 Skip to Navigation
Skip to Navigation
Replication: How client integrates with replication bundle?
RavenDB's Client API is aware of the replication mechanism offered by the server instances and is ready to support failover scenarios.
Failover behavior
By default the client will detect and respond appropriately whenever a server has the replication bundle enabled. This includes:
- Detecting that an instance is replicating to another set of instances.
- When that instance is down, the client will be automatically shifted to other instances.
This is caused by a failover mechanism which is turned in a document stored by default. The clinet can load a replication document from /replication/topology to learn what replication instances to use if the failover occurred.
Note
The client by default creates requests for the replication document even if the server does not have the replication bundle enabled. In this case, the request for /replication/topology results in 404 in server logs.
You can turn off the failover behavior by using the document store conventions. In order to do so, use FailImmediately option:
store.getConventions().setFailoverBehavior(FailoverBehaviorSet.of(FailoverBehavior.FAIL_IMMEDIATELY));When FailImmediately option is used then client will raise exception when primary server is down.
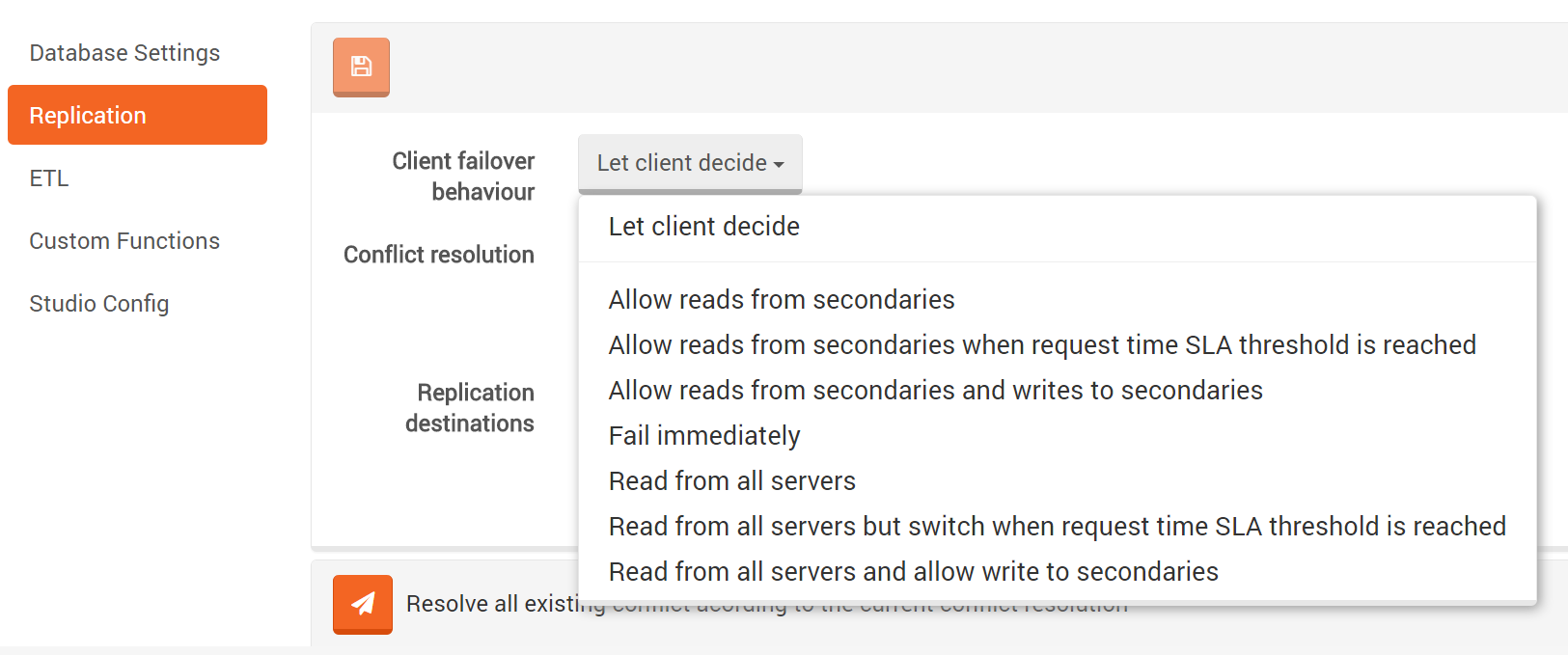
The remaining values of FailoverBehavior enumeration are:
- AllowReadsFromSecondaries (default) - allow to read from secondary server(s), but immediately fail writes to the secondary server(s)
- AllowReadsFromSecondariesAndWritesToSecondaries - allow reads from and writes to secondary server(s)
- ReadFromAllServers - spread read requests across all servers, instead of doing all the work against master. Write requests will always go to master
They determine the strategy of the failovers if the primary server is down and the environment is configured to replicate between sibling instances.
Mixing
FailoverBehavior enumeration values are actually flags and can be combined, e.g. to spread all reads across all servers and allow writes to secondaries one can do as follows:
store.getConventions().setFailoverBehavior(
FailoverBehaviorSet.of(
FailoverBehavior.READ_FROM_ALL_SERVERS,
FailoverBehavior.ALLOW_READS_FROM_SECONDARIES_AND_WRITES_TO_SECONDARIES));
Discovering destinations
Once the document store is configured to support failovers, the replication configuration of the database is checked. A list of replicated nodes is then retrieved and saved in the local application storage. Even if it is impossible to reach the primary server in the future, the list will still exist locally, and the document store can try to work with secondary instances, according to the conventions.
Changes in the server's replication configuration are monitored by the Client API as well. It is done regularly, every 5 minutes, to check if the documents are directed to current instances that are slaves to the primary server, in case a failover occurs.
Failover servers
If the client cannot reach the primary server and does not have a list of servers, nor is such list available in the local cache, the client will attempt to load and use manually configured failover servers. List of those servers can be configured with FailoverServers property in DocumentStore or .NET named connection strings.
Setup
store.setFailoverServers(new FailoverServers());
ReplicationDestination destination1 = new ReplicationDestination();
destination1.setUrl("http://localhost:8078");
destination1.setApiKey("apikey");
ReplicationDestination destination2 = new ReplicationDestination();
destination2.setUrl("http://localhost:8077");
destination2.setDatabase("test");
destination2.setUsername("user");
destination2.setPassword("secret");
store.getFailoverServers().addForDefaultDatabase(destination1, destination2);
ReplicationDestination northwindDestination = new ReplicationDestination();
northwindDestination.setUrl("http://localhost:8076");
store.getFailoverServers().addForDatabase("Northwind", northwindDestination);Setup using connection string
To setup failover using a connection string use Failover option. Multiple failovers can be setup using multiple Failover options.
- Failover
- Type: string in predefined format
- Format: JSON that can be deserialized to ReplicationDestination with optional database name separated with JSON using pipe ('|') e.g.
Northwind|{ ... }
Failover server definition.
Example:
Url = http://localhost:59233;
// Primary server url
Failover = { Url:'http://localhost:8078'};
// Failover for DefaultDatabase
Failover = { Url:'http://localhost:8077/', Database:'test'};
// Failover for DefaultDatabase with non-default database
Failover = Northwind|{ Url:'http://localhost:8076/'};
// Failover for 'Northwind' database
Failover= { Url:'http://localhost:8075', Username:'user', Password:'secret'};
// Failover for DefaultDatabase with Username and Password
Failover= { Url:'http://localhost:8074', ApiKey:'d5723e19-92ad-4531-adad-8611e6e05c8a'}
// Failover for DefaultDatabase with ApiKey
Setting up default client configuration on server
Default client configuration can be 'injected' into client, by filling out ClientConfiguration property in Raven/Replication/Destinations.
The available options are:
FailoverBehavior- default failover behavior for all clients that are connecting to a database.
Default configuration can be altered by The Studio as well. Appropriate settings are available in Settings -> Replication.
Request redirection
The Raven Client API is quite intelligent in this regard, as upon failure it will:
- Assume that the failure is transient, and retry the request,
- If the second attempt fails as well, will record the failure and shift to a replicated node, if available,
-
After ten consecutive failures, Raven will start replicating to this node less often
- Once every 10 requests, until failure count reaches 100
- Once every 100 requests, until failure count reaches 1,000
- Once every 1,000 requests, when failure count is above 1,000
- On the first successful request, the failure count is reset.
If the second replicated node fails, the same logic applies to it as well, and we move to the third replicated node, and so on. If all nodes fail, an appropriate exception is thrown.
Back to primary
The client shifted to a replicated node will go back to its primary server as soon as it becomes reachable (irrespective of the failure count). In replication environment the nodes send heartbeat messages in order to notify destination instances that they are up again. Then the destination (which is the secondary server for our shifted client) will send a feedback message to the client and then try sending a request to the primary server again. If the operation is successful, the failure count will be reset and the communication will work normally.
Replicated operations
At a lower level, the following operations support replication:
- Get - single document and multi documents
- Put
- Delete
- Query
- Rollback
- Commit
The following operations do not support replication in the Client API:
- PutIndex
- DeleteIndex
Custom document ID generation
The usage of replication doesn't influence the algorithm of a document ID generation
However in a Master/Master replication scenario it might be useful to add a server specific prefix to generated document identifiers. This would help to protect
against conflicts of document IDs between the replicating servers. In order to set up the server's prefix you have to put Raven/ServerPrefixForHilo:
store
.DatabaseCommands
.Put(
verPrefixForHilo",
null,
Object
{
Prefix", "NorthServer/" }
},
Object());The ServerPrefix value will be fetch in the same request as the current HiLo and will also become of a part of generated document IDs.
For example storing a first User object will cause that its ID will be Users/NorthServer/1.