 Skip to Navigation
Skip to Navigation
Data Subscriptions
Data subscriptions provide a reliable and handy way to perform document processing on the client side.
The server sends batches of documents to the client.
The client then processes the batch and will receive the next one only after it acknowledges the batch was processed.
The server persists the processing progress, allowing you to pause and continue the processing.
In this page:
Data subscription consumption
What defines a data subscription
Documents processing
Progress Persistence
How the worker communicates with the server
Working with multiple clients
Data subscriptions usage example
Data subscription consumption
Data subscriptions are consumed by clients, called subscription workers. In any given moment, only one worker can be connected to a data subscription. A worker connected to a data subscription receives a batch of documents and gets to process it. When it's done, depending on the code that the client gave the worker, it can take from seconds to hours. It informs the server about the progress, and the server is ready to send the next batch.
What defines a data subscription
Data subscriptions are defined by the server side definition and by the worker connecting to it:
-
Subscription Creation Options: The documents that will be received, it's filtering and projection.
-
Subscription Worker Options: Worker batch processing logic, batch size, interaction with other connections.
Documents processing
Documents are sent in batches and progress will be registered only after the whole batch is processed and acknowledged. Documents are always sent in Etag order which means that data that already been processed and acknowledged won't be sent twice, except for the following scenarios:
-
If the document was changed after it was already sent.
-
If data was received but not acknowledged.
-
In case of subscription failover (
Enterprise feature), when there is a chance that documents will be processed again, because it's not always possible to find the same starting point on a different machine.
If the database has Revisions defined, the subscription can be configured to process pairs
of subsequent document revisions.
Read more here: revisions support
Progress Persistence
Processing progress is persisted and therefore it can be paused and resumed from the last point it was stopped.
The persistence mechanism also ensures that no documents are missed even in the presence of failure, whether it's client side related, communication, or any other disaster.
Subscriptions progress is stored in the cluster level, in the Enterprise edition. In the case of node failure, the processing can be automatically failed over to another node.
The usage of Change Vectors allows us to continue from a point that is close to the last point reached before failure rather than starting the process from scratch.
How the worker communicates with the server
A worker communicates with the data subscription using a custom protocol on top of a long-lived TCP connection. Each successful batch processing consists of these stages:
-
The server sends documents a batch.
-
Worker sends acknowledgment message after it finishes processing the batch.
-
The server returns the client a notification that the acknowledgment persistence is done and it is ready to send the next batch.
Failover
When the responsible node handling the subscription is down, the subscription task can be manually reassigned to another node in the cluster.
With the Enterprise license the cluster will automatically reassign the work to another node.
The TCP connection is also used as the "state" of the worker process and as long as it's alive, the server will not allow other clients to consume the subscription. The TCP connection is kept alive and monitored using "heartbeat" messages. If it's found nonfunctional, the current batch progress will be restarted.
See the sequence diagram below that summarizes the lifetime of a subscription connection.
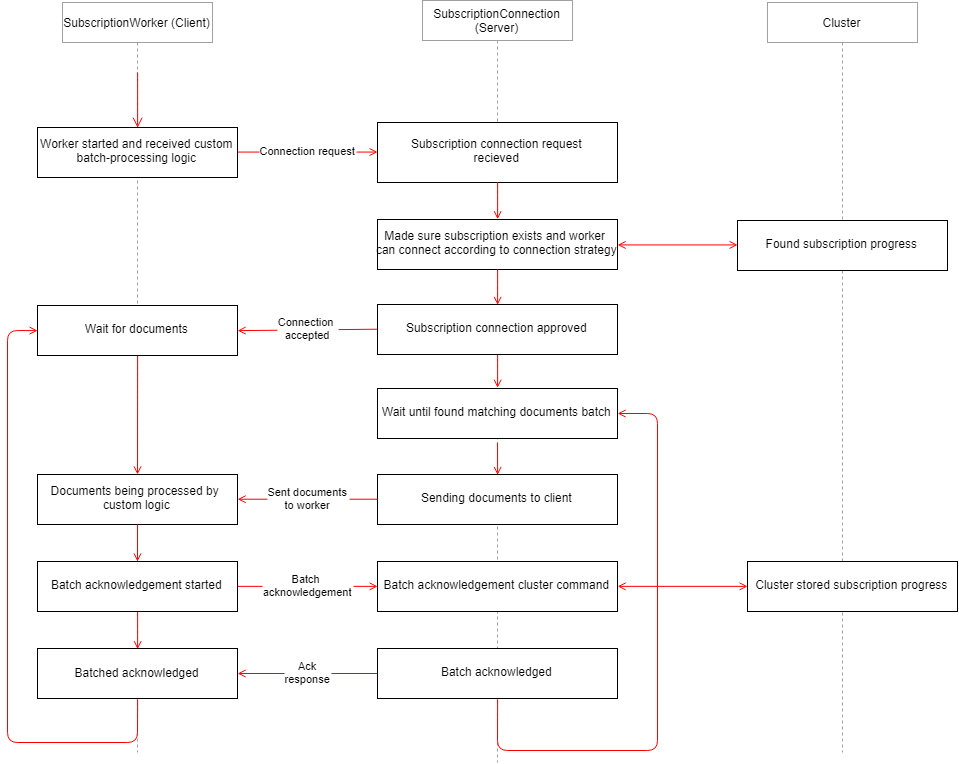
Working with multiple clients
In order to support various inter-worker scenarios, one worker is allowed to take the place of another in the processing of a subscription. Thanks to subscriptions persistence, the worker will be able to continue the work from the point it's predecessor stopped.
It's possible to configure that a worker will wait for an existing connection to fail, and take it's place, or we can configure it to force close an existing connection etc. See more in Workers interplay.
Data subscriptions usage example
Data subscriptions are accessible by a document store. Here's an example of an ad-hoc creation and usage of data subscriptions:
public async Task Worker(IDocumentStore store, CancellationToken cancellationToken)
{
string subscriptionName = await store.Subscriptions.CreateAsync<Order>(x => x.Company == "companies/11");
SubscriptionWorker<Order> subscription = store.Subscriptions.GetSubscriptionWorker<Order>(subscriptionName);
Task subscriptionTask = subscription.Run(x =>
x.Items.ForEach(item =>
Console.WriteLine($"Order #{item.Result.Id} will be shipped via: {item.Result.ShipVia}")),
cancellationToken);
await subscriptionTask;
}