
Entity Relationships in NoSQL (one-to-many, many-to-many)
We know how to maintain a relationship between two tables in SQL. Normalise. Add a reference field with a foreign key. When querying data from both tables – JOIN the two.
It makes writing normalised records to the DB straightforward and optimises storage space, but it comes with a higher cost of querying the data. All the JOINs and GROUP BYs on a normalised DB are hammering the disk (on random seeks, table scans, etc.) and RAM with the CPU (on finding matching rows, especially in hash join).
Considering that querying data is the most often operation against the DB, denormalisation (and NoSQL in general) can be a more attractive option to speed up the queries. Though, it may require more analysis before creating entities and aggregates. The recommended steps are:
- Learn the domain and document all workflows.
- Understand every access pattern: read/write patterns; query dimensions and aggregations.
- Design the Data Model, which is tuned to the discovered access patterns.
- Review -> Repeat -> Review, as it’s unlikely to get it right on the first attempt.
Designing aggregates is a huge topic and a previous article of the YABT series “NoSQL Data Model through the DDD prism” might be a good start. But here we focus on organising relationships between aggregates.
As a starting point, let’s take an “one-to-many” relationship between 3 entities of the YABT project: Backlog Item, Comment and User. The traditional relational diagram for them would look like this:
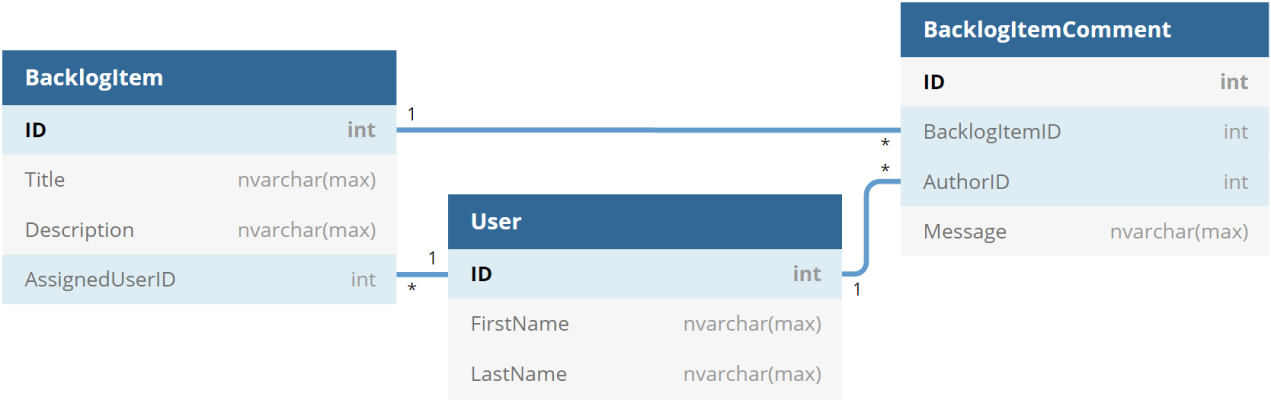
What are the options for these relationships in NoSQL in general and RavenDB in particular?
1. Embedded collection
Perhaps, the simplest approach would be keeping the referred entities as an embedded collection on the main one.
A classic example would be a collection of addresses, phones or emails for a user:
{
"fullName": "Homer Simpson",
"addresses" : [
{ "street": "742 Evergreen Terrace", "city": "Springfield", "state": "Nevada", "country": "USA" },
{ "street": "430 Spalding Way", "city": "Springfield", "state": "Nevada", "country": "USA" }
],
"emails" : [
"chunkylover53@aol.com",
"homer@gmail.com"
],
}
When to use?
- Items from the embedded collection are not referred anywhere independently from the main collection.
E.g. all other entities and aggregates would refer to the users rather than to just their addresses. - The embedded collection is not queried independently from the main one.
E.g. we won’t query phones only without mentioning users. - The embedded collection doesn’t grow without bound.
E.g. there is going to be just a handful of addresses per user.
Perhaps, the number of embedded records should remain as less than a hundred for most of the cases. Of course, a hundred is an arbitrary number, but the idea is to avoid performance deterioration on the aggregate caused by heavy nested collections.
How it’s used in YABT
This approach would work like a charm for BacklogItem and BacklogItemComment. Assuming that most of the tickets have a handful of comments and the comments aren’t referred or queried outside of the parent entity.
So a BacklogItem record with nested comments would look like:
{
"title": "Malfunction at the Springfield Nuclear Power Plant",
"comments": [
{
"timestamp": "2020-01-01T10:15:23",
"message": "Homer, what have you done?"
},
{
"timestamp": "2020-01-01T11:05:10",
"message": "Nothing, just left my donuts on the big red button."
}
]
}
Of course, it wouldn’t be a good solution if the comments didn’t meet the three conditions described above or simply tended to have bulky messages with KBs or MBs of text. Currently, backlog items in the YABT have 3 comments on average with length around 150 symbols. We consider it small enough and keep comments as an embedded collection in BacklogItem.
2. Reference by ID
The traditional SQL approach of referring records would still work. You can have the main entity/collection with an ID value of the referred record that’s stored in a separate entity/collection.
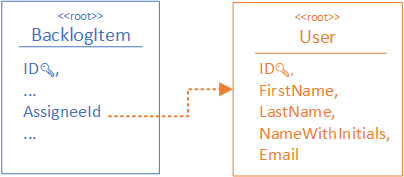
Well, what about all the benefits of denormalisation? Speaking for NoSQL in general, there are none and on querying you’ll run expensive JOINs to bring properties from the referred entity (some NoSQL servers support such operations on the server side, others would require an application level JOIN).
However, RavenDB has a trick up its sleeves (or wings) – storing often used fields of the referred entity right in the index, so you won’t need to JOIN the other collection for fetching those fields. Check out the official docs.
When to use?
- The collection is referenced in more than one place.
E.g. YABT users are referenced in the backlog items, comments, project, etc. - The referenced records get often updated. In this case, denormalisation would cause too much of a burden to find and update all the instances of the modified record.
Of course, it all depends on what fields would be duplicated in a denormalised database. ForUserentity it can be just a form of the name (e.g.NameWithInitials) in addition to theID. Whether updating the user names is an often operation that’s up for debate. If it’s the case, thenUserwould be a good candidate forIDreferences.
How it could be used in YABT
For our bug-tracker, we often want to show user names along with other records. For example, a list of backlog items might have 3 columns for referenced users. Hmm… 3 references would be a stretch but bear with me.

In this case running a triple JOIN on User entity would be excruciating. Fortunately, an option to store data in RavenDB indexes comes in handy.
For an index like this:
public class BacklogItems_ForList : AbstractIndexCreationTask<BacklogItem>
{
public BacklogItems_ForLists()
{
Map = tickets =>
from ticket in tickets
let assignee = LoadDocument<User>(ticket.AssigneeId)
let modifiedBy = LoadDocument<User>(ticket.ModifiedById)
let createdBy = LoadDocument<User>(ticket.CreatedById)
select new
{
Id = ticket.Id,
Title = ticket.Title,
AssigneeName = assignee.NameWithInitials,
CreatedByName = createdBy.NameWithInitials,
ModifiedByName = modifiedBy.NameWithInitials,
};
Stores.Add(x => x.AssigneeName, FieldStorage.Yes); // Stores names of 'Assignee'
Stores.Add(x => x.CreatedByName, FieldStorage.Yes); // Stores names of 'CreatedBy'
Stores.Add(x => x.ModifiedByName, FieldStorage.Yes); // Stores names of 'ModifiedBy'
}
}
All the name changes of the users will be picked up by RavenDB and stored in the index. That let us querying a backlog list with no JOINs, as we can refer the index fields along with the main entity:
from b in session.Query<BacklogItems_ForList>
select new { b.Id, b.Title, b.AssigneeName, b.CreatedByName, b.ModifiedByName }
Costs of storing in index
The index size gets slightly bigger, but the main downside is that the index gets rebuilt on each change in the User collection that would consume extra provisioned throughput in the cloud.
3. Duplicating often used fields
The read/write ratio plays a significant role in forming denormalised entities and aggregates. When reads overweight writes, you may consider another approach – duplicating some fields of the referred entity in other aggregates.
Let’s have another look at the Backlog list. This time a more realistic view that shows names of assigned users.

When to use?
- Read patterns for one collection require a small non-varying set of fields from another collection.
As per screenshot above, the backlog view in YABT shows names of assigned users along with the backlog item fields. It’s one of the most common requests in the app. The user reference is standard –IDandName(in a chosen form). We don’t expect this field set to vary when querying the backlog (e.g. not bringing other fields like emails to some views). - The referenced records DON’T get updated often.
Analysis of access patterns for YABT showed that changing user’s name is a seldom operation. - A delay on updating the duplicated values is acceptable.
Eventual consistency helps to reduce operational costs of the database. Hence, it’s greatly encouraged. In case of YABT, it’s not an issue if propagating a name change takes a couple of seconds.
In addition, there can be a combination of smaller contributing factors swinging you towards data duplication vs referencing users by ID:
- A requirement to bring the field set from another entity two more than one index. It would amplify the downsides of referencing by ID.
- Often requests to the items by ID that can’t leverage stored fields in the index.
How it’s used in YABT
To optimise the query for a list of backlog items, we duplicate user’s names in the BacklogItem aggregate. This way all the data in the backlog view is coming from the BacklogItem collection.
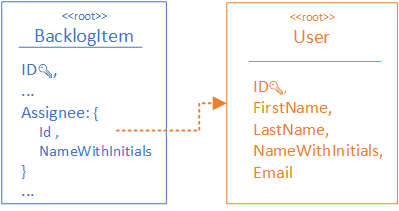
It’s a clear win on the read side. But what about keeping the duplicated values in sync with the corresponding User records?
Propagating the change to other collections
Now to the interesting part. A user has changed the name (a rare event, but we still account for that) and it’s a dev’s responsibility to apply the change to all the backlog items where the user is the assignee, so the data becomes eventually consistent. The implementation would heavily depend on the type of NoSQL server you’re dealing with.
In RavenDB, you would
- Persist the changes in the
Userrecord (e.g. by callingIAsyncDocumentSession.SaveChangesAsync()). - Run a Set Based Operation on the
BacklogItemcollection updating theAssigneefields where applicable.
The key features of Set Based Operation include:
- allows you to run a logic what changes records entirely on the RavenDB server-side;
- waiting till completion of the operation is optional (and if waiting, you get some handy stats at the end);
- can wait till the index catches up when the patching query is based on an index.
In our example it will be updated by a static index:
public class BacklogItems_ForList : AbstractIndexCreationTask<BacklogItem>
{
public BacklogItems_ForList()
{
Map = tickets =>
select new
{
...
AssignedUserId = ticket.Assignee.Id, // the ID of the assigned user
...
};
}
}
So to update the references to
var newUserReference = new { Id: "users/1-A", Name: "H. Simpson" };
the operation will look like
var operation = store
.Operations
.Send(new PatchByQueryOperation(new IndexQuery
{
Query = @"from index 'BacklogItems/ForList' as i
where i.AssignedUserId == $userId
update
{
i.Assignee = $userRef;
}",
QueryParameters = new Parameters
{
{ "userId", newUserReference.Id },
{ "userRef", newUserReference },
}
})
);
Downsides
- RavenDB doesn’t do concurrency checks during the operation so if during the run a backlog item has changed the assignee, then the its ID and name might be overwritten.
It can be mitigated by checking additional conditions before modifying a record (e.g. a timestamp of last modification). - The logic inside the operation can leverage JavaScript and be very powerful that also might lead to a run-time error. If you don’t wait on completion of the operation, then you don’t get notified about the error (until you check RavenDB server logs).
The mitigation strategy would include:- wrapping the fragile logic in a
try/catchif you can handle errors gracefully; - add a good test coverage to boost your confidence in the code;
- if the above is not enough, check the Data subscriptions mentioned below.
- wrapping the fragile logic in a
4. Many-to-many relationship (array of references)
Once you get a handle on one-to-many relationships in NoSQL, stepping up to many-to-many is trivial. The trick is in keeping an array of references on either side.
Consider our example with BacklogItem and User collections for maintaining a list of users who modified backlog items. There are two options:
Userhas an array of backlog items modified by the user;BacklogItemhas an array of users who’ve ever modified it.
Location of the array is determined by the most common direction of querying. For YABT, the second option suits better, as we more often present users in the context of backlog items than the other way around. This way the BacklogItem would have an array of user IDs like this:
{
"ModifiedBy": [
"users/1-A",
"users/3-A"
],
}
and an index
public class BacklogItems_ForList : AbstractIndexCreationTask<BacklogItem>
{
public BacklogItems_ForList()
{
Map = tickets =>
select new
{
...
ModifiedBy = ticket.ModifiedBy,
...
};
}
}
So we can query backlog items modified by a userId:
from b in session.Query<BacklogItems_ForList>
where b.ModifiedBy.Contains(userId)
select new { b.Id, b.Title }
Of course, there are many factors affecting the implementation. For example, YABT needs to sort backlog items by the date of modifications, so an array is not enough and we opted for a { ID: DateTime } dictionary. This case is described in a previous article – Power of Dynamic fields for indexing dictionaries and nested collections in RavenDB.
Data subscriptions (special case)
Perhaps this one falls out of the scope of managing relationships, but it’s remotely related to the topic. If you have
- a complex logic that needs to be executed on an event (e.g. on updating a record) and
- it can’t be described in a server-side JavaScript (needs to be processed on the client-side),
then Data subscriptions is your tool. They provide a way of queueing messages and processing them asynchronously on the client-side.
Examples of applying Data subscriptions vary a lot, e.g. a system distributed in many regions may require a cluster-wide transaction to apply a change.
But it’s a different story. If interested, check out this video – Using RavenDB as a queuing infrastructure.
That’s it.
Check out the full source code at our repository on GitHub – github.com/ravendb/samples-yabt that contains practical implementations of all the approaches discussed here. And let us know what do you think. Click the link below to read the next article in the series!
Read more articles in this series
Woah, already finished? 🤯
If you found the article interesting, don’t miss a chance to try our database solution – totally for free!


