 Skip to Navigation
Skip to Navigation
Document Structure Design Considerations
While Raven is a schema-free data store, that doesn't mean that you shouldn't take some time to consider how to design your documents to ensure that you can access all the data that you need to serve user requests efficiently, reliably and with as little maintainability cost as possible.
The most typical error people make when trying to design the data model on top of a document database is to try to model it the same way you would on top of a relational database.
Raven is a non-relational data store. Trying to hammer a relational model on top of it will produce sub-optimal results. But you can get fantastic results by taking advantage of the documented oriented nature of Raven.
Documents are not flat
Documents, unlike a row in a RDBMS, are not flat. You are not limited to just storing keys and values. Instead, you can store complex object graphs as a single document. That includes arrays, dictionaries and trees. Unlike a relational database, where a row can only contain simple values and more complex data structures need to be stored as relations, you don't need to work hard to get your data into Raven.
Let us take the following page as an example:

In a relational database, we would have to touch no less than 4 tables to show the data in this single page (Posts, Comments, Tags, RelatedPosts).
Using Raven, we can store all the data that we need to work with as a single document with the following format:

This format allows us to get everything that we need to display the page shown above in a single request.
Raven is not relational
When starting out with Raven, people will have problems when they attempt to use relational concepts. The major issue with that is, of course, that Raven is non-relational. However, it's actually more than that; there is a reason why Raven is non-relational.
Raven treats each document as an independent entity. By doing so, it is able to optimize the way documents are stored and managed. Moreover, one of the sweet spots that we see for Raven is for storing large amounts of data (too much data to store on a single machine).
Raven supports sharding out of the box, so there is no need to store a group of related documents together. Each document is independent and can be stored on any shard in the system.
Another aspect of the non-relational nature of Raven is that documents are expected to be meaningful on their own. You can certainly store references to other documents, but if you need to refer to another document to understand what the current document means, you are probably using Raven incorrectly.
With Raven, you are encouraged to include all of the information you need in a single document. Take a look at the post example above. In a relational database, we would have a link table for RelatedPosts, which would contain just the ids of the linked posts. If we wanted to get the titles of the related posts, we would need to join to the Posts table again. You can do that in Raven, but that isn't the recommended approach. Instead, as shown in the example above, you should include all of the details that you need inside the document. Using this approach, you can display the page with just a single request, leading to much better overall performance.
Entities and Aggregates
When thinking about using Raven to persist entities, we need to consider the two previous points. The suggested approach is to follow the Aggregate pattern from the Domain Driven Design book. An Aggregate Root contains several entities and value types and controls all access to the objects contained in its boundaries. External references may only refer to the Aggregate Root, never to one of its child objects.
When you apply this sort of thinking to a document database, there is a natural and easy to follow correlation between an Aggregate Root (in DDD terms) and a document in Raven. An Aggregate Root, and all the objects that it holds, is a document in Raven.
This also neatly resolves a common problem with Aggregates: traversing the path through the Aggregate to the object we need for a specific operation is very expensive in terms of number of database calls. In Raven, loading the entire Aggregate is just a single call and hydrating a document to the full Aggregate Root object graph is a very cheap operation.
Changes to the Aggregate are also easier to control, when using RDMBS, it can be hard to ensure that concurrent requests won't violate business rules. The problem is that two separate requests may touch two different parts of the Aggregate, each of them is valid on its own, but together they result in an invalid state. This has led to the usage of coarse grained locks, which are hard to implement when using typical OR/Ms.
Since Raven treats the entire Aggregate as a single document, the problem simply doesn't exist. You can utilize Raven's optimistic concurrency support to determine if the Aggregate or any of its children has changed. You can then reload the modified Aggregate and retry the transaction.
Associations Management
Aggregate Roots may contain all of their children, but even Aggregates do not live in isolation. For example:
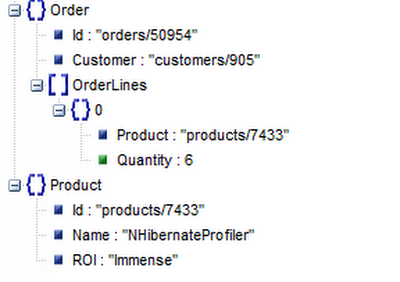
The Aggregate Root for an Order will contain Order Lines, but an Order Line will not contain a Product. Instead, it contains a reference to the product id.
The Raven Client API will not try to resolve such associations. This is intentional and by design. Instead, the expected usage is to hold the value of the associated document key and explicitly load the association if it is needed.
The reasoning behind this is simple: we want to make it just a tad harder to reference data in other documents. It is very common when using an OR/M to do something like: orderLine.Product.Name, which will load the Product entity. That makes sense when you are living in a relational world, but Raven is not relational. This deliberate omission from the Raven Client API is intended to remind users that they should model their Aggregates and Entities in a format that follows the recommended practice for Raven.