
MongoDB and RavenDB are both NoSQL document databases, which means that they provide the flexibility to quickly adapt your solution to the constantly changing business environment. They are both known for their speed in development, scaling, and server performance.
However, some key differences have caused many RavenDB users to choose RavenDB after trying both. Some of these are described in our case study articles.
RavenDB is known for:
- Being more user-friendly to develop with and maintain
- Faster release cycles in response to changing business requirements
- Safer-by-default
- Easy to scale out and instant scale up to match changing traffic needs
- Highly responsive community of users and experts get you unstuck quickly
- Native automation tools for a more efficient, streamlined system
- Richer native feature set (less costly and buggy than 3rd party plugins)
- Low Total Cost of Ownership (TCO)
- Easier to integrate into existing systems
- Ideal base for microservices architecture for a clean, flexible complex system
- Fast, lightweight servers for embedding into applications in edge deployments
- Designed for fast loads and queries, which is what your customers feel
- Cloud-based managed infrastructure
MongoDB is known for:
- Sharding for humungous data sets
- Auto-scaling cloud hardware (RavenDB will release soon)
- Designed for fast writes
- Wider community
- Cloud-based managed infrastructure
- 3rd party plugin services market (can cause bugs, especially if not updated properly to version upgrades)
Security
A security breach typically costs millions of dollars to fix and it ruins users’ trust.

RavenDB is secure by default with industry-standard security in the cloud and only takes minutes to set up with our wizard in on-premise servers. Once secured, https encryption in transit is built in, and native encryption in storage requires a simple toggle while setting up a new database. Most security breaches are caused by human error that hackers know how to spot. If a RavenDB server is accidentally told to be exposed to the public internet without security set up, RavenDB blocks the operation and gives a serious warning. This means that exposing a server can only be done explicitly, significantly reducing human error. Additionally, RavenDB managed cloud allows you to specify which IPs can access the server and blocks any other attempts.
Setting up security in most MongoDB servers is more complicated and leaves more room for human error. Each year, about 100,000 MongoDB servers are breached.
Server downtime
MongoDB and RavenDB are both designed with high availability, so if a server crashes, another node will quickly take over its tasks. The difference is that RavenDB’s instant failover typically takes fewer than a couple of seconds, whereas MongoDB can take minutes. This instant failover is because RavenDB nodes in a database group are all configured as “primary” servers that take turns being responsible for modifying data.
Rakuten Kobo tested the downtime prevention of both data platforms and found that “RavenDB had zero downtime,” while MongoDB took under two minutes to get the client back online. Numerous case studies demonstrate RavenDB’s zero downtime.
Data integrity
RavenDB guarantees fast ACID (Atomicity, Consistency, Isolation, Durability) transactions by default, which provide a higher level of data consistency and integrity compared to MongoDB’s default eventual consistency model. MongoDB does have ACID functionality, but not by default, and it was not designed for this level of data integrity from the get-go, so there are costs.
Agility
Responding quickly to trends and customer feature requests is the key to staying ahead of the game. Both MongoDB and RavenDB are known for their developer agility in comparison to relational databases. Their data models match object-oriented programming in a way that reduces a lot of developer workload. This gives organizations much more flexibility to transform their product as the need arises.
Additionally, RavenDB has automatic indexing, which eliminates the need to anticipate every querying scenario and manually create an index for it, as is currently required in MongoDB.
RavenDB’s code testing environment is also more intuitive and is designed to use actual, current data for accurate integration testing. This leads to faster release cycles and fewer bugs in production.
Automation
To increase efficiency, many solutions automate certain tasks. Automation involves coding the clients to respond automatically to specific events. For example, in an industrial line: ‘If machine heat is over x degrees, slow the machine + initiate extra cooling system + notify technician.’ Automation enables immediate responses to conditions that the system designers define.
RavenDB has native automation tooling, both in Data Subscriptions and intelligent indexing. In Data Subscriptions, clients are defined with ongoing subscription queries to the server. If the subscription condition is met, the server will send the data to the client as a data event. Clients can be coded to respond automatically to various data events that they subscribe to. In the example above, the clients that run the machines, cooling systems, and the technical team dashboard would all get the event that a machine is starting to overheat and respond as programmed. Here is a case study about RavenDB in field devices for emergency responders.
Another RavenDB feature that improves automation is that Static Indexes can be programmed to run various computations on data incrementally as it changes in the server. These computations can be as simple as calculating averages for a real-time dashboard, or as complex as computing machine learning/artificial intelligence models on data incrementally as it comes in, so that queries don’t have to do the computations. This approach of doing the computations in the indexes streamlines ML/AI applications. The HitHorizons case study uses RavenDB’s static indexes to run computations in the background, even on heterogeneous data that comes from various sources.
MongoDB has various types of indexes, some of which can handle certain ML models, but they do not have native event sourcing features. There are 3rd party plugins that might be able to achieve automation, but they are vulnerable to bugginess upon version changes.
Performance
Application or website speed largely depends on the efficiency of your code and the latency of your database. Customers wait longer when the latency is high.
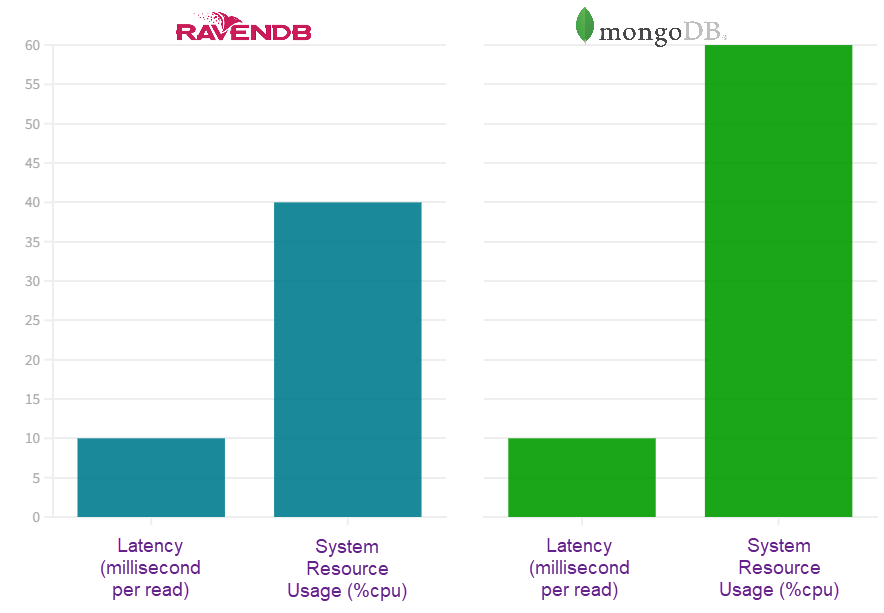
In Rakuten Kobo’s tests, MongoDB and RavenDB’s performance speed was equal, but RavenDB used 40% of the system’s resources while MongoDB used 60% to achieve the same performance. This translates to lower costs and energy usage.
IoT Bridge experienced much faster performance after switching from MongoDB to RavenDB.
Total Cost of Ownership (TCO)
Server costs are reduced thanks to the same features that improve performance (client-side caching, intelligent indexing, batching, lazy requests, advanced querying features). TCO is also reduced due to RavenDB’s low-maintenance Safe-By-Default design, billing model, server resource usage, and minimal need for costly 3rd party services. RavenDB is known as the data platform that pays for itself in savings.
Ease of use and integration into an existing system
RavenDB is known to be easier to use, largely due to its streamlined deployment and setup process, flexible schema, wealth of native features, auto-indexing, intuitive testing environment, safe-by-default approach to data security and data integrity, and its SQL-like query language.
RavenDB’s RQL language is so similar to SQL that many users prefer RavenDB for integration with an existing relational system. In most cases, they can use the same query code and logic that they already have, thus substantially reducing the translation work required.
RavenDB listens to and responds to its users, and has thus developed a rich set of native, tailor-made features that don’t require costly 3rd party plugins that are needed with MongoDB and most other data platforms. External plugins usually require more maintenance from DevOps teams than native features do. If needed, RavenDB has various ETL processes and other means of external integration.
Finally, RavenDB’s approach to testing code during each release cycle saves a lot of time and is extremely accurate, simplifying integration tests on a replica of your actual data system.
Scalability
Both MongoDB and RavenDB offer quick options to grow your data infrastructure by scaling vertically and horizontally. On the cloud, doing so is much faster than on-premises because the cloud platforms house and maintain the hardware, which is ready and waiting for scaling. Setting up new servers or new clusters on another continent can be done in a few minutes. Scale up to stronger hardware with a few clicks on the cloud, which is useful when anticipating floods of traffic, such as before Black Friday. These instances can be scaled down quickly when traffic dies down. MongoDB Atlas cloud service offers this type of vertical scaling automatically, which RavenDB plans to offer soon.
Scaling on-premise servers means buying hardware. Once you have the hardware, it takes a few minutes in RavenDB’s Setup Wizard to set up industry-standard security and a few minutes more in the UI Studio to connect it to each Database Group cluster for high availability. At that point, you can adjust your read-balance behavior so that your clients can query different replicated nodes to distribute the workload. MongoDB has no security setup wizard, so it will take longer.
Sharding is available in RavenDB 6.0, which includes high availability. Clients do not need to be set to route requests because RavenDB sharded databases handle routing and indexing across shards. MongoDB has offered sharding with high availability since v3.6.
Indexing
Efficient indexing is the key to fast queries in NoSQL databases. Indexing gives structure to unstructured data. Using unstructured data efficiently is why release cycles are so much faster in document databases. Indexing tremendously simplifies working with heterogeneous data from various sources.
RavenDB’s highly optimized indexing system allows for faster and more efficient data querying. RavenDB indexing has built-in auto-indexes that self-optimize according to usage and delete themselves if not used. RavenDB also has manually written Static Indexes where developers can code various computations done on data behind the scenes as it changes so that queries don’t have to do this work during each query. These computations can range from simple calculations to advanced machine-learning models. RavenDB has native map-reduce indexes as well.
Indexing happens incrementally on new data as it enters or is modified in the server, then the data is processed and ready for faster queries. Queries, on the other hand, do everything repeatedly. Defining queries to do all of the computations on the data repeatedly is far less efficient than having indexes do it on the data once and then incrementally on data modifications. For time and cost savings, query the index for relevant and pre-processed data.

MongoDB also has indexing capabilities, but it is not as advanced as RavenDB’s. They have an index Performance Advisor, which suggests indexes based on queries. As of today, MongoDB documentation does not mention auto-indexing, though they are planning on adding it in the future. Without it, developers must manually write indexes for every query situation. Any queries on a large dataset that don’t use an index will take a long time to return results and can be very costly.
Distribution models
Distribution models affect data sharing efficiency in a system and can impact its resiliency during server downtimes. RavenDB and MongoDB have different distribution models, with RavenDB using a multi-primary model, which provides instant failover during a server crash, while MongoDB uses a primary/secondary model that takes a short while to failover.
Both offer similar replication functionality. MongoDB offers sharding, and RavenDB is set to release sharding in v6.0. Sharding is recommended for huge datasets (>1TB) because it has an additional routing step for clients to read/write data to the appropriate shard. This extra step reduces speed. Both databases can have a mixture of sharded and unsharded databases.
RavenDB is well-suited for microservices architecture, with its native event-sourcing feature called Data Subscriptions, while MongoDB requires third-party services for similar functionality.
RavenDB is also fully equipped for fast, lightweight edge deployments. It has filtered Hub-Sink replication to configure ongoing replication patterns between your servers. Another option is to run various JavaScript computations on data before transferring it between servers via RavenDB’s native ongoing ETL offerings.
Saving and loading data from the server
RavenDB has developed “blittable” storage that can store JSON files as is, with no need to deserialize during loads. MongoDB stores JSON-like files called BSON, which are not human-readable but are closer to machine code. Thus, BSON is easier for servers to store but requires deserialization during loads and queries. The extra step of deserialization takes time. RavenDB makes a design choice to make reads and queries faster by not requiring deserialization during reads. Essentially, MongoDB has chosen faster write performance, whereas RavenDB makes reads faster.
One of the significant ways that RavenDB accelerates saves and loads is that it batches ACID operations together. It’s like filling a bag of groceries and taking them home together instead of running back and forth to the store for each item. RavenDB further expediates queries by ensuring that queries use indexes instead of full scans. Finally, its default client-side caching checks to make sure that the data cached on the client is current.
MongoDB vs RavenDB at a Glance:
| Category | RavenDB | MongoDB |
| Ease of Use | User-friendly, streamlined setup, flexible schema, SQL-like RQL language, intuitive testing environment, rich native features | More complex setup, requires 3rd-party plugins for many features, higher maintenance overhead |
| Security | Secure by default; HTTPS and encryption in storage are built-in; blocks accidental public exposure; IP whitelisting in managed cloud | Security setup is manual and error-prone; ~100,000 breaches per year reported |
| Downtime / Failover | Multi-primary model with instant failover (seconds); proven zero downtime in case studies (Rakuten Kobo, others) | Primary/secondary model; failover can take minutes |
| Data Integrity | Fast ACID transactions by default | Eventual consistency by default; ACID available but slower and costlier |
| Performance | Equal speed with 40% less system resources; designed for fast reads and queries; lightweight for edge deployments | Equal speed but uses ~60% of resources; designed for fast writes |
| Automation | Native automation: Data Subscriptions, intelligent & static indexes, built-in event sourcing for ML/AI and IoT | Limited; no native event sourcing; 3rd-party plugins required (can break on upgrades) |
| Indexing | Auto-indexes that self-optimize and delete when unused; supports Static, Map-Reduce, and incremental computations | No auto-indexing; indexes must be manually written; index Performance Advisor suggests indexes |
| Scalability | Easy vertical & horizontal scaling; sharding in v6.0; fast cloud/on-premise setup with security wizard; strong for microservices | Vertical & horizontal scaling; automatic scaling in MongoDB Atlas; sharding since v3.6 |
| Distribution Model | Multi-primary replication; better suited for microservices; supports hub-sink replication and native ETL for data distribution | Primary/secondary replication; requires routing in sharded setups; 3rd-party tools for event sourcing |
| Storage & Queries | “Blittable” JSON storage (no deserialization needed) → faster reads & queries; client-side caching; batched ACID ops | BSON storage (needs deserialization) → faster writes, slower reads |
| Agility | Automatic indexing and intuitive testing environment; faster release cycles | Manual index management; less flexible testing |
| Community & Ecosystem | Smaller but highly responsive community | Larger global community; bigger plugin/services market |
| Cloud | Managed cloud with built-in security & scaling; IP access control | MongoDB Atlas: managed cloud with auto-scaling |
| Total Cost of Ownership (TCO) | Lower TCO: fewer 3rd-party services, safe-by-default design, efficient resource usage | Higher TCO due to reliance on 3rd-party plugins, more DevOps overhead |
Woah, already finished? 🤯
If you found the article interesting, don’t miss a chance to try our database solution – totally for free!


