio, if you go to the edit subscription page, you'll see the option to test a subscription. If you select that option, you'll see a result similar to Figure 5.3.
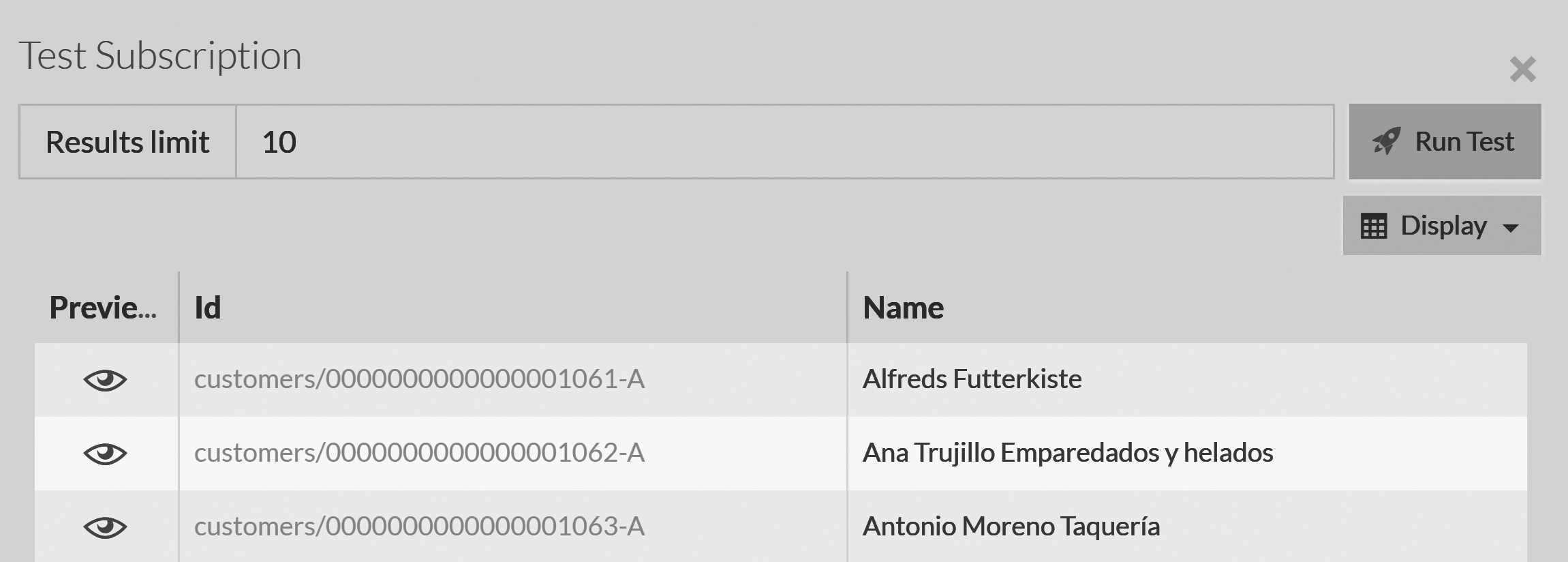
Those are the documents in the Customer collection, but what does this mean? A subscription is a way to go through all documents that match a query.
On its own, it isn't really
that interesting because we could see the same details elsewhere in the Studio. But the point of subscriptions isn't for you to manually go to the Studio
and inspect things. The point is that RavenDB will send those details to your code. You can see this in Listing 5.2, where we open the subscription and
start handling batches of documents on the client.
Listing 5.2 Opening and using a subscription to process customers
using (var subscription = store.Subscriptions
.GetSubscriptionWorker<Customer>("CustomersSubscription")))
{
// wait until the subscription is done
// typically, a subscription lasts for a very long time
await subscription.Run(batch => /* redacted */ );
}
Listing 5.2 shows the typical way of using a subscription. The subscription is opened with the subscription name that we created previously and then we Run the subscription. The actual batch processing of the documents is done by the lambda that's passed to the Run call on a background thread. I redacted the actual batch processing
for now. We'll see what that looks like in the next section.
After calling Run, we wait on the returned task. Why do we do that? In general, a subscription will live for a very long time — typically, the lifetime of the process that's running it. In fact, you'll often have a process
dedicated just to running subscriptions (or even a process per subscription). What we're doing in Listing 5.2 is basically waiting until the subscription exits.
There are fewer reasons than you might think for a subscription to exit. Problems with the network will simply cause it to retry or failover to another node, for example. And if it processed all the data that the database had to offer, it will sit there and wait until it has something more to give, rather than exiting. However, there are a few cases where the subscription will actually exit. The first, of course, is if you intentionally close it by disposing the subscription. It's safe to dispose the subscription while it's running, and that's how you typically do an orderly shutdown of a subscription.
Next, we might have been kicked off the subscription for some reason.
The admin may have deleted the subscription or the database. Or perhaps the credentials we used were invalid. Maybe the subscription connection was taken over
by another client. As you can see, the Run method will return only if you manually disposed the subscription. For most other cases, it will throw
when there's no way for it to recover. We'll cover more on this in the subscription deployment section later on in this chapter.
The subscription ID should be persistent, usually stored in configuration or loaded from the database. It's used to represent the state of the subscription and what documents have already been processed by that particular subscription.
You can set your own subscription ID during the Create call, which gives you a well known subscription name to use, or you can ask RavenDB to choose one for
you. Note that even if you used your own subscription name, it still needs to be created before you can use it.
But why do we have all those moving parts? We create the subscription, open it, run it and wait on the resulting task, and we haven't even gotten to
the part where we actually do something using it.
The reason for this is that subscriptions are long-lived processes, which are resilient to failure. Once a subscription is created, a client will open it and keep a connection open to the server, getting fed with all the documents that match the subscription criteria.
Once we've gone over all the documents currently in the database, the subscription will go to sleep but remain connected to the server. Whenever a new or updated document matches the subscription query, it will be sent to the subscription. Errors during this process, either in the network, the server or the client, are tolerated and recoverable. The subscription will ensure that a client will receive each matching document at least once.1
Subscription in a cluster
The subscription will connect to a server in the cluster, which may redirect the subscription to a more suitable server for that particular subscription. Once the subscription has found the appropriate server, it will open on that server and start getting documents from it. A failure of the client will result in a retry (either from the same client or another one that was waiting to take over). A failure of the server will cause the client to transparently switch over to another server.
The entire process is highly available on both client and server. The idea is that once you set up your subscriptions, you just need to make sure that the processes that open and process your subscriptions are running, and the entire system will hum along, automatically recovering from any failures along the way.
Typically, on a subscription that has already processed all existing documents in the database, the lag time between a new document coming in and the subscription receiving it is a few milliseconds. Under load, when there are many such documents, we'll batch documents and send them to the client for processing as fast as it can handle them. The entire model of subscription is based on the notion of batch processing. While it's true that subscriptions can remain up constantly and get fed with all the changes in the database as they come, that doesn't have to be the case. If a subscription isn't opened, it isn't going to miss anything; once it's re-opened, it will get all the documents that have changed while it was gone.
This allows you to build business processes that can either run continuously or at off-peak times in your system. Your code doesn't change, nor does it matter to RavenDB. A subscription that isn't opened consumes no resources. In fact, a good administrator will know that he can reduce the system load by shutting down subscriptions that are handling non-time-critical information with the knowledge that once the load has passed, starting the subscriptions up again will allow them to catch up from their last processed batch.
This is made possible due to the following flow: on each batch that the client receives, it acknowledges the server once it has successfully completed processing that batch. The server will not move forward and send the next batch until it receives this acknowledgment. It is this acknowledgment that makes this process reliable.
Okay, that's about all we can say about subscriptions without actually showing what they're doing. Let's see how RavenDB handles the actual document processing.
Processing a batch of documents in a subscription
We've previously seen the Run method, back in Listing 5.2. But what we haven't seen yet is what's actually going on there. The Run method is simply taking a lambda that will
go over the batch of documents. Listing 5.3 shows the code to handle the subscription that was redacted from Listing 5.2.
Listing 5.3 Processing customers via subscription
await subscription.Run(batch =>
{
foreach (var item in batch.Items)
{
Customer customer = item.Result;
// do something with this customer
}
});
After all this buildup, the actual code in Listing 5.3 is pretty boring. The lambda we sent gets a batch instance, which has a list of Items that are contained
in this batch. And on each of those items, we have a Result property that contains the actual document instance we sent from the server.
This code will first get batches of all the customers in the database. Once we have gone through all the customer documents, this subscription will wait, and
whenever a new customer comes in or an existing customer is modified, we'll have a new batch with that document. If there are a lot of writes, we might get
batches containing several documents that were changed in the time it took us to complete the last batch.
What can we do with this? Well, as it turns out, quite a lot. We can use this to run all sorts of business processes. For example, we may want to check if this customer has a valid address, and if so, record the GPS coordinates so we can run spatial queries on it. Because of the way subscriptions work, we get a full batch of documents from the server, and we can run heavy processing on them. We aren't limited by the data streaming over the network, and unlike streaming, we won't time out. As long as the client remains connected, the server will be happy to keep waiting for the batch to complete. Note that the server will ping the client every now and then to see what its state is and to detect client disconnection at the network level. If that's detected, the connection on the server will be aborted and all resources will be released.
Subscriptions are background tasks
It may be obvious, but I wanted to state this explicitly: subscriptions are background tasks for the server. There's no requirement that a subscription will be opened at any given point in time, and a subscription that wasn't opened will simply get all the documents it needs since the last acknowledged batch.
That means that if a document was modified multiple times, it's possible that the subscription will only be called upon once. See the section about versioned subscriptions if you care about this scenario.
One of the things to be aware of is that right from the subscription lambda itself we can open a new session,
modify the document we got from the subscription, Store the document and call SaveChanges on it.
But note that doing so will also put that document right back on the path to be called again with this
subscription, so you need to be aware of that and protect against infinite loops. There are also a few other subtle issues that we need to handle
with regards to running in a cluster and failover. We'll discuss those issues later in this chapter.
The subscription script
Subscriptions so far are useful but not really something to get excited about. But the fun part starts now. Subscriptions aren't limited to just fetching all the documents in a particular collection. We can do much better than this. Let's say that we want to send a survey to all customers with whom we had a complex support call. The first step for that is to create a subscription using the code in Listing 5.4.
Listing 5.4 Creating a subscription for complex calls
var subId = store.Subscriptions.Create<SupportCall>(
call =>
call.Comments.Count > 25 &&
call.Votes > 10 &&
call.Survey == false
);
Figure 5.4 shows the newly created subscription on the server side. You can see that the filter we provided on the client side was turned into a server
side script that decided whatever a particular SupportCall is a match for this subscription.
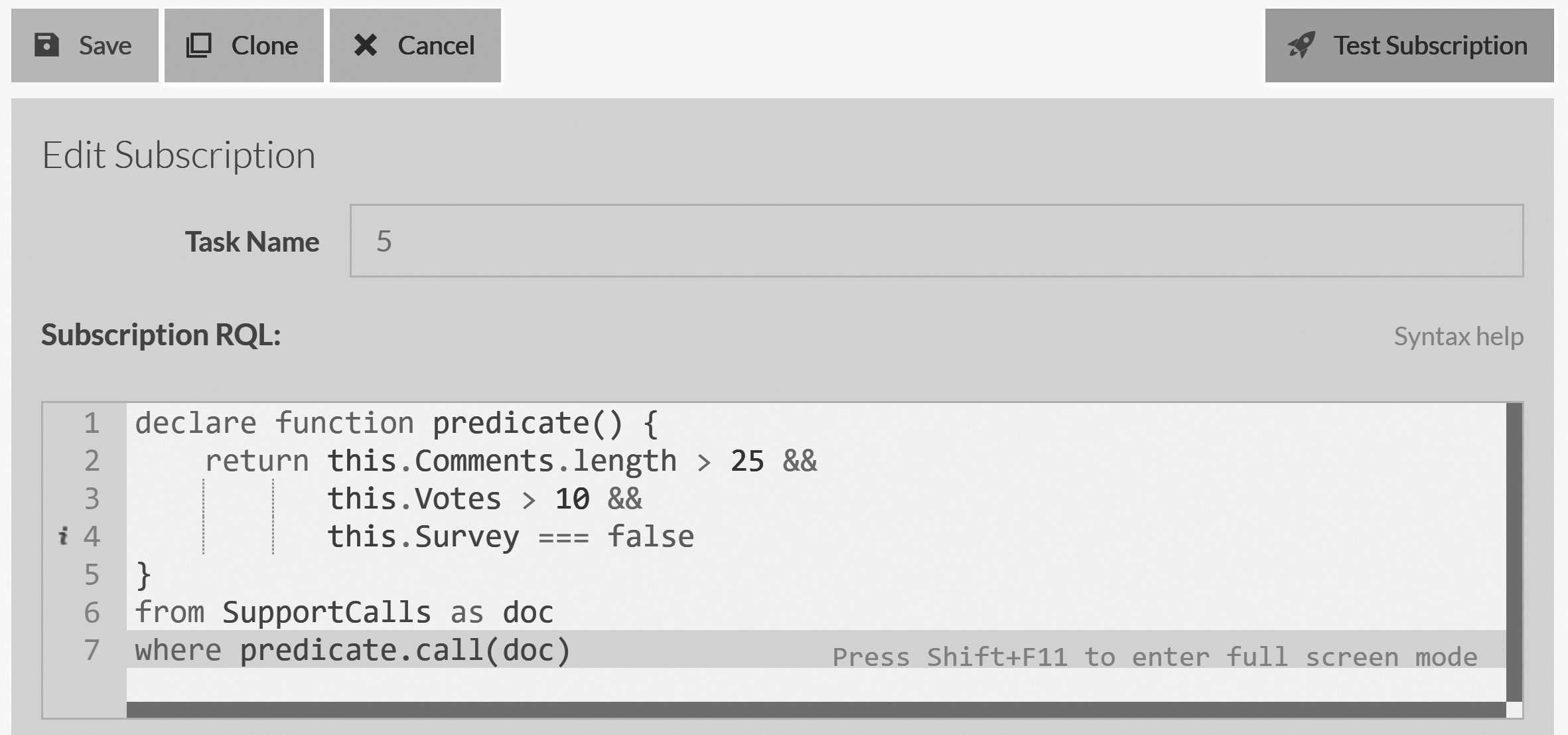
We've registered for support calls that have more than 10 votes and over 25 comments, and we add a flag to record whether or not we've sent the survey. It's important to note that this filtering is happening on the server side, not on the client. Internally we'll transform the conditional into a full query (see Figure 5.4) and send it to the server to be evaluated on each document in turn. Any matching document will be sent to the client for processing. Of course, this is just part of the work. We still need to handle the subscription itself. This is done in Listing 5.5.
Listing 5.5 Taking surveys of complex calls
await subscription.Run(batch =>
{
foreach (var item in batch.Items)
{
SupportCall call = item.Document;
var age = DateTime.Today - call.Started;
if (age > DateTime.FromDays(14))
return; // no need to send survey for old stuff
using (var session = batch.OpenSession())
{
var customer = session.Load<Customer>(
call.CustomerId);
call.Survey = true;
session.Store(call, item.ChangeVector, item.Id);
try
{
session.SaveChanges();
}
catch (ConcurrenyException)
{
// will be retried by the subscription
return;
}
SendSurveyEmailTo(customer, call);
}
}
});
There's a lot going on in Listing 5.5, even though we removed the code that actually opens the
subscription. For each item in the batch, we'll create a new session, load the customer for
this support call and mark the call as having sent the survey. Then we'll call Store and pass it not only the instance that we got from the subscription from
but also the change vector and ID for this document. This ensures that when we call SaveChanges, if the document has changed in the meantime on the server
side, we'll get an error.
Don't use the
store.OpenSessionin batch processingThe code in Listing 5.5 uses
batch.OpenSessioninstead ofstore.OpenSession. Why is that? Well, this is where I need to skip ahead a bit and explain some concepts we haven't seen yet. When running in a cluster, RavenDB divides the work between the various nodes in a database. That means that a subscription may run on node B while the cluster as a whole will consider node A as the preferred node to write data to.RavenDB handles that transparently, by replicating the information across the nodes in the cluster, including optimistic concurrency using the document's change vector, as we discussed in the previous chapter. However, reading from one node and writing to another can lead to subtle concurrency issues. RavenDB can handle these issues, but they can be surprising to users. It's generally better to write back to the same node you're reading from.
In order to avoid that, you should use
batch.OpenSession(orbatch.OpenAsyncSession) to create the session. This will ensure that the session you've created will operate against the same node you're reading from and thus will allow us to reason about the state of the system with fewer variables. If your subscription uses include, then the session created via batch will already have the loaded documents in the session cache.
In Listing 5.5, the concurrency exception is an expected error. We can just ignore it and skip processing this document. There's a bit of trickery involved here. Because the document has changed, the subscription will get it again anyway, so we'll skip sending an email about this call for now. But we'll be sending the email later, when we run into the support call again.
Finally, we send the actual email. Note that in a real production code, there's also the need to decide what to do if sending the email has failed. In this case, the code is assuming it cannot fail and favors skipping sending the email rather then sending it twice. Typical mail systems have options to ignore duplicate emails in a certain time period, which is probably how you would solve this in production.
Instead of using explicit concurrency handling, we can also write the code in Listing 5.5 using a Patch command, as shown in Listing 5.6.
Listing 5.6 Taking surveys of complex calls, using patches
await subscription.Run(batch =>
{
foreach (var item in batch.Items)
{
SupportCall call = item.Document;
var age = DateTime.Today - call.Started;
if (age > DateTime.FromDays(14))
return; // no need to send survey for old stuff
using (var session = batch.OpenSession())
{
var customer = session.Load<Customer>(
call.CustomerId);
session.Advanced.Patch<SupportCall, bool>(
result.Id,
c => c.Survey,
true);
SendSurveyEmailTo(customer, call);
session.SaveChanges();
}
}
});
In Listing 5.6, we're doing pretty much the same thing we did in Listing 5.5. The difference is that we're using a Patch command to do so,
which saves us from having to check for concurrency violations. Even if the document has changed between now and the time the server sent it to us,
we'll only set the Survey field on it. In Listing 5.6, we're also sending the survey email before we set the Survey flag, so a failure
to send the email will be thrown all the way to the calling code, which will typically retry the subscription. This is different from the code in
Listing 5.5, where we first set the flag and then sent the email.
The main difference here is in what happens in the case of an error being raised when sending the survey email. In Listing 5.5, we've already set the flag and sent it to the server, so the error means that we didn't send the email. The subscription will retry, of course, but the document was already changed and will be filtered from us. In Listing 5.5, if there was an error in sending the email, it won't be sent to the server.
Subscribing to documents on the database we're writing to
There are a few things to remember if you're using the subscription to write back to the same database you're subscribing to:
Avoid the subscription/modify loop. When you modify a document that you're subscribing to, the server will send it to the subscription again. If you modify it every time it's processed, you'll effectively create an infinite loop, with all the costs this entails. You can see in Listing 5.5 and Listing 5.6 that we're careful to avoid this by setting the
Surveyflag when we process a document and filter on the flag in Listing 5.4.The document you received may have already been changed on the server. Typically, the lag time between a document being modified and the subscription processing the document is very short. That can lead you to think this happens instantaneously or, even worse, as part of the same operation as modifying the document. Nothing could be further from the truth. A document may be changed between the time the server has sent you the document and the time you finished processing and saving it. In Listing 5.5, we handled that explicitly using optimistic concurrency, and in Listing 5.6, we used patching to avoid having to deal with the issue.
If you're using subscriptions to integrate with other pieces of your infrastructure (such as sending emails), you have to be ready for failure on that end and have a meaningful strategy for handling it. Your options are to either propagate the error up the chain, which will force the subscription to close (and retry from the last successful batch), or you can catch the exception and handle it in some manner.
On the other hand, in Listing 5.6, we first send the email, then set the flag and save it. This means that if there's an error sending the email, we'll retry the document later on. However, if we had an error saving the flag to the server and we already sent the email, we might send it twice. You need to consider what scenario you're trying to prevent: emailing a customer twice or not at all.
Instead of relying on two-phase commit and distributed transactions, a much better alternative is to use the facilities of each system on its own. That topic goes beyond the scope of this book, but both idempotent operations or deduplication of operations can give you a safe path to follow in the presence of errors in a distributed system. If the email system recognizes that this email has already been sent, the code in Listing 5.6 will have no issue. We'll never skip sending an email, and we'll never send the same email twice.
Distributed transactions and RavenDB
The main reason we have to face this issue is that we're forced to integrate between two systems that don't share a transaction boundary. In other words, theoretically speaking, if we could create a transaction covering sending the email and writing to RavenDB, the problem would be solved.
In practice, RavenDB supported distributed transactions with multiple resources up until version 3.x, where we deprecated this feature.
Version 4.0 removed it completely. Distributed transactions (also known as two-phase commit or 2PC) sound wonderful. Here you have a complex interaction between several different components in your system, and you can use a transaction to orchestrate it all in a nice and simple manner.But it doesn't actually work like this. Any distributed transaction system that I've worked with had issues related to failure handling and partial success. A distributed transaction coordinator basically requires all participants in the transaction to promise that, if it tells them to commit the transaction, it will be successful. In fact, the way a coordinator usually works is by having one round of promises, and if all participants have been able to make that promise, there will be a second round with confirmations — hence the "two-phase commit" name.
The problem starts when you've gotten a promise from all the participants, you've already confirmed with a few of them that the transaction has been committed and one of the participants fails to commit for whatever reason (hardware failure, for example). In that case, the transaction is in a funny, half-committed state.
The coordinator will tell you this is a bug in the participant — that it shouldn't have made a promise it couldn't keep. And commonly, coordinators will retry such transactions (manually or automatically) and recover from transient errors. But the problem with the line of thinking that deems this an issue with this particular participant and not the coordinator is that those kind of errors are happening in production.
For one project, we had to restart the coordinator and manually resolve hanging transactions on a biweekly basis, and it wasn't a very large or busy website. Joe Armstrong, inventor of Erlang, described2 the problem far better than I could:
The "Two Generals' Problem" is reality, but the computer industry says it doesn't believe in mathematics: two-phase commit3 always works!
There's another issue with the code in Listing 5.5 and Listing 5.6. They're incredibly wasteful in the number of remote calls that they're making. One of the key benefits of using batch processing is the fact that we can handle things, well, in a batch. However, both Listing 5.5 and Listing 5.6 will create a session per document in the batch. The default batch size (assuming we have enough documents to send to fill a batch) is on the order of 4,096 items. That means that if we have a full batch, the code in either one of these listings will generate 8,192 remote calls. That's a lot of work to send to the server, all of which is handled in a serial fashion.
We can take advantage of the batch nature of subscriptions to do much better. Turn your attention to Listing 5.7, if you would.
Listing 5.7 Efficiently process the batch
await subscription.Run(batch =>
{
using (var session = batch.OpenSession())
{
var customerIds = batch.Items
.Select(item => item.Result.CustomerId)
.Distinct()
.ToList();
// force load of all the customers in the batch
// in a single request to the server
session.Load<Customer>(customerIds);
foreach (var item in batch.Items)
{
SupportCall call = item.Document;
var age = DateTime.Today - call.Started;
if (age > DateTime.FromDays(14))
return; // no need to send survey for old stuff
// customer was already loaded into the session
// no remote call will be made
var customer = session.Load<Customer>(
call.CustomerId);
// register the change on the session
// no remote call will be made
session.Advanced.Patch<SupportCall, bool>(
result.Id,
c => c.Survey,
true);
SendSurveyEmailTo(customer, call);
}
// send a single request with all the
// changes registered on the session
session.SaveChanges();
}
});
Listing 5.7 and Listing 5.6 are functionally identical. They have the same exact behavior, except Listing 5.6 will generate 8,192 requests and Listing 5.7
will generate only two. Yep, the code in Listing 5.7 is always going to generate just two requests. The first is a bulk load of all the customers in the batch, and the second is
a single SaveChanges with all the changes for all the support calls in the batch.
Note that we're relying on the Unit of Work nature of the session. Once we've loaded a document into it, trying to load it again will give us the already loaded
version without going to the server. Without this feature, the amount of calls to Load would have probably forced us over the budget of remote calls allowed
for the session.4
Listing 5.7 takes full advantage of the batch nature of subscriptions. In fact, the whole reason why the batch exposes the Items list property instead of just being
an enumerable is to allow you to make those kinds of optimizations. By making it obvious that scanning the list of items per batch is effectively free, we're
left with the option of traversing it multiple times and optimizing our behavior.
Complex conditionals
We already saw how we can create a subscription that filters documents on the server side: it was shown in Listing 5.4. The code there used a Linq expression, and the client API was able to turn that into a query that was sent to the server. Listing 5.4 was a pretty simple expression, and the code that handles the translation between Linq expressions and queries is quite smart. It's able to handle much more complex conditions.
However, putting a complex condition in a single Linq expression is not a recipe for good code. A better alternative is to skip the convenience of the Linq expression and go directly to the query. In Listing 5.8, we're going to see how we can subscribe to all the support calls that require special attention.
Listing 5.8 Creating a subscription using JavaScript filtering
var options = new SubscriptionCreationOptions
{
Name = subscriptionName,
Query = @"
declare function isAnnoyedCustomer(call) {
const watchwords = ['annoy', 'hard', 'silly'];
const lastIndex = call['@metadata']['Last-Monitored-Index'] || 0;
for (let i = lastIndex; i < call.Comments.length; i++)
{
let comment = call.Comments[i].toLowerCase();
for (let j = 0; j < watchwords.length; j++)
{
if (comment.indexOf(watchwords[j]) !== -1)
return true;
}
}
return false;
from SupportCalls as call
where isAnnoyedCustomer(call)"
};
store.Subscriptions.Create(options);
The interesting code in Listing 5.8 is in isAnnoyedCustomer inside the query. We're defining a few words that we'll watch for, and if we see them in the comments
of a support call, we want to give that call some special attention via this subscription. We do that by simply scanning through the array of Comments and checking
if any comment contains any of the words we're looking for.
Use the subscription test feature
Any time that you need to run non-trivial code, you should consider how you'll debug it. Subscriptions give you a lot of power and they can carry the load of significant portions of your business logic. Because of that, it's very important that you will be able to test and play with them while developing.
For this reason, RavenDB has the subscription test feature. This feature will apply the subscription logic on top of the database and allow you to see the results of your filter or transformation scripts. We've already gotten a taste of that in Figure 5.3, but the more complex your queries are, the more useful this feature will become.
There's one item to consider here, though. A subscription test works just like a subscription. It matches all the documents in the particular collection you're operating on and applies the script to each and every one of them, giving you those documents that matched successfully. However, if your script filters out many of the matches and you have a large amount of data, it may take the subscription test a while to find enough documents that match your subscription filter.
You can reduce this time by selecting a document from which the subscription test will start the scanning process. This way it will not have to scan all the documents in the collection. Selecting such > a document is done in the
Send Documents Fromdropdown. While you'll typically use "Beginning of Time" as the default, you can save some time if you position the subscription directly on the first of the documents you want to process.
The one interesting tidbit is the use of call['@metadata']['Last-Monitored-Index']. What's that for? Remember that a subscription will be sent all the
documents that match its criteria. And whenever a document is changed, it triggers a check for a match with the subscription. That means that if we didn't have
some sort of check to stop it, our subscription would process any support call that had a comment with one of the words we watch for every single time
that call is processed.
In order to avoid that scenario, we set a metadata value named Last-Monitored-Index when we process the subscription. You can see how that works in
Listing 5.9.
Listing 5.9 Escalating problematic calls
await subscription.Run(batch =>
{
const string script = @"
var metadata = this['@metadata'];
var existing = metadata['Last-Monitored-Index'] || 0;
metadata['Last-Monitored-Index'] = Math.max($idx, existing);
";
using (var session = batch.OpenSession())
{
foreach (var item in batch.Items)
{
// mark the last index that we
// already observed using Patch
session.Advanced.Defer(
new PatchCommandData(
id: item.Id,
patch: new PatchRequest
{
Script = script,
Values =
{
["idx"] = item.Result.Comments.Count
}
},
patchIfMissing: null,
);
}
// actually escalate the call
session.SaveChanges();
}
});
We are simply setting the Last-Monitored-Index to the size of the Comments on the call and saving it back to the server. This will ensure that we'll only get the support call again if there are new comments with the words we're watching for. The code in Listing 5.9 is going out of its way to be a good
citizen and not go to the server any more times than it needs to. This is also a good chance to demonstrate a real use case for Defer in production code. The use of Defer means two things: one, we don't need to worry about the number of calls and, two, we've handled concurrency.
Maintaining per-document subscription state
Subscriptions often need to maintain some sort of state on a per-document basis. In the case of Listing 5.9, we needed to keep track of the last monitored index, but other times you'll have much more complex state to track. For example, imagine that we need to kick off a workflow that will escalate a call once it passes a certain threshold. We might need to keep track of the state of the workflow and have that be accounted for in the subscription itself.
Using the metadata to do this works quite nicely if we're talking about small and simple state. However, as the complexity grows, it isn't viable to keep all that in the document metadata, and we'll typically introduce a separate document to maintain the state of the subscription. In it, we'll track support calls, and
SupportCalls/238-Bwill have aSupportCalls/238-B/EscalationStatedocument that contains the relevant information for the subscription.
Listing 5.8 and Listing 5.9 together show us how a subscription can perform rather complex operations and open up some really interesting options for processing documents. But even so, we aren't done. We can do even more with subscriptions.
Complex scripts
We've used conditional subscriptions to filter the documents that we want to process, and since this filtering is happening on the server side, it allows us to reduce the number of documents that we have to send to the subscription. This is awesome in itself, but a really interesting feature of subscriptions is that we don't actually need to send the full documents to the client. We can select just the relevant details to send.
Say we want to do some processing on highly voted support calls. We don't need to get the full document; we just need the actual issue and the number of votes for that call. Instead of sending the full document over the wire, we can use the code in Listing 5.10 to achieve our goals more efficiently.
Listing 5.10 Getting just the relevant details in the subscription
var options = new SubscriptionCreationOptions
{
Name = subscriptionName,
Query = @"
from SupportCalls as call
where call.Votes >= 10
select {
Issue: call.Issue,
Votes: call.Votes
}"
};
store.Subscriptions.Create(options);
What we're doing in Listing 5.10 is filtering the support calls. If the call has less then 10 votes, we'll just filter it. However, we aren't limited to just filtering the full document. We can also return an object of our own. That object can be built by us and contain just what we want to send directly to the client, and RavenDB will send it.
But there is an issue here. In Listing 5.10, we're creating a subscription on SupportCall. However, the value that will be sent to the client for
the subscription to process is not a SupportCall document. It's a projection created during the subscription run. That means that, on the client side, we need to know
how to handle such a thing. This requires a bit of a change in how we open the subscription, as you can see in Listing 5.11.
Listing 5.11 Opening subscription with a different target
public class SupportCallSubscriptionOutput
{
public string Issue;
public int Votes;
}
var options = new SubscriptionWorkerOptions(subscriptionName);
var subscription = store.Subscriptions .GetSubscriptionWorker<SupportCallSubscriptionOutput>(options);
await subscription.Run(batch =>
{
foreach (var item in batch.Items)
{
SupportCallSubscriptionOutput result = item.Result;
// do something with the
// result.Issue, result.Votes
}
});
In order to consume the subscription in a type-safe way, we create a class that matches the output that we'll get from the subscription script, and we'll use that when we open the subscription. Scenarios like the one outlined in Listings 5.10 and 5.11 make this flexibility very useful.
If this was all we could do with the subscription script, it would have been a good way to reduce the amount of data that's sent over the wire. But there are actually more options available for us that we haven't gotten around to yet. Consider Listing 5.6. There, we get the support call and immediately have to load the associated customer. That can lead to a remote call per item in the batch. We've already gone over why this can be a bad idea in terms of overall performance. Even with the optimization we implemented in Listing 5.7, there's still a remote call to do. We can do better.
We can ask RavenDB to handle this as part of the subscription processing directly. Take a look at Listing 5.12, which does just that.
Listing 5.12 Getting just the relevant details in the subscription
var options = new SubscriptionCreationOptions<SupportCall>
{
Name = subscriptionName,
Query = @"
from SupportCalls as call
where call.Votes >= 10
load call.CustomerId as customer
select {
Issue: call.Issue,
Votes: call.Votes,
Customer: {
Name: customer.Name,
Email: customer.Email
}
}"
};
store.Subscriptions.Create(options);
In Listing 5.12, we're using load as part of the processing of the subscription on the server side. This allows us to get the customer instance
and send pieces of it back to the client. In order to consume it, we'll need to change the SupportCallSubscriptionOutput class that we introduced in
Listing 5.11 to add the new fields.
When processing the output of this subscription, we can directly process the results without making any other remote calls, not even to load the associated document. In Listing 5.13, you can see how we'd process such a subscription.
Listing 5.13 Opening subscription with a different target
public class SupportCallSubscriptionOutput
{
public class Customer
{
public string Name;
public string Email;
}
public string Issue;
public int Votes;
public Customer Customer;
}
var options = new SubscriptionWorkerOptions(subscriptionName);
var subscription = store.Subscriptions .GetSubscriptionWorker<SupportCallSubscriptionOutput>(options);
await subscription.Run(batch =>
{
foreach (var item in batch.Items)
{
SupportCallSubscriptionOutput result = item.Result;
SendEscalationEmail(result.Customer, item.Id);
// other stuff related to processing the call
}
});
You can see that we use an inner class to scope the meaning of the Customer here. This isn't required. It's merely a convention we use to bring some order
to the client-side types.
Error handling and recovery with subscriptions
What happens when there's an error in the processing of a document? Imagine that we had code inside the lambda in the Run method and that code threw an
exception. Unless you set SubscriptionWorkerOptions.IgnoreSubscriberErrors,5 we'll abort processing of the
subscription and the Run will raise an error. Typical handling in that scenario is to dispose the subscription and immediately open it again.
Assuming the error is transient, we'll start processing from the last batch we received and continue forward from there. If the error isn't transient — for example,
some NullReferenceException because of a null the code didn't check for — the error will repeat itself. You might want to set an upper limit to the number
of errors you'll try to recover from in a given time period, choosing to just fail completely afterward. This depends heavily on the kind of error reporting and
recovery you're using in your applications.
Note that this applies only to errors that come from the code processing the document. All other errors (connection to server, failover between servers, etc.)
are already handled by RavenDB. The reason that we abort the subscription in the case of subscriber error is that there really isn't any good way to recover
from it in a safe manner.
We don't want to skip processing the document. And just logging the error is possible (in fact, that's exactly what we do if IgnoreSubscriberErrors is set),
but no one ever reads the log until the problem is already discovered, which is typically very late in the game.
In other words, RavenDB will take care of all the issues related to talking to the database, but the error handling related to your code is on you. In
practice, you generally don't have to worry about it. An error thrown during document processing will kill your subscription. We saw in Listing 5.3 that after
we call Run, we need to wait on the resulting task. If an error is raised during document processing, the subscription will close and that
error will be raised to the caller of the Run method.
The typical manner in which you'll handle errors with subscriptions is to just retry the whole subscription, as shown in Listing 5.14. There's a lot of things going on in this listing, so take the time to carefully read through the error handling.
Listing 5.14 Retrying subscription on error
while (true)
{
var options = new SubscriptionWorkerOptions(subscriptionName);
// here we configure that we allow a down time of up to 2 hours
// and will wait for 2 minutes for reconnecting
options.MaxErroneousPeriod = TimeSpan.FromHours(2);
options.TimeToWaitBeforeConnectionRetry = TimeSpan.FromMinutes(2);
var subscriptionWorker = store.Subscriptions
.GetSubscriptionWorker<Order>(options);
try
{
// here we are able to be informed of any exception that happens during processing
subscriptionWorker.OnSubscriptionConnectionRetry += exception =>
{
Logger.Error("Error during subscription processing: " + subscriptionName, exception);
};
await subscriptionWorker.Run(async batch =>
{
foreach (var item in batch.Items)
{
// we want to force close the subscription processing in that case
// and let the external code decide what to do with that
if (item.Result.Company == "companies/832-A")
throw new UnsupportedCompanyException("Company Id can't be 'companies/832-A', you must fix this");
await ProcessOrder(item.Result);
}
}, cancellationToken);
// Run will complete normally if you have disposed the subscription
return;
}
catch (Exception e)
{
Logger.Error("Failure in subscription: " + subscriptionName, e);
if (e is DatabaseDoesNotExistException ||
e is SubscriptionDoesNotExistException ||
e is SubscriptionInvalidStateException ||
e is AuthorizationException)
throw; // not recoverable
if (e is SubscriptionClosedException)
// closed explicitly by admin, probably
return;
if (e is SubscriberErrorException se)
{
// for UnsupportedCompanyException type, we want to throw an exception, otherwise
// we continue processing
if (se.InnerException is UnsupportedCompanyException)
{
throw;
}
continue;
}
// handle this depending on subscription
// open strategy (discussed later)
if (e is SubscriptionInUseException)
continue;
return;
}
finally
{
subscriptionWorker.Dispose();
}
}
Listing 5.14 shows a typical way to handle errors in subscriptions. For completion's sake, I've included all the common error conditions that can be raised from
the Run method. The first few items involve non-recoverable scenarios. The database doesn't exist, the subscription doesn't exist or is misconfigured, or the
credentials we have are invalid. There's no way to recover from those kinds of errors without administrator involvement, so we should just raise this up the stack until we catch the attention of someone who can actually fix this.
The next part handles errors when the subscription was closed explicitly by an administrator. RavenDB will automatically recover from failures and accidental disconnects, but the administrator can also choose to explicitly kill a subscription connection. In this case, we'll report this to the caller, who can decide what to do about it. Simply retrying is probably not a good idea in this case. A subscription can also fail because another client is already holding onto it, or a client came in and kicked our subscription from the subscription. Both of these cases are strongly tied to the deployment mode you have and will be discussed in the next section.
What about subscription script errors?
We've talked plenty about what happens when there are errors on the server side (automatically recover), on the client side (thrown to caller and handled by your code) and the like. However, there's one class of errors that we didn't consider: what would happen if there's an error in the query that we use to evaluate each document?
Consider the following snippet:
select { Rate: (10 / call.Votes) }. It isn't meant to be meaningful, just to generate an error when theVotesproperty is set to zero. In this case, when evaluating the script on a support call with no votes, we'll get a error attempting to divide by zero. That error will be sent to the client and be part of the batch.When the client accesses the
item.Resultproperty on that particular document, the exception will be raised on the client side. In this way, you can select how to handle such errors. You can handle this on the client side in some manner and continue forward normally, or you can let it bubble up as an error in the subscription, which should trigger your error-handling policy, as we saw in Listing 5.14.
All other exceptions would typically be raised from within the batch processing code. A very simple error handling strategy can be to just try an error backoff for retries. So on the first error, you'll retry immediately, if there is still an error, wait for 5 seconds and try again. Keep adding 5 seconds to the sleep time until a certain maximum (such as 1 minute). In many cases, this is enough to handle transient errors without having to get an admin involved in the process.
Exactly how you'll handle error recovery in your system is up to you and the operations teams that will maintain the application in production, and it's tied very closely to how you're using subscriptions and deploying them.
Subscription deployment patterns
Talking about a single subscription in isolation helps us understand how it works, but we also need to consider how subscriptions are deployed and managed in your systems. Subscriptions are used to handle most batch processing needs in RavenDB, which puts them in an interesting place regarding their use. On the one hand, they're often performing critical business functions. But on the other hand, they aren't visible. (A failing subscription will not cause an error page to be shown to the user.)
Subscriptions are usually deployed in either a batch-and-stop mode or in a continuous run. The continuous run is a process (or a set of processes) that are running your subscriptions constantly. The database will feed any new data to them as soon as it's able, and all processing happens live. That isn't required, mind you. Under load, the administrator is perfectly able to shut down a subscription (or even all of them) to free up processing capacity. When they're started up again, they'll pick up where they left off.
In batch mode, the subscriptions are run on a schedule. When they run out of work to do, they'll shut themselves down until being run again. Listing 5.15 shows how you can write a self-stopping subscription.
Listing 5.15 Stop the subscription after 15 minutes of inactivity
var options = new SubscriptionWorkerOptions(subscriptionName)
{
CloseWhenNoDocsLeft = true
}
using (var subscription = store
.Subscriptions.GetSubscriptionWorker<SupportCall>(options))
{
await subscription.Run(batch =>
{
// process batches until we run out of docs
// that match the subscription
});
}
The CloseWhenNoDocsLeft option will cause RavenDB to abort the subscription if there are no documents to send. This is useful for processes that start, run
through everything that happened since their last run and then shut down again.
Another aspect of subscription deployment is the notion of high availability. On the server side, the cluster will ensure that if there was a failure, we will transparently failover to another node. But who takes care of high availability on the client? Typically you'll want to have at least a couple of machines running subscriptions, so if one of them goes down, the other one will carry on. However, if the same subscription is running concurrently on two machines, that can lead to duplicate processing. Now, your code needs to handle that anyway, since subscriptions guarantee processing at least once and various error conditions can cause a batch to be re-sent. However, there's a major difference between handling that once in a blue moon and having to deal with it constantly, leaving aside the issue that we'll also have higher resource usage because we need to process the subscription on multiple nodes.
Luckily, RavenDB subscriptions don't work like that. Instead, a subscription is always opened by one and only one client. By default, if two clients
attempt to open the same subscription, one of them will succeed and the other one will raise an error because it couldn't take hold of the subscription.
This is controlled by the SubscriptionOpeningStrategy option set on the Strategy property. The various options of this property are:
OpenIfFree— the default. The client will attempt to open the subscription but will fail if another client is already holding it. This is suitable in cases where you're running subscriptions in batch/schedule mode. If another client is already processing it, there's no need to process anything yourself.TakeOver— the client will attempt to open the subscription even if a client is already connected to it. If there's a connected client, its connection will be closed. This is used to force the subscription open operation to succeed for a particular client. If an incoming subscription tries to take over an existing one, which also has a "take over" strategy, the incoming subscription will "loose" the contest.WaitForFree— the client will attempt to open the subscription, but if there's already a connected client, it will keep trying to acquire the connection. This is suitable for high availability mode, when you have multiple clients attempting to acquire the same subscription and you want one of them to succeed while the rest stand ready in case that one fails.
For high availability processing on the client, you'll set up multiple machines that will run your subscriptions and open them using the WaitForFree option.
In this way, those clients will compete for the subscriptions. If one of them fails, the other will take over and continue processing them. The use of multiple machines
for handling subscriptions also allows you to split your processing between the machines.
Failure conditions in a distributed environment
Failure handling in a distributed environment is hard. When both clients and servers are distributed, this makes for some really interesting failure modes. In particular, while we promise that a subscription will only be opened by a single client at a time, it's possible for the network to split in such a way that two clients have successfully connected to two different servers and are trying to process the same subscription from them.
That scenario should be rare, and it will only last for the duration of a single batch, until the next synchronization point for the subscription (which ensures global consistency for the subscription). One of those servers will fail to process the batch acknowledgement and return that error to the client, eventually aborting the connection.
You may decide that you want certain operations to be handled on one worker node6 and configure those subscriptions to TakeOver on that worker node and WaitForFree
on any other worker nodes. This way, a particular subscription has a preferred worker node that it will run on, but if that one fails, it will run on another.
In other words, each worker node will run only its own preferred subscriptions unless there's a failure.
When your deployment contains multiple worker nodes that are all processing subscriptions, you need to be even more aware of the fact that you're running in a distributed system and that concurrency in a distributed environment should always be a consideration. We already talked about optimistic concurrency in Chapter 4, but with distributed databases, we also need to take into account eventual consistency and conflicts between machines. We'll start talking about the distributed nature of RavenDB in Chapter 6 in depth.
For subscriptions, we typically don't care about this. The batch processing mode means that we already see the world differently and it doesn't matter if we get a document in a particular batch or in the next. One thing to be aware of is that different subscriptions may be running on different nodes and thus getting the documents in a different order. (All of them will end up getting all the documents. There's just no guaranteed absolute order across the distributed system.)
Using subscription for queuing tasks
In this section, I want to utilize subscriptions as a processing queue for a few reasons. For one thing, it's a very common scenario for using subscriptions. For another, it lets us explore a lot of the RavenDB functionality and how different pieces are held together. What we want to do is to be able to write an operation to the database and, when we've successfully processed it, automatically delete it.
Going back to the email-sending example, our code will write EmailToSend documents that will be picked up by a subscription and handled. The code for
actually doing this is shown in Listing 5.16.
Listing 5.16 Delete the emails to send after successful send
using (var subscription =
store.Subscriptions.GetSubscriptionWorker<EmailToSend>(options))
{
await subscription.Run(async batch =>
{
using (var session = batch.OpenAsyncSession())
{
foreach (var item in batch.Items)
{
try
{
SendEmail(item.Document);
}
catch
{
// logging / warning / etc
continue;
}
session.Delete(item.Id);
}
await session.SaveChangesAsync();
}
});
}
There's actually a lot going on in Listing 5.16 that may not be obvious. First, we're processing a batch of documents, trying to send each one in turn. If there's an error in sending one of those emails, we'll skip further processing.
However, if we were able to successfully send the email, we'll register the document to be deleted. At the end of the batch, we'll delete all the documents
that we've successfully sent. However, we won't touch the documents that we didn't send. The idea is to dedicate the EmailToSend collection for this
task only. That means that in the EmailToSend collection, we'll only ever have one of two types of documents:
EmailToSenddocuments that haven't been processed yet by the subscription and will be sent (and deleted) soon.- Documents that we tried to send but failed to.
Those documents that we fail to send are interesting. Since the subscription has already processed them, we won't be seeing them again. However, we
didn't lose any data, and an administrator can compare the current state of the subscription to the state of the EmailToSend collection and get all the
failed documents.
At that point, the admin can either fix whatever is wrong with those documents (which will cause them to be sent to the subscription again) or they can reset the position of the subscription and have it reprocess all those documents again (for example, if there was some environmental problem). This mode of operation is really nice for processing queues. For simple cases, you can just rely on RavenDB to do it all for you. In fact, given that RavenDB subscriptions can work with failover of both clients and servers, this gives you a robust solution to handle task queues that are local to your application.
One thing to note — RavenDB isn't a queuing solution, and this code doesn't pretend that it is. The code in Listing 5.16 is a great way to handle task queues, but proper queuing systems will offer additional features (like monitoring and built-in error handling) that you might want to consider. For most simple tasks, the fire-and-forget operations, you can use RavenDB in this mode. But for more complex situations, you should at least explore whether a proper queue can offer a better solution.
Versioned subscriptions
The subscriptions we've used so far are always operating on the current state of the document. Consider the following case:
- You create a subscription on the
Customercollection. - You create a customer document and modify it three times.
- You open and run the subscription and observe the incoming items in the batch.
What will the subscription get? It will get the last version of the customer document. The same can happen when the subscription is already running. If you've made multiple modifications to a document, when the next batch starts, we'll just grab the current version of the document and send it to the subscription. This can be a problem if your subscription code assumes that you'll always get the document every time it changes.
The good news is that we can utilize another RavenDB feature, revisions (discussed in Chapter 4), to allow us to see all the changes that were made to a document.
The first step to exploring this feature is to enable revisions on the collection you want. In this case, it's the Customers collection. Set the minimum retention
time for two weeks, and again make a few modifications to a customer document. When you run your subscription once more, note that you're again getting
just the latest version of the Customer document.
The reason you only get the latest version of the document is that the subscription, too, needs to let the server know that it's versioned. This is because the data model for versioned subscriptions is different. Let's take a look at Listing 5.17 for an example of a simple versioned subscription that can detect when a customer changed their name.
Listing 5.17 Subscribing to versioned customers
store.Subscriptions.Create<Revision<Customer>>(
new SubscriptionCreationOptions
{
Name = subscriptionName,
}
);
using (var subscription = store.Subscriptions
.GetSubscriptionWorker<Revision<Customer>>(
subscriptionName
))
{
await subscription.Run(batch =>
{
foreach (var item in batch.Items)
{
Revision<Customer> customer = item.Result;
if (customer.Previous.Name !=
customer.Current.Name)
{
// report customer name change
}
}
});
}
The key parts to the code in Listing 5.17 is the use of Revision<Customer> as the type that we're subscribing on. RavenDB recognizes that as a versioned
subscription and will feed us each and every revision for the Customer collection.
Note that the data model as well has changed. Instead of getting the document itself, we get an object that has Previous and Current properties,
representing the changes that happened to the document. In other words, you're able to inspect the current and previous versions and make decisions
based on the changes that happened to the entity.
This feature opens up a lot of options regarding analytics because you aren't seeing just a snapshot of the state but all the intermediate steps along the way. This has uses in business analytics, fraud, outliers detection and forensics, in addition to the general benefit of being able to reconstruct the flow of data through your system. The way versioned subscriptions work, we're going to get all the changes that match our criteria, in the same order they happened in the database.7
If I wrote to customers/8243-C, created a new customers/13252-B and then wrote to customers/8243-C again, I'll get the changes (either in a single batch
or across batches) in the following order:
customers/8243-C— (Previous->Current)customers/13252-B— (null->Current)customers/8243-C— (Previous->Current)
This can be useful when running forensics or just when you want to inspect what's going on in your system.
Handling revisioned document creation and deletion
When a new document is created, we'll get it in the versioned subscription with the
Previousproperty set tonulland theCurrentset to the newly created version. Conversely, if the document is deleted, we'll get it with theCurrentset tonulland thePreviousset to the last version of the document.If a document is deleted and recreated, we'll have one entry with (
Previous,null) and then another with (null,Current). This feature is also useful if you just want to detect the deletion of documents in a subscription.
Just like regular subscriptions, we aren't limited to just getting all the data from the server. We can filter it, as you can see in Listing 5.18.
Listing 5.18 Setting filters on a versioned subscription
store.Subscriptions.Create(
new SubscriptionCreationOptions
{
Name = subscriptionName,
Query = @"
from Customers (Revisions = true)
where Prervious.Name != Current.Name"
}
);
The code in Listing 5.18 will only send you the Customer documents whose names have been changed. The rest of the code in Listing 5.17 can remain the same,
but we now don't need to check if the names have changed on the client side. We've done that already on the server.
A natural extension of this behavior is to not send the full data to the client but just the data we need. An example of this can be shown in Listing 5.19.
Listing 5.19 Getting changed names using versioned subscription
store.Subscriptions.Create(
new SubscriptionCreationOptions<Versioned<Customer>>
{
Name = subscriptionName,
Query = @"
from Customers (Revisions = true)
where Prervious.Name != Current.Name
select {
OldName: this.Previous.Name,
NewName: this.Current.Name
}"
}
);
The code in Listing 5.19 isn't that interesting except for what it's actually doing. It's filtering the data on the server side and only sending us the old and new names. The subscription handling code on the client side just needs to take the old name and new name and notify whoever needs to know about the name change.
Versioned subscriptions give you a lot of power to work with your data (and the changes in your data) in an easy way. The ability is of particular interest in reversed event sourcing because you can go over your data, detect a pattern that matches a particular event you want to raise and publish it.
Versioned subscriptions use the document revisions
This might be an obvious statement, but it needs to be explicitly said. The backing store for the versioned subscription is all the revisions that are stored for the documents as they're changed. That means that it's important to know the minimum retention time that's been configured. If you have a weekly subscription run and the versioning is configured to keep data for a day, you're going to miss out on revisions that have already been deleted.
So when using a versioned subscription, the administrator must verify that the revisions retention time matches the subscription run time.
Subscriptions, background jobs and the role of the admin
Systems typically accrue additional behavior over time. As business processes mature and evolve, so does the demand on our systems. The way we've talked about subscriptions so far is mainly as a core part of the application itself — something that the developers would write, build and manage. But that doesn't have to be the case. In fact, it's common for subscriptions to be used as "aftermarket" entry points for modifying, extending and supporting the system.
Consider the case of wanting to send all new users a welcome email after they've registered. We could do that as part of the application itself, but given that this is a self-contained feature, we don't actually have to involve the developers. We can write a subscription that would monitor new customers and send them the email.
For flexibility, we don't want to write it in C#. We don't need an application. We just need to be able to run a script to process those documents. I'm using the Python client API in Listing 5.20 to perform this task. (I could have used node.js, Ruby, etc. I'm using Python as the example here because it's a great scripting language, and one I'm very fond of.)
Listing 5.20 Sending welcome emails to new customers
##!/usr/bin/env python3
from pyravendb import RavenDB
def process_batch(batch):
with batch.open_session() as session:
for item in batch.items:
customer = item.result
if customer.WelcomeEmailSent:
continue
send_welcome_email(customer);
customer.WelcomeEmailSent = True
session.store(customer)
session.save_changes()
store = document_store (
urls = ["http://rvn-srv-2:8080"],
database = "HelpDesk"
)
store.initialize()
with store.Subscriptions.GetSubscriptionWorker(
subscription_connection_options(
id = "new-customers-welcome-email"
)) as subscription:
subscription.run(process_batch).join()
The code is quite similar to the way we would do things in C#. We open a document store, open the subscription and pass a method to process the document batches. The use of Python typically means shorter development time and more freedom for the operations team to modify things. That can be a great thing or a horrible thing.
Subscription in a dynamic language
A major advantage of writing such scripts in a dynamic language is the low overhead and friction. We don't need to define classes. We can just use the shape of the data as it came down the wire. That makes everything simpler.
On the other hand, you need to be aware that doing so requires discipline. You must be sure to version your subscription's code in step with the rest of the code.
Subscriptions, even if they're written in another platform, are still considered to be a part of your system. RavenDB is meant to be an application database, not a shared database between a multitude of applications using the same data. Even if there are additional processes going on, they should be (eventually, at least) all owned by the application itself.
The beauty in using a scripting language for those kind of tasks is that it allows you to simply set up a subscription without any sort of application, compilation, etc. A single script per business process is usually enough. Since those are background batch processes, it doesn't usually matter if the language isn't very fast. You can trade off convenience for speed in this case with a clear conscience.
One thing that isn't in Listing 5.20 is error handling. In previous examples in this chapter, I spent some time discussing error handling, and any subscription scripts you have most certainly do need to have something there. But a conscientious admin will have already set up a watchdog for this, reporting errors and raising alerts accordingly. Any production system is made of a lot of moving parts. Most likely that the infrastructure to manage such scripts, restart them if there is an error and alert you if they haven't recovered is already in place.
I'm mentioning this because it's important that it is in place. The nasty side of this kind of approach is that it's easy for what would turn out to be a critical business process to be developed in a completely "Shadow IT" approach; that is, this subscription is running on some server somewhere and will continue to do so until a reboot is done, where stuff breaks and no one really knows what.
Summary
When RavenDB implemented subscriptions for the first time, it was just a small section: a minor feature that was meant to handle an esoteric scenario that only a single customer had run into. From that modest beginning, this feature has blown up to completely replace most batch processing handling in RavenDB. It's not the first thing you'll use in every situation, but for anything that isn't about responding to a user request, it's usually a match.
In this chapter, we looked into what subscriptions are, how to do batch processes with RavenDB and subscriptions, how to filter and modify the data on the server and how to accept and process the data on the client side and write it back to RavenDB in an optimal fashion. We looked at integrating with external systems via the email-sending example, including how to handle failures and partial failures both in RavenDB and in the external systems.
Using subscription for ETL work
It's tempting to use subscriptions to handle ETL8 tasks, such as writing to a reporting database. While it is possible, RavenDB has better options to handle ETL. See the discussion on this topic in Chapter 8.
We spent a lot of time discussing how to handle errors in subscriptions, how to deploy subscriptions into production and how we can ensure failover and load balancing of the work among both client and server using subscriptions. The subscription open strategies allow us to have a hot standby client for a subscription, ready to take over from a failed node and continue processing. On the server side, RavenDB will automatically failover subscriptions from a failed database node to a healthy one in a completely transparent manner.
Another great use case for subscriptions is implementing task queues. And we looked at that, including error handling and recovery. We also discussed the ability to fix an issue with a document that failed and have it automatically reprocessed by the subscription.
We then looked at versioned subscriptions, where we ask RavenDB to give us a before-and-after snapshot of each and every change for the documents we care about. This is a great help when producing timelines, tracking changes and handling forensics. This feature relies on the revisions configuration on the database and exposes it directly for batch processing needs. We can even write a subscription script that would filter and send just the relevant details from both old and new revisions of the document to the client side.
The next part of the book is going to be exciting. We're going to learn how RavenDB is working in a distributed environment, and we can finally figure out what all those cryptic references to working in a cluster mean.
-
Although errors may cause you to receive the same document multiple times, you're guaranteed to never miss a document.↩
-
This particular lecture was over a decade ago, but I still vividly remember it. It was that good.↩
-
There's also the three-phase commit, which just adds to the fun and doesn't actually solve the issue.↩
-
Remember, that budget is configurable, but it's mostly there to help you realize that generating so many requests is probably not healthy for you.↩
-
And you probably shouldn't do that.↩
-
I'm using the term worker node here to refer to machines that are running business processes, subscriptions, etc. This is to distinguish them from RavenDB nodes.↩
-
Again, different nodes may have observed the events in a different order, but it should roughly match across the cluster.↩
-
Extract, transform, load — the process of moving data around between different data storage systems.↩
