 Skip to Navigation
Skip to Navigation
AI in Microservices Architecture: How to Streamline DevOps and Performance

CLSTRLobe DevOps chooses RavenDB for agile development in a microservices IoT deployment with over 80 databases. RavenDB provides flexibility, ease of duplicating databases, and use of data subscriptions for event sourcing in an AI application for agriculture.
Data analysis is usually handled by SQL databases, with OLAP offering impressive functionality. Where these databases suffer is in the lack of agility in developing and handling data from various sources in a microservices architecture. They can do it, but it means using new architectural approaches with a data structure that is designed for traditional approaches. Spinning up new databases and mapping the objects to tables for them in a complex system is very tedious.
Kreso Jurisic from CLSTRLobe has loved working with RavenDB for years and decided that it is the ideal data platform for their new DDD-based AI/IoT solution for farm insights. He designed this complex system using RavenDB to import and prepare the data, then export it to their relational database for CLSTRLobe’s data analysts.
Table of contents
What did they use before RavenDB?
They started the project in a relational database, but have been transitioning to RavenDB because of how easy it is to spawn a needed database for a single service. The utilization of RavenDB’s built-in data subscriptions makes it easy to propagate information around via event sourcing.
RavenDB’s indexes can be used efficiently with machine learning models. An ML model can be trained and inserted into the RavenDB index definition to process and run computations on data as it comes in. What would otherwise be costly, slow multiple-table queries in relational databases are much more efficient with RavenDB indexes. The indexes do most of the work for the queries incrementally behind the scenes. Queries are frequent, so when their workload is light, RavenDB can significantly reduce latency, especially on complex queries.
Why CLSTRLobe prefers RavenDB
Fast release cycles
RavenDB is designed to give developers and architects the flexibility and freedom to respond quickly to the demands of a constantly changing environment. At the same time, RavenDB provides exceptional efficiency and ACID guarantees by default to prevent data corruption.
RavenDB is very flexible. If the structure needs to adapt, RavenDB allows these changes without requiring much work. Relational databases require so much work to start or change a database that they discourage responsiveness to new opportunities and needs.
CLSTRLobe uses a multi-tenant microservices architecture with event sourcing where every microservice has its own RavenDB database. This means creating lots of databases. RavenDB makes it quick and easy to create, do in-memory tests, and deploy databases.
Testing in RavenDB is simplified with in-memory embedded servers designed to save time on integrated and unit tests. Data won’t be persisted. This lets you set up tests, perform them, and do it as often as you need quickly and efficiently without having to clean up and reset the data after every test.
Event sourcing with data subscriptions
Events are stored in one database whenever data is added, changed, or deleted. Then every micro-service has a “subscription worker” to consume the events that are relevant to the service for event sourcing. RavenDB’s data subscription feature can be used for the similar functionality of a robust message handling system or service bus. The events handled by a subscription can be sent to multiple services concurrently when various services need the same information.
Cost and time savings
Spinning up a new database is a simple operation in RavenDB. When creating a new database, you configure if it should be encrypted, which nodes it will live on (we recommend at least 3 for instant failover and Raft concensus). You can also quickly create a database from a backup of your choice, which means that it will already have the data, indexes, and ongoing tasks of the database that was backed up. This is useful when starting a new release cycle based on your existing data and code. After creating from a backup, all you need to do is add nodes to the database group for instant failover and you can start developing in an environment that mimics production.
CLSTRLobe has dozens of databases (currently 84). The developer time that they would spend to start and maintain them in each release cycle would be much more costly with other data platforms, especially relational DBs.
With RavenDB, you don’t need to do Object-Relational Mapping. The database can save objects whole, so there’s no need to spend valuable development time mapping objects to tables and then re-assembling them in queries. This constant translation costs developer time and latency. On the other hand, the organization needed for fast, complex querying is done by RavenDB’s indexes behind the scenes.
No additional persistence layer is needed as RavenDB can store whole entities and serialize them into JSON format.
CLSTRLobe uses RavenDB as a logging solution instead of Elasticsearch because RavenDB has all of the needed functionality. Less external components means less bugs to deal with.
High-performance
RavenDB improves performance by batching multiple jobs into every trip to the server. On the surface it seems like running to the server for every operation is the fastest approach, but it’s like going to the grocery store and back for each item, instead of batching the items into a bag. You’d wind up taking more time and working harder. When the pace of transactions means 1000 or 1,000,000 operations per second your users won’t feel a delay, but you’ll see a substantial improvement in performance and cost efficiency.
Lazy loads batch loads together and make the trip to the server as soon as a value is needed. This reduces trips to the server and improves efficiency.
Also, RavenDB handles data from related documents efficiently by loading all needed documents in one trip to the server with the Include() method.
Organizes and aggregates data from various sources
CLSTRLobe collects data from various endpoints every hour. The data science team needs it every day. So they use RavenDB subscriptions and run a script on the data to get the day-by-day averages from all tenants that are synced through ETLs to SQL Server for their Data Science team. In this way, they efficiently achieve CQRS – Command/Query Responsibility Separation.
High Availability means stability even when servers go down
Whenever the preferred node goes down, other RavenDB nodes in the database group automatically, instantly, and seamlessly take over the downed server’s operations and update it with the latest data when it is back online. The application doesn’t notice anything, and the only thing the database admin might see is a slow-down while the cluster is bringing the now online node up to date. With zero downtime, RavenDB has proven to be more stable than other leading databases in chaos tests.
Reliable and fast ACID transactions
NoSQL databases are not known for fast ACID transactions, but RavenDB has been ACID from the start. At over 1M reads per second and 150K writes per second, its performance is not sacrificed for data integrity. Data transfers are ACID by default on the preferred node, which is responsible for all reads and writes by default. This approach makes it much easier to prevent data corruption. RavenDB can even handle 20,000 ACID requests per second on Raspberry Pi, making it ideal for edge deployments.
Also, the client-side cache is invalidated inexpensively by default with an etag check or kept valid in real time with Aggressive Caching so that queries are also accurate without having to run to the server. The only time when a query might have stale data is if the document was just changed and the index, which updates incrementally, hasn’t had a chance to catch up. If you anticipate situations like this, there are methods such as WaitForNonStaleResults() that postpone the query until the index has caught up, or like relational databases, waiting for indexes to catch up as part of session transactions.
Scaling the database as their need grows
RavenDB on-premise servers are designed for high performance and cost-effectiveness on various types of hardware, from ARM or Raspberry Pi to high-end servers. This means that when you need to scale out, your new hardware expenses won’t break the bank. On RavenDB Cloud, you can scale up with a few mouse clicks, then scale down as needed. Also, scaling out one distributed cluster or setting up an integrated set of global clusters is easier than you imagine.
Feature-rich – most of what they need is native to RavenDB
CLSTRLobe doesn’t need to maintain various 3rd party integrations because RavenDB has been listening to its customers and developed these features over the years.
- Attachments – Some of their edge devices send images. Information collected about these images can be indexed and used for machine learning.
- Spatial search – Information can be organized and queried by location.
- Time-series – Data can be tracked according to date/time and plotted onto graphs.
- SQL ETL – Data that is relevant for analysts is synced to their SQL Server because some of their data analysts are more familiar with it. The source data can be cleaned and otherwise transformed via javascript before being loaded into the destination database without changing the source data.
Difficulties they had with RavenDB and how they solved them
They have several Kubernetes clusters that push high amounts of logs to RavenDB. The database that was set up to receive these logs is already over 100GB and is expected to grow. Processing all of this data has recently caused RavenDB writes to slow down. They are considering setting up a separate server to receive logs so it won’t affect their main app database.
What they’d like new users to know
RavenDB is a perfect match when trying to follow DDD principles. Every service and microservice acts as its own bounding context with its own database. This makes it easy to fit each database to the unique needs of each sub-domain and its microservice. All services create events in one common database and are subscribed to some events from that same database based on their need. RavenDB is ACID by default within each server, while BASE in distributed systems, but each service has its own collection of fired events that are part of the transaction. To maintain data integrity, one job regularly checks and cleans events that have not been saved in the main event database (though that hasn’t happened yet).
RavenDB prevents replication conflicts and maintains ACID behavior by assigning reads and writes to the “preferred node” in each database group by default. Load balance behavior for reads can be configured so that queries can access other nodes, though changing RavenDB’s default ACID behavior for reads and writes will set your system to BASE behavior. Changing the default behavior for writes is not recommended as this can create frequent conflicts. For strong consistency and the ability for each node to write, cluster-wide transactions are available, though their Raft consensus checks will slow them down.
About CLSTRLobe
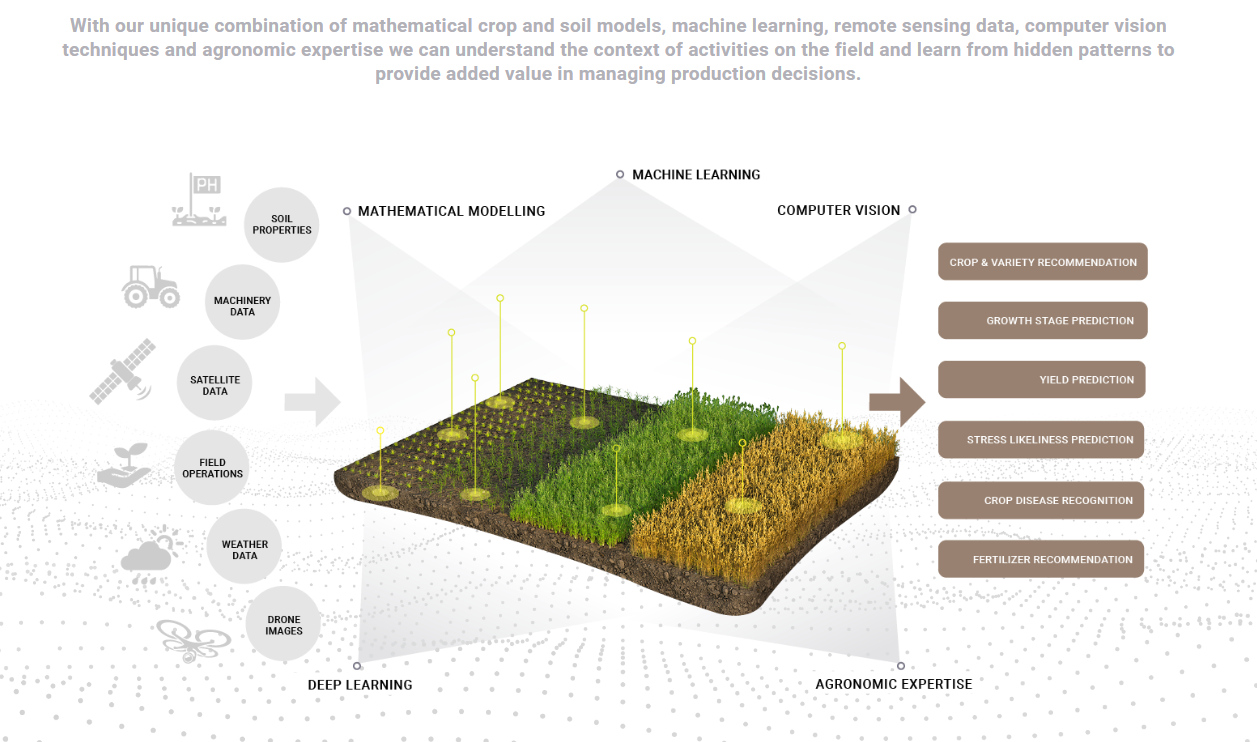
CLSTRLobe is a data analysis platform that collects data from various sources, such as IoT agricultural sensors, satellites, and drones. They then organize and distill the information to bolster data-based decision-making based on AI predictions. Their solution provides insights into the agricultural sector, taking into account agronomic expertise, weather patterns, soil conditions, and information imported from satellites, drones, and farm machinery.
Tech stack: They use a microservices architecture with one RavenDB database for event sourcing and one database per tenant per microservice in the Kubernetes container platform. Microservices are written in C#, while AI/ML functionality is written in Python and exposed over REST API. Additionally, an operator is written in Go for interacting with Kubernetes through the API. They use an on-premise Linux cluster of three RavenDB nodes for the main infrastructure and push specified data via RavenDB SQL ETL to a relational database for their data analysts.
Woah, already finished? 🤯
If you found the article interesting, don’t miss a chance to try our database solution – totally for free!



